📖《Spring Cloud 微服务权限系统搭建教程》一本基于Spring Cloud Hoxton.RELEASE&Spring Cloud Oauth2&Spring Cloud Alibaba的微服务权限系统搭建教程书籍,手把手教你从零到K8S集群部署。
]]>📖《Spring Cloud 微服务权限系统搭建教程》一本基于Spring Cloud Hoxton.RELEASE&Spring Cloud Oauth2&Spring Cloud Alibaba的微服务权限系统搭建教程书籍,手把手教你从零到K8S集群部署。
]]>我们知道,HashSet内部使用HashMap存储元素,所以HashSet遍历数据时是无序的,要保证插入的元素有序,我们可以使用LinkedHashSet。本节记录LinkedHashSet源码解析,基于JDK1.8。
LinkedHashSet类层级关系如下所示:
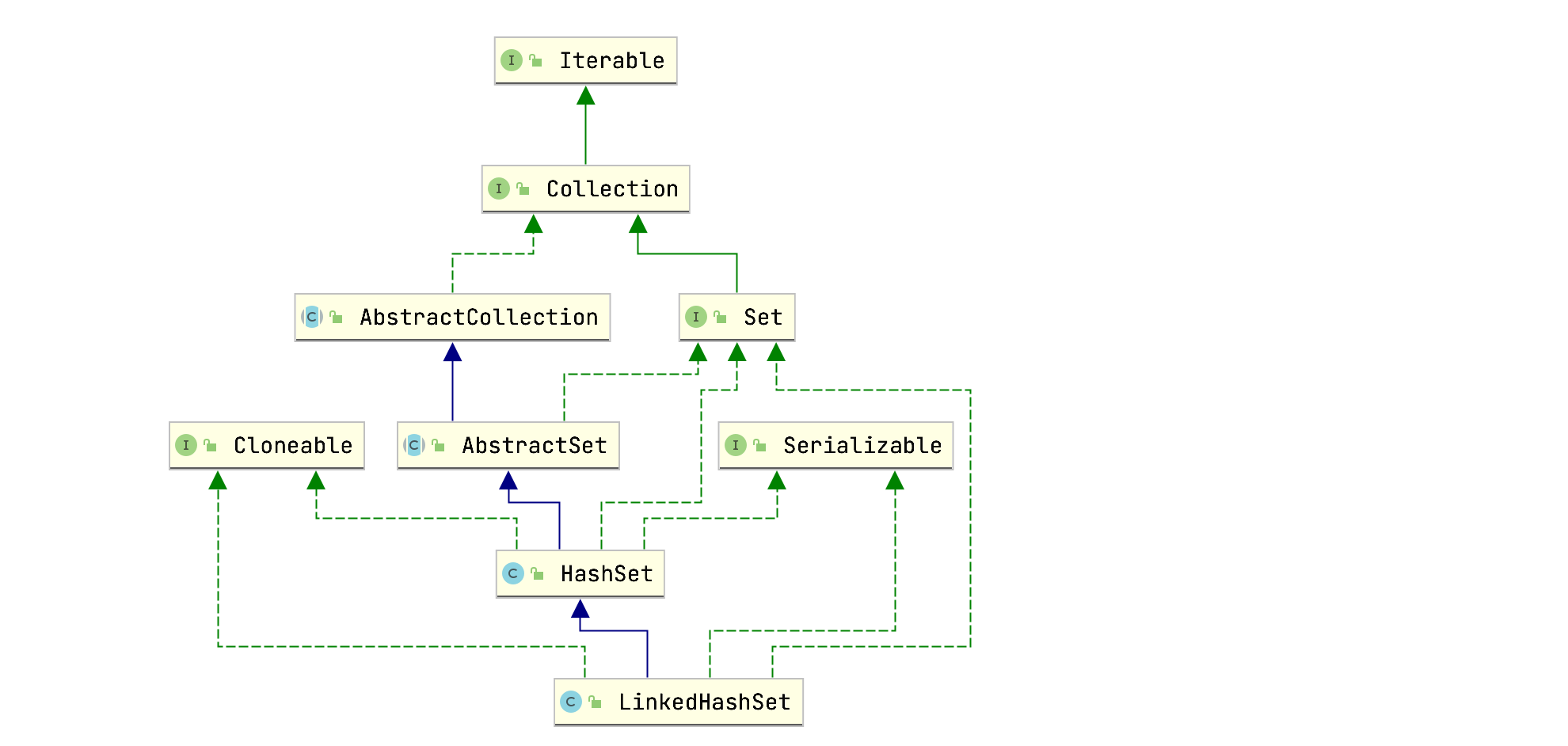
LinkedHashSet继承自HashSet。查看LinkedHashSet的构造方法源码会发现内部都是调用父类的HashSet(int initialCapacity, float loadFactor, boolean dummy)方法:
1 | HashSet(int initialCapacity, float loadFactor, boolean dummy) { |
dummy参数没有任何意义,仅用于和别的入参为(int,float)的构造器区分开。方法内部创建的是LinkedHashMap,所以LinkedHashSet就是用LinkedHashMap来保证插入元素有序的,对LinkedHashMap不熟悉的请参考LinkedHashMap源码解析。
从上面的代码我们还可以发现,LinkedHashSet无法改变linkedHashMap的accessOrder属性值,所以在LinkedHashSet中,元素的顺序只能和插入顺序一致:
1 | LinkedHashSet<String> set = new LinkedHashSet<>(); |
输出顺序和插入顺序一致:
1 | [apple, orange, watermelon, strawberry] |
HashMap元素插入是无序的,为了让遍历顺序和插入顺序一致,我们可以使用LinkedHashMap,其内部维护了一个双向链表来存储元素顺序,并且可以通过accessOrder属性控制遍顺序为插入顺序或者为访问顺序。本节将记录LinkedHashMap的内部实现原理,基于JDK1.8,并且用LinkedHashMap实现一个简单的LRU。
LinkedHashMap类层级关系图:
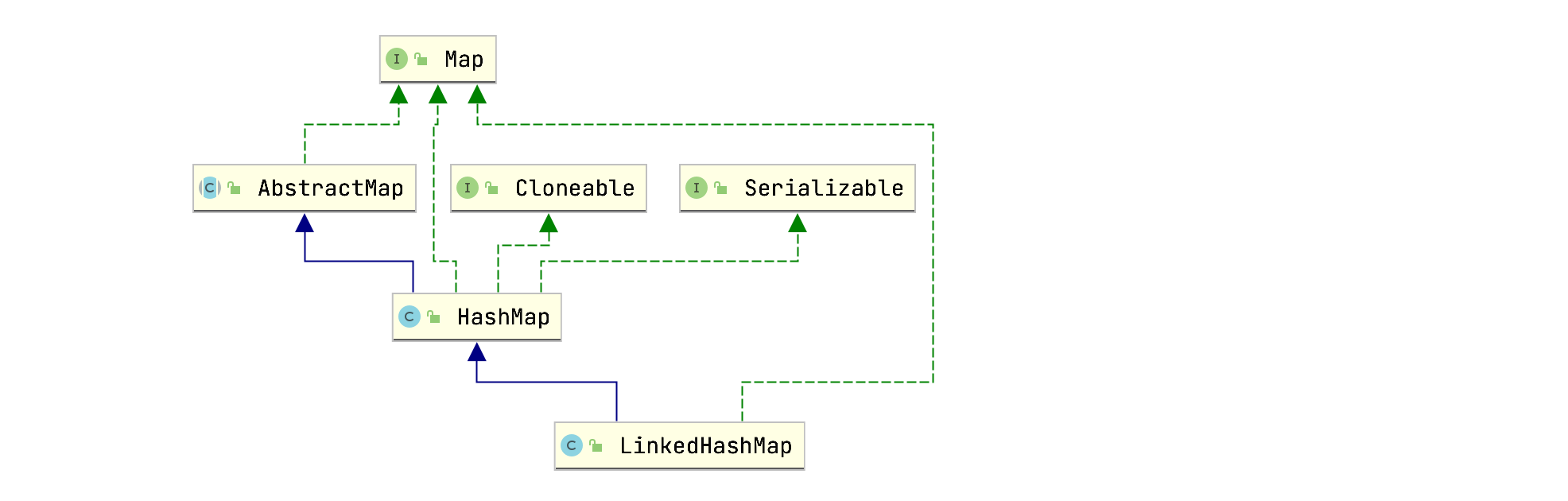
LinkedHashMap继承自HashMap,大部分方法都是直接使用HashMap的。接着查看成员变量:
1 | // 双向链表的头部节点(最早插入的,年纪最大的节点) |
head和tail使用transient修饰,原因在介绍HashMap源码的时候分析过。
LinkedHashMap继承自HashMap,所以内部存储数据的方式和HashMap一样,使用数组加链表(红黑树)的结构存储数据,LinkedHashMap和HashMap相比,额外的维护了一个双向链表,用于存储节点的顺序。这个双向链表的类型为LinkedHashMap.Entry:
1 | static class Entry<K,V> extends HashMap.Node<K,V> { |
LinkedHashMap.Entry类层级关系图:
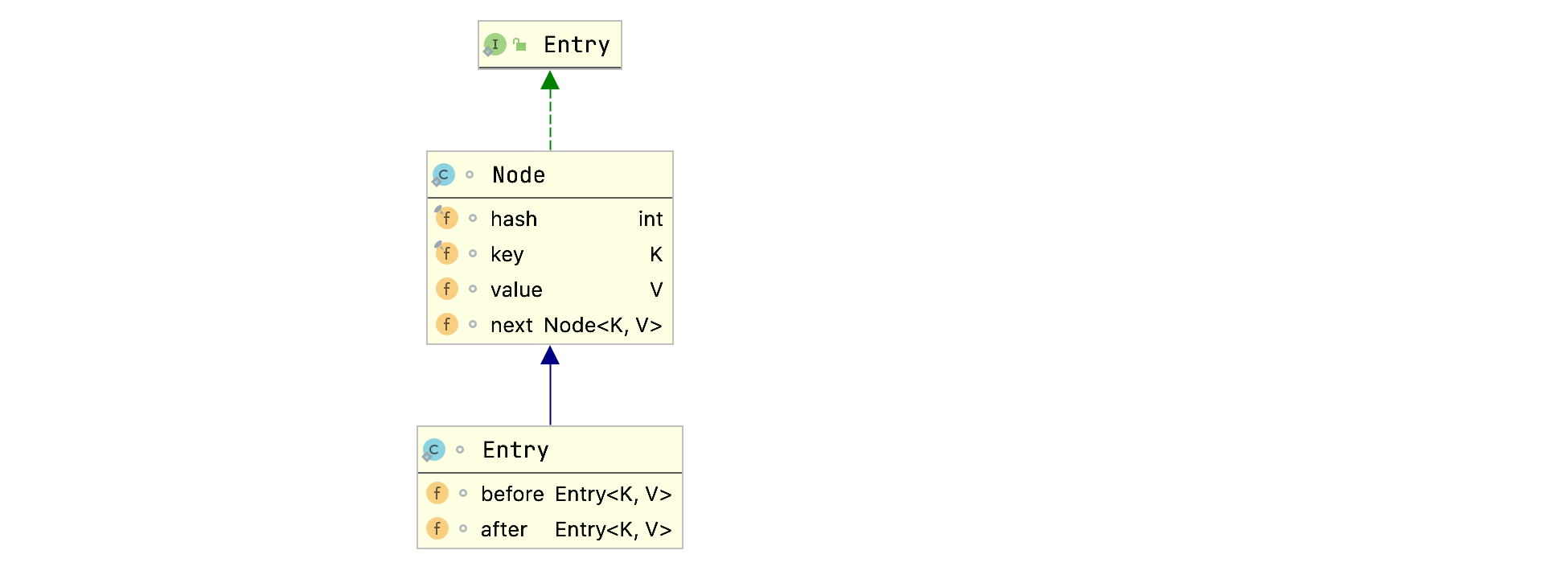
LinkedHashMap.Entry继承自HashMap的Node类,新增了before和after属性,用于维护前继和后继节点,以此形成双向链表。
LinkedHashMap的构造函数其实没什么特别的,就是调用父类的构造器初始化HashMap的过程,只不过额外多了初始化LinkedHashMap的accessOrder属性的操作:
1 | public LinkedHashMap(int initialCapacity, float loadFactor) { |
在分析LinkedHashMap方法实现之前,我们先通过例子感受下LinkedHashMap的特性:
1 | LinkedHashMap<String, Object> map = new LinkedHashMap<>(16, 0.75f, false); |
输出:
1 | {1=a, 6=b, 3=c} |
可以看到元素的输出顺序就是我们插入的顺序。
将accessOrder属性改为true:
1 | {1=a, 6=b, 3=c} |
可以看到,一开始输出{1=a, 6=b, 3=c}。当我们通过get方法访问key为6的键值对后,程序输出{1=a, 3=c, 6=b}。也就是说,当accessOrder属性为true时,元素按访问顺序排列,即最近访问的元素会被移动到双向列表的末尾。所谓的“访问”并不是只有get方法,符合“访问”一词的操作有put、putIfAbsent、get、getOrDefault、compute、computeIfAbsent、computeIfPresent和merge方法。
下面我们通过方法源码的分析就能清楚地知道LinkedHashMap是如何控制元素访问顺序的。
LinkedHashMap并没有重写put(K key, V value)方法,直接使用HashMap的put(K key, V value)方法。那么问题就来了,既然LinkedHashMap没有重写put(K key, V value),那它是如何通过内部的双向链表维护元素顺序的?我们查看put(K key, V value)方法源码就能发现原因(因为put(K key, V value)源码在Java-HashMap底层实现原理一节中已经剖析过,所以下面我们只在和LinkedHashMap功能相关的代码上添加注释):
1 | public V put(K key, V value) { |
newNode方法用于创建链表节点,LinkedHashMap重写了newNode方法:
1 | Node<K,V> newNode(int hash, K key, V value, Node<K,V> e) { |
可以看到,对于LinkedHashMap实例,put操作内部创建的的节点类型为LinkedHashMap.Entry,除了往HashMap内部table插入数据外,还往LinkedHashMap的双向链表尾部插入了数据。
如果是往红黑树结构插入数据,那么put将调用putTreeVal方法往红黑树里插入节点,putTreeVal方法内部通过newTreeNode方法创建树节点。LinkedHashMap重写了newTreeNode方法:
1 | TreeNode<K,V> newTreeNode(int hash, K key, V value, Node<K,V> next) { |
节点类型为TreeNode,那么这个类型是在哪里定义的呢?其实TreeNode为HashMap里定义的,查看其源码:
1 | static final class TreeNode<K,V> extends LinkedHashMap.Entry<K,V> { |
TreeNode继承自LinkedHashMap.Entry:

所以TreeNode也包含before和after属性,即使插入的节点类型为TreeNode,依旧可以用LinkedHashMap双向链表维护节点顺序。
在put方法中,如果插入的key已经存在的话,还会执行afterNodeAccess操作,该方法在HashMap中为空方法:
1 | void afterNodeAccess(Node<K,V> p) { } |
afterNodeAccess方法顾名思义,就是当节点被访问后执行某些操作。LinkedHashMap重写了这个方法:
1 | void afterNodeAccess(Node<K,V> e) { // move node to last |
所以当accessOrder为true时候,调用LinkedHashMap的put方法,插入相同key值的键值对时,该键值对会被移动到尾部:
1 | LinkedHashMap<String, Object> map = new LinkedHashMap<>(16, 0.75f, true); |
程序输出:
1 | {1=a, 6=b, 3=c} |
在put方法尾部,还调用了afterNodeInsertion方法,方法顾名思义,用于插入节点后执行某些操作,该方法在HashMap中也是空方法:
1 | void afterNodeInsertion(boolean evict) { } |
LinkedHashMap重写了该方法:
1 | // 这里evict为true |
基于这个特性,我们可以通过继承LinkedHashMap的方式重写removeEldestEntry方法,以此实现LRU,下面再做实现。
你可能会问,removeNode删除的是HashMap的table中的节点,那么用于维护节点顺序的双向链表不是也应该删除头部节点吗?为什么上面代码没有看到这部分操作?其实当你查看removeNode方法的源码就能看到这部分操作了:
1 | final Node<K,V> removeNode(int hash, Object key, Object value, |
afterNodeRemoval方法顾名思义,用于节点删除后执行后续操作。该方法在HashMap中为空方法:
1 | void afterNodeRemoval(Node<K,V> p) { } |
LinkedHashMap重写了该方法:
1 | // 改变节点的前继后继引用 |
通过该方法,我们就从LinkedHashMap的双向链表中删除了头部结点。
其实通过put方法我们就已经搞清楚了LinkedHashMap内部是如何通过双向链表维护键值对顺序的,但为了让文章更饱满一点,下面继续分析几个方法源码。
LinkedHashMap重写了HashMap的get方法:
1 | public V get(Object key) { |
LinkedHashMap没有重写remove方法,查看HashMap的remove方法:
1 | public V remove(Object key) { |
既然LinkedHashMap内部通过双向链表维护键值对顺序的话,那么我们可以猜测遍历LinkedHashMap实际就是遍历LinkedHashMap维护的双向链表:
查看LinkedHashMap类entrySet方法的实现:
1 | public Set<Map.Entry<K,V>> entrySet() { |
上述代码符合我们的猜测。
LRU(Least Recently Used)指的是最近最少使用,是一种缓存淘汰算法,哪个最近不怎么用了就淘汰掉。
我们知道LinkedHashMap内的removeEldestEntry方法固定返回false,并不会执行元素删除操作,所以我们可以通过继承LinkedHashMap,重写removeEldestEntry方法来实现LRU。
假如我们现在有如下需求:
用LinkedHashMap实现缓存,缓存最多只能存储5个元素,当元素个数超过5的时候,删除(淘汰)那些最近最少使用的数据,仅保存热点数据。
新建LRUCache类,继承LinkedHashMap:
1 | public class LRUCache<K, V> extends LinkedHashMap<K, V> { |
程序输出如下:
1 | {2=b, 3=c, 4=d, 5=e, 6=f} |
可以看到最早插入的1=a已经被删除了。
通过LinkedHashMap实现LRU还是挺常见的,比如logback框架的LRUMessageCache:
1 | class LRUMessageCache extends LinkedHashMap<String, Integer> { |
HashTable是Map接口线程安全实现版本,数据结构和方法实现与HashMap类似,本文记录HashTable源码解析,基于JDK1.8。
HashTable类层级关系图: 
主要成员变量:
1 | // 内部采用Entry数组存储键值对数据,Entry实际为单向链表的表头 |
table属性通过transient修饰,原因在介绍HashMap源码的时候分析过。
Entry代码如下:
1 | private static class Entry<K,V> implements Map.Entry<K,V> { |
Entry为单向链表节点,HashTable采用数组加链表的方式存储数据,不过没有类似于HashMap中当链表过长时转换为红黑树的操作。
1 | // 设置指定容量和加载因子,初始化HashTable |
put(K key, V value)添加指定键值对,键和值都不能为null:
1 | // 方法synchronized修饰,线程安全 |
rehash扩容操作:
1 | protected void rehash() { |
get(Object key)获取指定key对应的value:
1 | public synchronized V get(Object key) { |
synchronized修饰,线程安全。
remove(Object key)删除指定key,返回对应的value:
1 | public synchronized V remove(Object key) { |
synchronized修饰,线程安全。
剩下方法有兴趣自己阅读源码,public方法都用synchronized修饰,确保线程安全,并发环境下,多线程竞争对象锁,效率低,不推荐使用。线程安全的Map推荐使用ConcurrentHashMap。
线程是否安全:HashMap是线程不安全的,HashTable是线程安全的;HashTable内部的方法基本都经过 synchronized修饰;
对Null key 和Null value的支持:HashMap中,null可以作为键,这样的键只有一个,可以有一个或多个键所对应的值为null;HashTable中key和value都不能为null,否则抛出空指针异常;
初始容量大小和每次扩充容量大小的不同:
3.1. 创建时如果不指定容量初始值,Hashtable默认的初始大小为11,之后每次扩容,容量变为原来的2n+1。HashMap默认的初始化大小为16。之后每次扩充,容量变为原来的2倍;
3.2. 创建时如果给定了容量初始值,那么Hashtable会直接使用你给定的大小,而HashMap会将其扩充 为2的幂次方大小。
底层数据结构:JDK1.8及以后的HashMap在解决哈希冲突时有了较大的变化,当链表长度大于阈值(默认为 8)时,将链表转化为红黑树,以减少搜索时间,Hashtable没有这样的机制。
CopyOnWriteArraySet为线程安全的Set实现,本文记录CopyOnWriteArraySet源码解析,基于JDK1.8。
先来看下CopyOnWriteArraySet的类层级关系图:
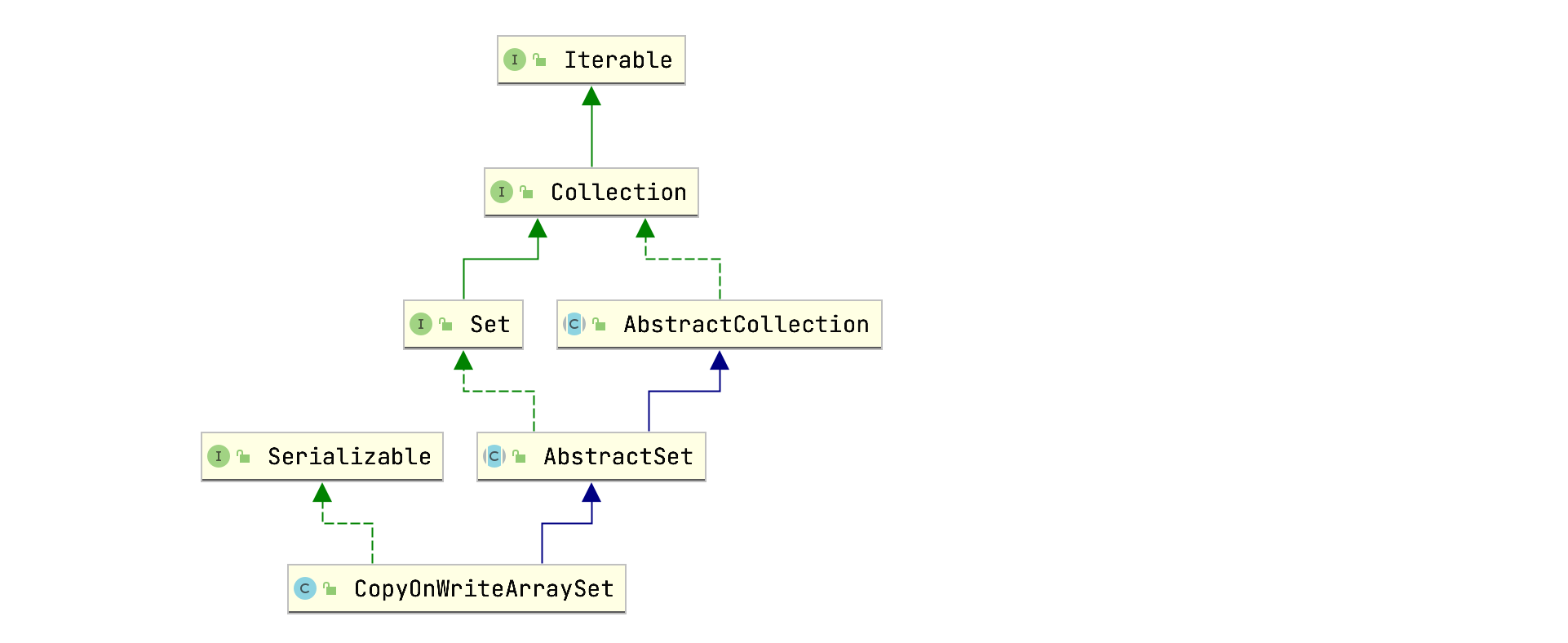
没什么好说的。再来看看内部属性:
1 | // 就一个属性,CopyOnWriteArraySet内部采用CopyOnWriteArrayList存储元素 |
和HashSet不一样的是,CopyOnWriteArraySet内部采用CopyOnWriteArrayList存储元素,这也是CopyOnWriteArraySet名字的由来,因为CopyOnWriteArrayList是线程安全的,CopyOnWriteArraySet的方法都是基于CopyOnWriteArrayList实现的,所以CopyOnWriteArraySet自然而然也是线程安全的,同样的,在并发环境下获取数据是弱一致性的!
1 | // 空参构造函数,实际就是初始化CopyOnWriteArrayList |
add(E e)添加指定元素:
1 | public boolean add(E e) { |
可以看到,CopyOnWriteArraySet的add方法通过调用CopyOnWriteArrayList的addIfAbsent来确保元素不重复,以满足Set的特性。
剩下方法都比较简单,都是直接调用CopyOnWriteArrayList方法实现,感兴趣自己阅读源码。
]]>HashSet类层级关系图:
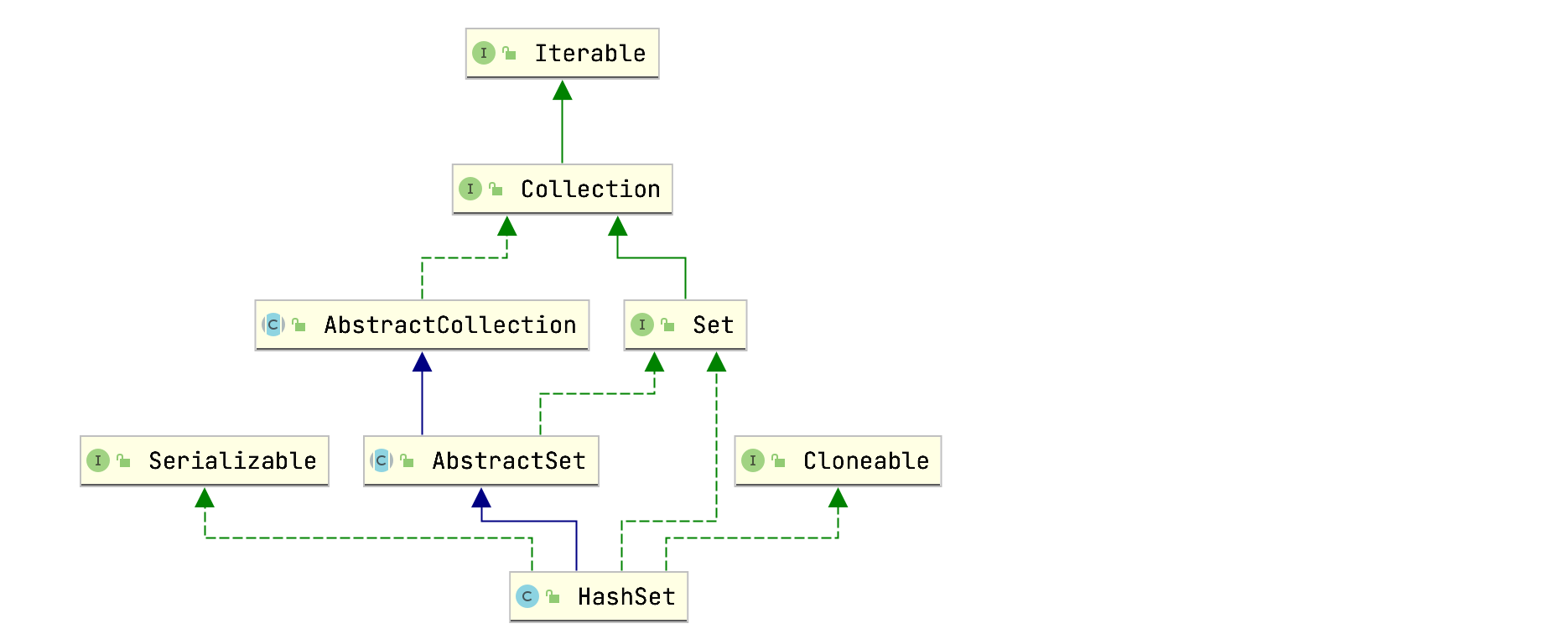
HashSet实现了Set接口,为什么叫HashSet?因为HashSet内部采用哈希表(实际就是HashMap)来存储不重复的数据,查看HashSet内部属性:
1 | // 使用HashMap存储数据,HashSet的数据实际为HashMap的key |
HashMap的key是不允许重复的,这也正好符合Set的特性。因为HashSet内部采用HashMap存储数据,所以HashSet可以存储null值,支持快速失败,非线程安全。
map属性通过transient修饰,原因在介绍HashMap源码的时候分析过。
1 | // 空参构造函数,内部初始化map属性 |
可以看到,创建HashSet的本质就是初始化HashMap。
add(E e)添加指定元素:
1 | public boolean add(E e) { |
contains(Object o)判断是否包含指定元素:
1 | public boolean contains(Object o) { |
size()获取元素个数:
1 | public int size() { |
isEmpty()判断集合是否为空:
1 | public boolean isEmpty() { |
remove(Object o)删除指定元素:
1 | public boolean remove(Object o) { |
clear()清空集合:
1 | public void clear() { |
iterator()获取迭代器:
1 | public Iterator<E> iterator() { |
CopyOnWriteArrayList为线程安全的ArrayList,这节分析下CopyOnWriteArrayList的源码,基于JDK1.8。
CopyOnWriteArrayList类关系图:
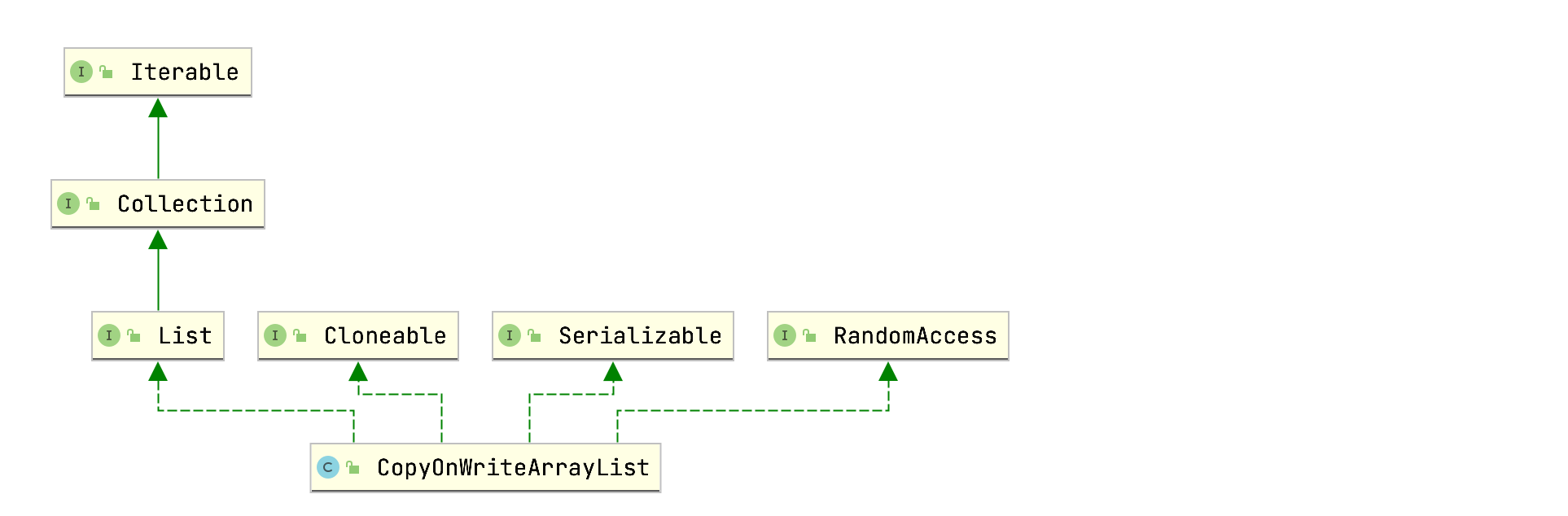
CopyOnWriteArrayList实现了List接口的所有方法,主要包含如下两个成员变量:
1 | // 可重入锁,用于对写操作加锁 |
CopyOnWriteArrayList中并没有和容量有关的属性或者常量,下面通过对一些常用方法的源码解析,就可以知道原因。
CopyOnWriteArrayList()空参构造函数:
1 | public CopyOnWriteArrayList() { |
无参构造函数直接创建了一个长度为0的Object数组。
CopyOnWriteArrayList(Collection<? extends E> c):
1 | public CopyOnWriteArrayList(Collection<? extends E> c) { |
CopyOnWriteArrayList(E[] toCopyIn):
1 | public CopyOnWriteArrayList(E[] toCopyIn) { |
add(E e)往CopyOnWriteArrayList末尾添加元素:
1 | public boolean add(E e) { |
可以看到,add操作通过ReentrantLock来确保线程安全。通过add方法,我们也可以看出CopyOnWriteArrayList修改操作的基本思想为:复制一份新的数组,新数组长度刚好能够容纳下需要添加的元素;在新数组里进行操作;最后将新数组赋值给array属性,替换旧数组。这种思想也称为“写时复制”,所以称为CopyOnWriteArrayList。
此外,我们可以看到CopyOnWriteArrayList中并没有类似于ArrayList的grow方法扩容的操作。
add(int index, E element)指定下标添加指定元素:
1 | public void add(int index, E element) { |
set(int index, E element)设置指定位置的值:
1 | public E set(int index, E element) { |
remove(int index)删除指定下标元素:
1 | public E remove(int index) { |
1 | public E get(int index) { |
可以看到,get(int index)操作是分两步进行的:
getArray()获取array属性值;这个过程并没有加锁,所以在并发环境下可能出现如下情况:
get(int index)方法获取值,内部通过getArray()方法获取到了array属性值;setArray方法修改了array属性的值;所以get方法是弱一致性的。
1 | public int size() { |
size()方法返回当前array属性长度,因为CopyOnWriteArrayList中的array数组每次复制都刚好能够容纳下所有元素,并不像ArrayList那样会预留一定的空间。所以CopyOnWriteArrayList中并没有size属性,元素的个数和数组的长度是相等的。
1 | public Iterator<E> iterator() { |
可以看到,迭代器也是弱一致性的,并没有在锁中进行。如果其他线程没有对CopyOnWriteArrayList进行增删改的操作,那么snapshot还是创建迭代器时获取的array,但是如果其他线程对CopyOnWriteArrayList进行了增删改的操作,旧的数组会被新的数组给替换掉,但是snapshot还是原来旧的数组的引用:
1 | CopyOnWriteArrayList<String> list = new CopyOnWriteArrayList<>(); |
输出结果仅为hello。
java.util.ConcurrentModificationException异常,并不能确保数据的强一致性;Vector和ArrayList非常相似,它们都实现了相同的接口,继承相同的类,就连方法的实现也非常类似。和ArrayList不同的是,Vector是线程安全的,关键方法上都加了synchronized同步锁,由于Vector效率不高,所以使用的较少,要使用线程安全的ArrayList,推荐CopyOnWriteArrayList,后续再做分析,这里仅记录下Vector源码,基于JDK1.8。
Vector的类关系图和ArrayList一致:
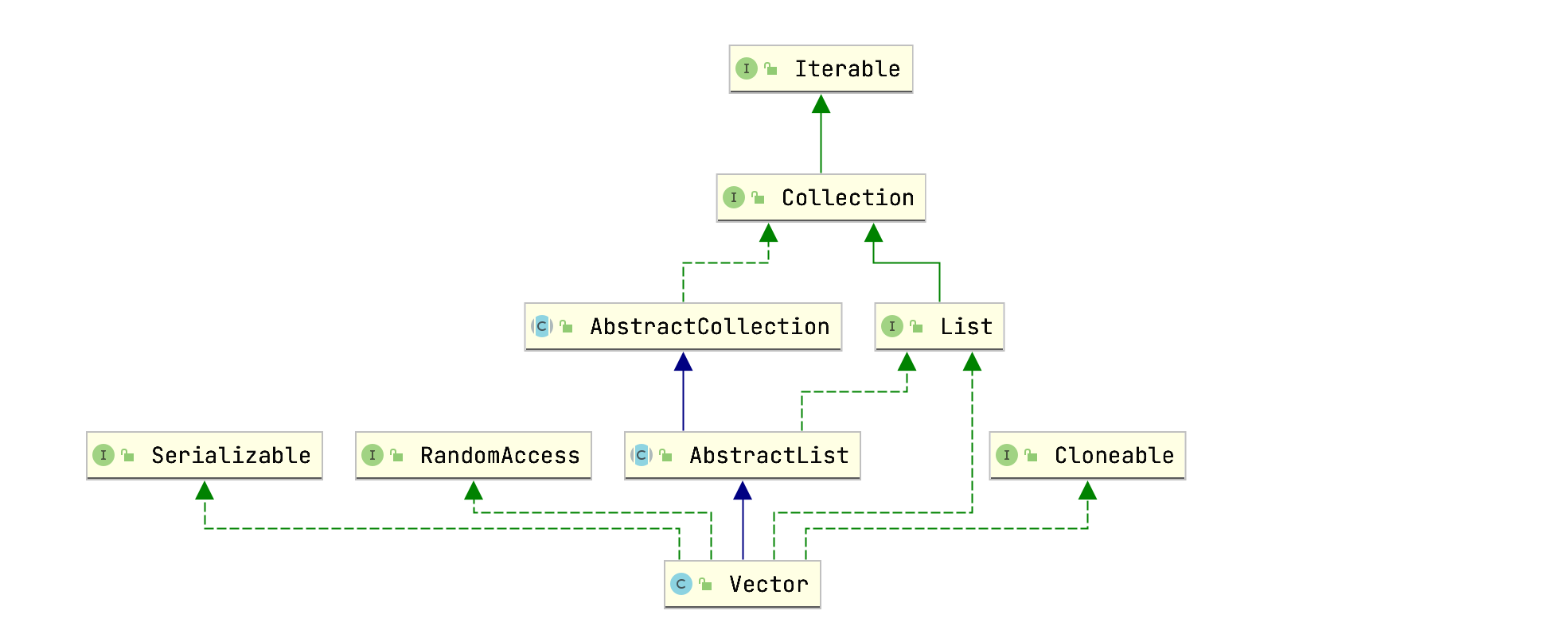
Vector可以存放任意类型元素(包括null),允许重复,和ArrayList一致,内部采用Object类型数组存放数据,包含以下三个成员变量:
1 | // Object数组,存放数据 |
1 | public Vector(int initialCapacity, int capacityIncrement) { |
可以看到,当我们调用new Vector()创建Vector集合时,直接创建了一个容量为10的Object数组(和ArrayList不同,ArrayList内部数组初始容量为0,只有在添加第一个元素的时候才扩容为10),并且capacityIncrement为0,意味着容量不足时,新数组容量为旧数组容量的2倍。
1 | public synchronized boolean add(E e) { |
添加逻辑和ArrayList的add方法大体一致,区别在于扩容策略有些不同,并且方法使用synchronized关键字修饰。
1 | public synchronized E set(int index, E element) { |
逻辑和ArrayList的set方法一致,方法使用synchronized关键字修饰。
1 | public synchronized E get(int index) { |
逻辑和ArrayList的get方法一致,方法使用synchronized关键字修饰。
1 | public synchronized E remove(int index) { |
逻辑和ArrayList的remove方法一致,方法使用synchronized关键字修饰。
1 | public synchronized void trimToSize() { |
逻辑和ArrayList的trimToSize方法一致,方法使用synchronized关键字修饰。
]]>剩下的方法源码自己查看,大体和ArrayList没有什么区别。Vector的方法都用synchronized关键字来确保线程安全,每次只有一个线程能访问此对象,在线程竞争激烈的情况下,这种方法效率非常低,所以实际并不推荐使用Vector。
本文记录ArrayList & LinkedList源码解析,基于JDK1.8。
ArrayList实现了List接口的所有方法,可以看成是“长度可调节的数组”,可以包含任何类型数据(包括null,可重复)。ArrayList大体和Vector一致,唯一区别是ArrayList非线程安全,Vector线程安全,但Vector线程安全的代价较大,推荐使用CopyOnWriteArrayList,后面文章再做记录。
ArrayList类层级关系如下图所示:
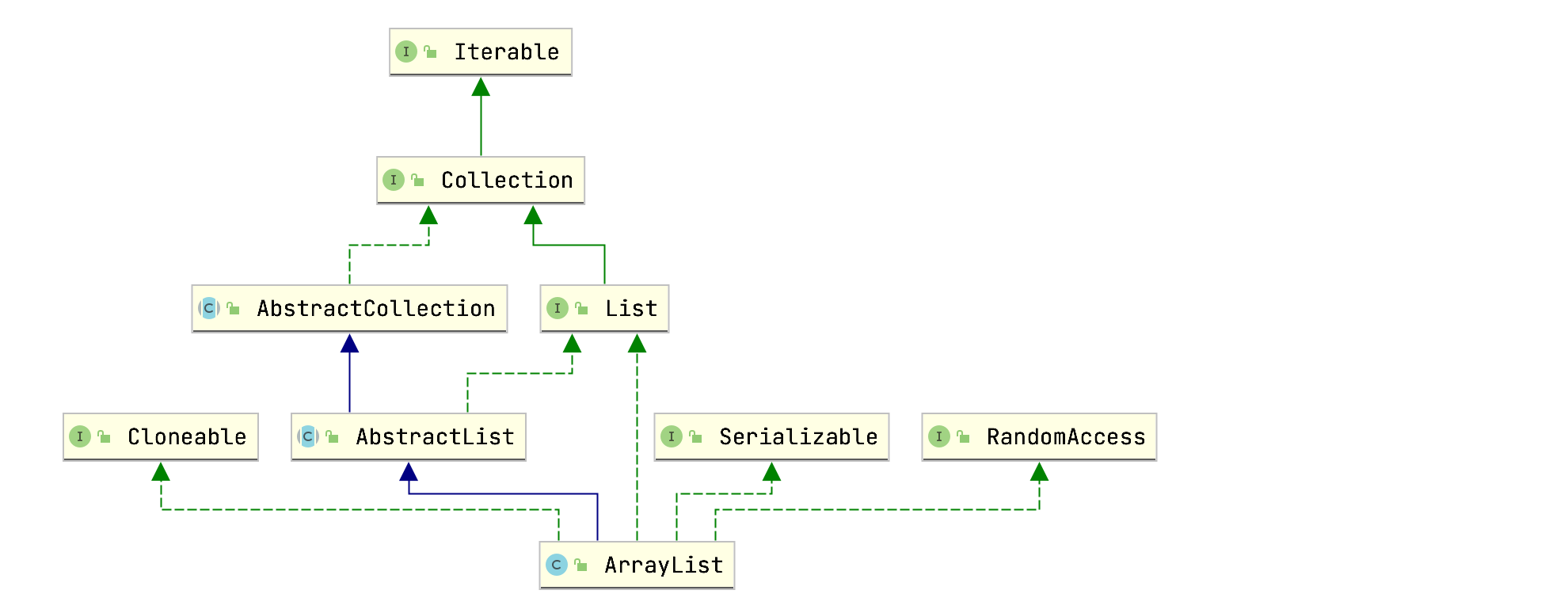
ArrayList额外实现了RandomAccess接口,关于RandomAccess接口的作用下面再做讨论。
ArrayList类主要包含如下两个成员变量:
1 | public class ArrayList<E> extends AbstractList<E> |
elementData为Object类型数组,用于存放ArrayList数据;size表示数组元素个数(并非数组容量)。
ArrayList类还包含了一些常量:
1 | public class ArrayList<E> extends AbstractList<E> |
Arrays类的copyOf(U[] original, int newLength, Class<? extends T[]> newType)方法用于复制指定数组original到新数组,新数组的长度为newLength,新数组元素类型为newType。
举两个例子:
1 | Long[] array1 = new Long[]{1L, 2L, 3L}; |
重载方法copyOf(T[] original, int newLength)用于复制指定数组original到新数组,新数组的长度为newLength,新数组元素类型和旧数组一致。
copyOf方法内部调用System类的native方法arraycopy(Object src, int srcPos,Object dest, int destPos, int length):
src:需要被拷贝的旧数组;srcPos:旧数组开始拷贝的起始位置;dest:拷贝目标数组;destPos:目标数组的起始拷贝位置;length:拷贝的长度。举例:
1 | Long[] array1 = new Long[]{1L, 2L, 3L}; |
指定位置插入元素:
1 | Long[] array1 = new Long[]{1L, 2L, 3L, null, null, null}; |
public ArrayList(int initialCapacity):
1 | public ArrayList(int initialCapacity) { |
创建容量大小为initialCapacity的ArrayList,如果initialCapacity小于0,则抛出IllegalArgumentException异常;如果initialCapacity为0,则elementData为EMPTY_ELEMENTDATA。
public ArrayList():
1 | public ArrayList() { |
空参构造函数,elementData为DEFAULTCAPACITY_EMPTY_ELEMENTDATA。
public ArrayList(Collection<? extends E> c):
1 | public ArrayList(Collection<? extends E> c) { |
创建一个包含指定集合c数据的ArrayList。上面为什么要多此一举使用Arrays.copyOf(elementData, size, Object[].class)复制一遍数组呢?这是因为在某些情况下调用集合的toArray()方法返回的类型并不是Object[].class,比如:
1 | Long[] array1 = {1L, 2L}; |
add(E e)用于尾部添加元素:
1 | public boolean add(E e) { |
假如现在我们通过如下代码创建了一个ArrayList实例:
1 | ArrayList<String> list = new ArrayList<>(); |
内部过程如下:
1 | public boolean add(E e) { |
通过上面源码分析我们可以知道:
add(int index, E element)用于在指定位置添加元素:
1 | public void add(int index, E element) { |
这里涉及到元素移动,所以速度较慢。
get(int index)获取指定位置元素:
1 | public E get(int index) { |
get方法直接返回数组指定下标元素,速度非常快。
set(int index, E element)设置指定位置元素为指定值:
1 | public E set(int index, E element) { |
set方法不涉及元素移动和遍历,所以速度快。
remove(int index)删除指定位置元素:
1 | public E remove(int index) { |
上述方法涉及到元素移动,所以效率也不高。
remove(Object o)删除指定元素:
1 | // 遍历数组,找到第一个目标元素,然后删除 |
方法涉及到数组遍历和元素移动,效率也不高。
trimToSize()源码:
1 | public void trimToSize() { |
该方法用于将数组容量调整为实际元素个数大小,当一个ArrayList元素个数不会发生改变时,可以调用该方法减少内存占用。
其他方法可以自己阅读ArrayList源码,此外在涉及增删改的方法里,我们都看到了modCount++操作,和之前介绍HashMap源码时一致,用于快速失败。
LinkedList底层采用双向链表结构存储数据,允许重复数据和null值,长度没有限制:
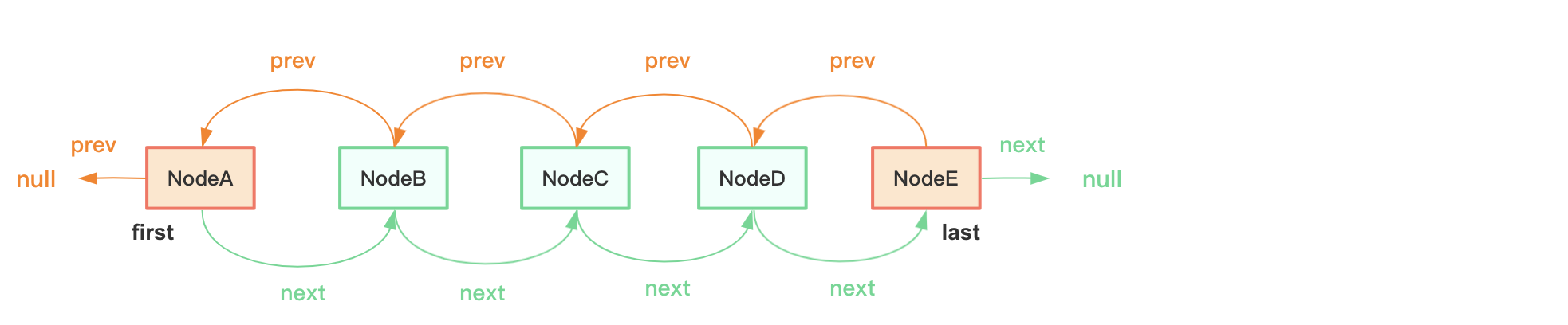
每个节点用内部类Node表示:
1 | private static class Node<E> { |
Node节点包含item(存储数据),next(后继节点)和prev(前继节点)。数组内存地址必须连续,而链表就没有这个限制了,Node可以分布于各个内存地址,它们之间的关系通过prev和next维护。
LinkedList类关系图:
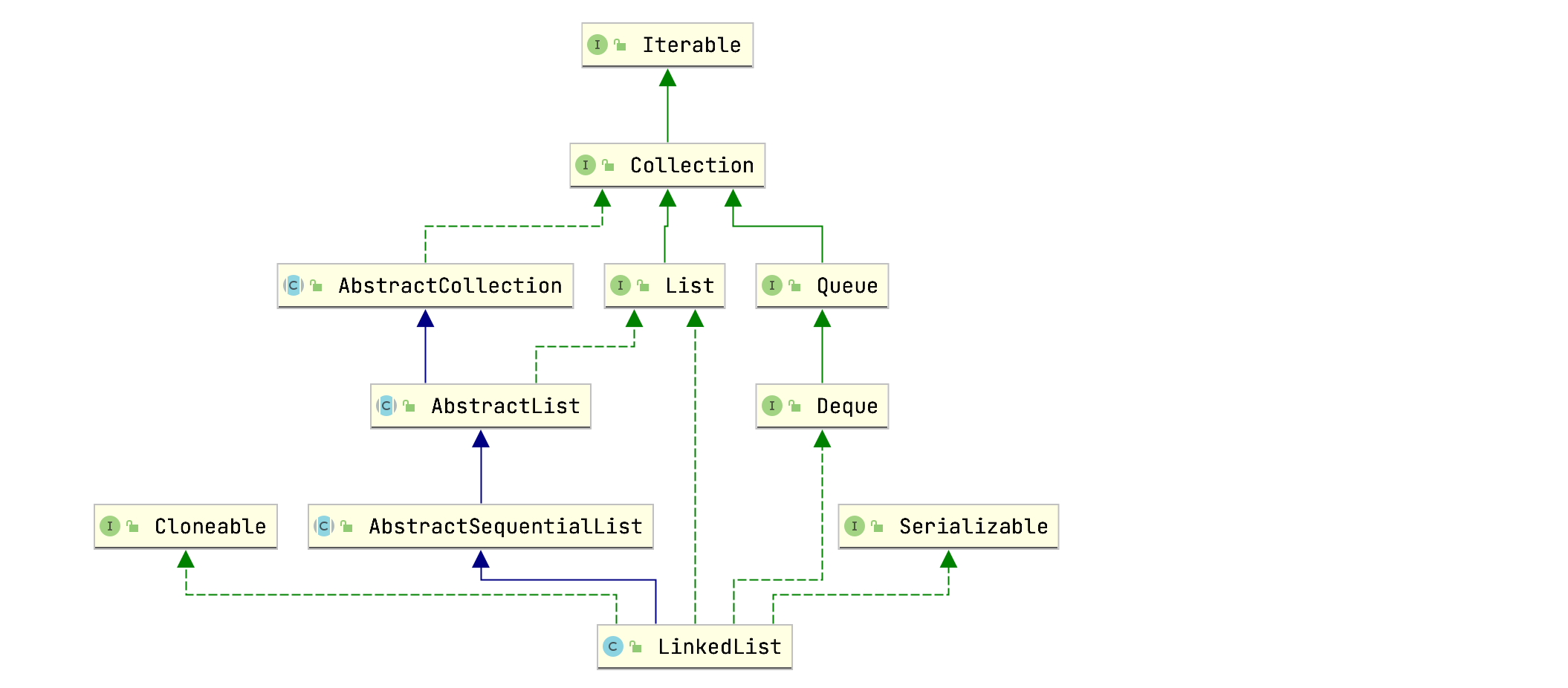
可以看到LinkedList类并没有实现RandomAccess接口,额外实现了Deque接口,所以包含一些队列方法。
LinkedList包含如下成员变量:
1 | // 元素个数,默认为0 |
LinkedList():
1 | public LinkedList() { |
空参构造函数,默认size为0,每次添加新元素都要创建Node节点。
LinkedList(Collection<? extends E> c):
1 | public LinkedList(Collection<? extends E> c) { |
该构造函数用于创建LinkedList,并往里添加指定集合元素。
add(int index, E element)指定下标插入元素:
1 | public void add(int index, E element) { |
代码较为简单,无非就是设置节点的prev和next关系。可以看到,除了头插和尾插外,在链表别的位置插入新节点,涉及到节点遍历操作,所以我们常说的链表插入速度快,指的是插入节点改变前后节点的引用过程很快。
get(int index)获取指定下标元素:
1 | public E get(int index) { |
代码较为简单,就是通过node函数查找指定index下标Node,然后获取其item属性值,节点查找需要遍历。
set(int index, E element)设置指定下标节点的item为指定值:
1 | public E set(int index, E element) { |
可以看到,set方法也需要通过遍历查找目标节点。
remove(int index)删除指定下标节点:
1 | public E remove(int index) { |
remove(int index)通过node方法找到需要删除的节点,然后调用unlink方法改变删除节点的prev和next节点的前继和后继节点。
剩下的方法可以自己阅读源码。
RandomAccess接口是一个空接口,不包含任何方法,只是作为一个标识:
1 | package java.util; |
实现该接口的类说明其支持快速随机访问,比如ArrayList实现了该接口,说明ArrayList支持快速随机访问。所谓快速随机访问指的是通过元素的下标即可快速获取元素对象,无需遍历,而LinkedList则没有这个特性,元素获取必须遍历链表。
在Collections类的binarySearch(List<? extends Comparable<? super T>> list, T key)方法中,可以看到RandomAccess的应用:
1 | public static <T> |
当list实现了RandomAccess接口时,调用indexedBinarySearch方法,否则调用iteratorBinarySearch。所以当我们遍历集合时,如果集合实现了RandomAccess接口,优先选择普通for循环,其次foreach;遍历未实现RandomAccess的接口,优先选择iterator遍历。
]]>所谓循环依赖指的是:BeanA对象的创建依赖于BeanB,BeanB对象的创建也依赖于BeanA,这就造成了死循环,如果不做处理的话势必会造成栈溢出。Spring通过提前曝光机制,利用三级缓存解决循环依赖问题。本节将记录单实例Bean的创建过程,并且仅记录两种常见的循环依赖情况:普通Bean与普通Bean之间的循环依赖,普通Bean与代理Bean之间的循环依赖。
我们先通过源码熟悉下Bean创建过程(源码仅贴出相关部分)。
IOC容器获取Bean的入口为AbstractBeanFactory类的getBean方法:
1 | public abstract class AbstractBeanFactory extends FactoryBeanRegistrySupport implements ConfigurableBeanFactory { |
该方法是一个空壳方法,具体逻辑都在doGetBean方法内:
1 | public abstract class AbstractBeanFactory extends FactoryBeanRegistrySupport implements ConfigurableBeanFactory { |
doGetBean方法中先通过getSingleton(String beanName)方法从三级缓存中获取Bean实例,如果不为空则进行后续处理;如果为空,则通过getSingleton(String beanName, ObjectFactory<?> singletonFactory)方法创建Bean实例并进行后续处理。
这两个方法都是AbstractBeanFactory父类DefaultSingletonBeanRegistry的方法,AbstractBeanFactory层级关系图如下所示:
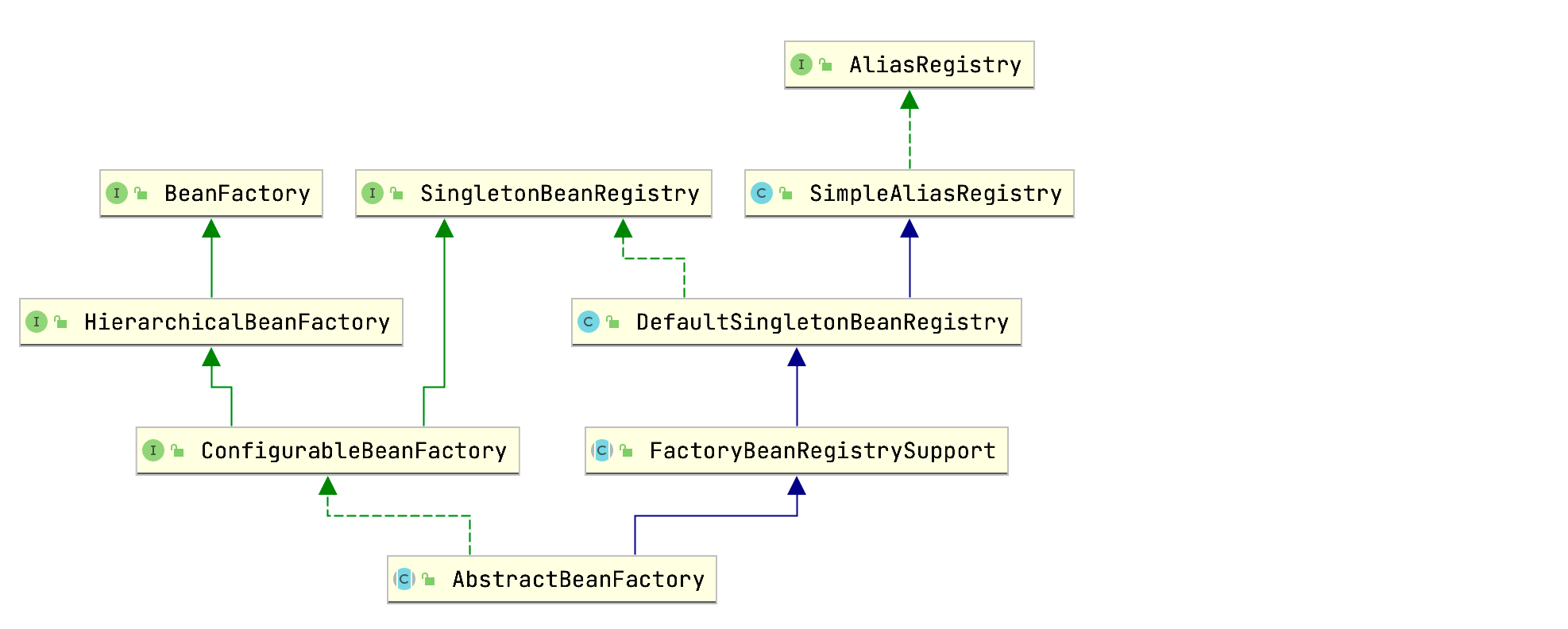
getSingleton(String beanName)相关源码如下所示:
1 | public class DefaultSingletonBeanRegistry extends SimpleAliasRegistry implements SingletonBeanRegistry { |
所谓的三级缓存指的是DefaultSingletonBeanRegistry类的三个成员变量:
1 | public class DefaultSingletonBeanRegistry extends SimpleAliasRegistry implements SingletonBeanRegistry { |
| 变量 | 描述 |
|---|---|
| singletonObjects | 一级缓存,key为Bean名称,value为Bean实例。这里的Bean实例指的是已经完全创建好的,即已经经历实例化->属性填充->初始化以及各种后置处理过程的Bean,可直接使用。 |
| earlySingletonObjects | 二级缓存,key为Bean名称,value为Bean实例。这里的Bean实例指的是仅完成实例化的Bean,还未进行属性填充等后续操作。用于提前曝光,供别的Bean引用,解决循环依赖。 |
| singletonFactories | 三级缓存,key为Bean名称,value为Bean工厂。在Bean实例化后,属性填充之前,如果允许提前曝光,Spring会把该Bean转换成Bean工厂并加入到三级缓存。在需要引用提前曝光对象时再通过工厂对象的getObject()方法获取。 |
如果通过三级缓存的查找都没有找到目标Bean实例,则通过getSingleton(String beanName, ObjectFactory<?> singletonFactory)方法创建:
1 | public class DefaultSingletonBeanRegistry extends SimpleAliasRegistry implements SingletonBeanRegistry { |
上述代码重点关注singletonFactory.getObject(),singletonFactory是一个函数式接口,对应AbstractBeanFactory的doGetBean方法中的lambda表达式:
1 | sharedInstance = getSingleton(beanName, () -> { |
重点关注createBean方法。该方法为抽象方法,由AbstractBeanFactory子类AbstractAutowireCapableBeanFactory实现:
1 | public abstract class AbstractAutowireCapableBeanFactory extends AbstractBeanFactory |
doCreateBean源码:
1 | public abstract class AbstractAutowireCapableBeanFactory extends AbstractBeanFactory |
addSingletonFactory方法为父类DefaultSingletonBeanRegistry的方法:
1 | public class DefaultSingletonBeanRegistry extends SimpleAliasRegistry implements SingletonBeanRegistry { |
上述整个过程可以用下图来总结(可右键选择新标签页中打开图片):

光看源码有点抽象,下面我们通过两个场景来加深理解。
首先模拟普通Spring Bean与普通Spring Bean之间循环依赖的场景。
新建SpringBoot项目,pom引入如下依赖:
1 | <dependencies> |
新建CircularReferenceTest类:
1 | public class CircularReferenceTest { |
上面代码通过AnnotationConfigApplicationContext创建了IOC容器,并先后注册了BeanA和BeanB,BeanA和BeanB相互依赖,程序输出如下:
1 | cc.mrbird.BeanA@368f2016 |
可以看到,Spring成功解决了循环依赖。下面配合源码来分析这个过程。
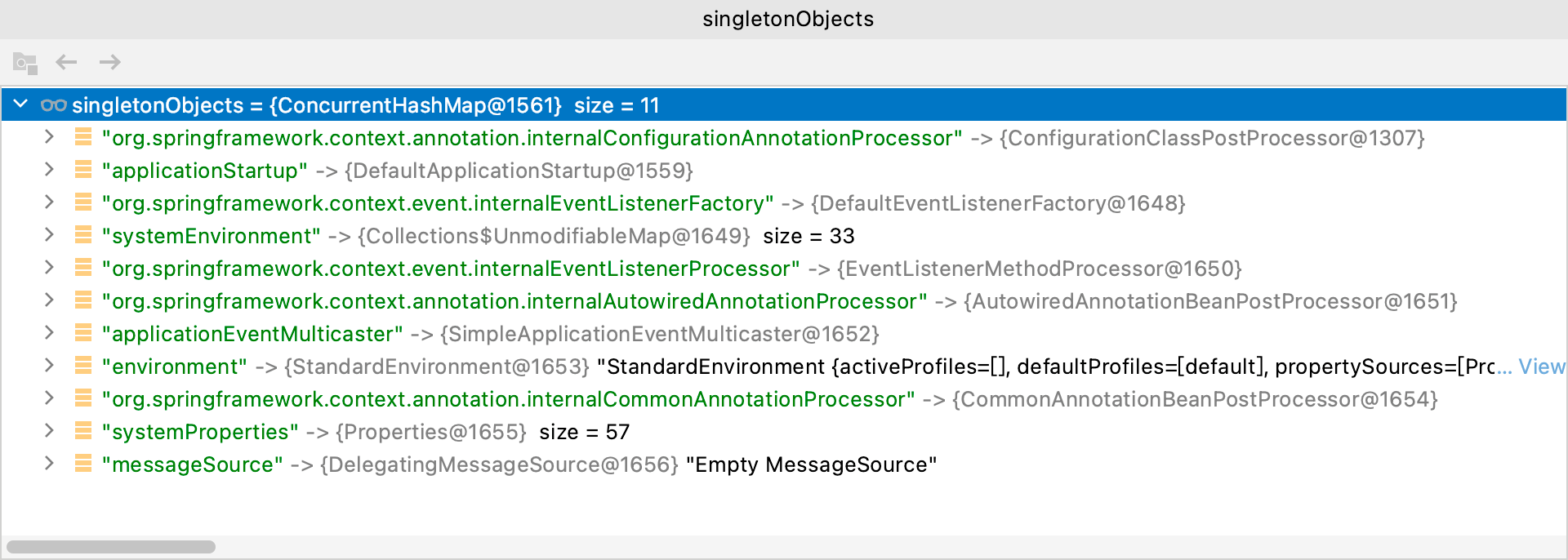
上面程序中,先创建BeanA,Spring内部调用doGetBean方法获取BeanA。一开始三级缓存中肯定没有BeanA和BeanB相关实例:


所以我们直接看doCreateBean相关源码:
1 | public abstract class AbstractAutowireCapableBeanFactory extends AbstractBeanFactory |
上面代码,Spring实例化了BeanA,然后往三级缓存中添加了BeanA的工厂对象,根据前面getEarlyBeanReference方法的源码我们可以知道,在不存在AOP代理的情况下,该方法直接返回原始BeanA对象。所以通过该工厂方法创建的BeanA对象仅仅是进行了实例化操作,属性还未被赋值,换句话说,该工厂用于提前曝光BeanA实例。
接着调用populateBean方法对BeanA属性赋值,赋值过程发现BeanA依赖于BeanB,所以Spring重复以上步骤创建BeanB。创建过程中同样会遇到populateBean方法对BeanB属性赋值,赋值过程中发现BeanB依赖于BeanA,于是Spring又回头创建BeanA,不过这时候情况就开始不一样了!!
doGetBean方法内部从三级缓存中获取BeanA对象时,三级缓存内容如下:
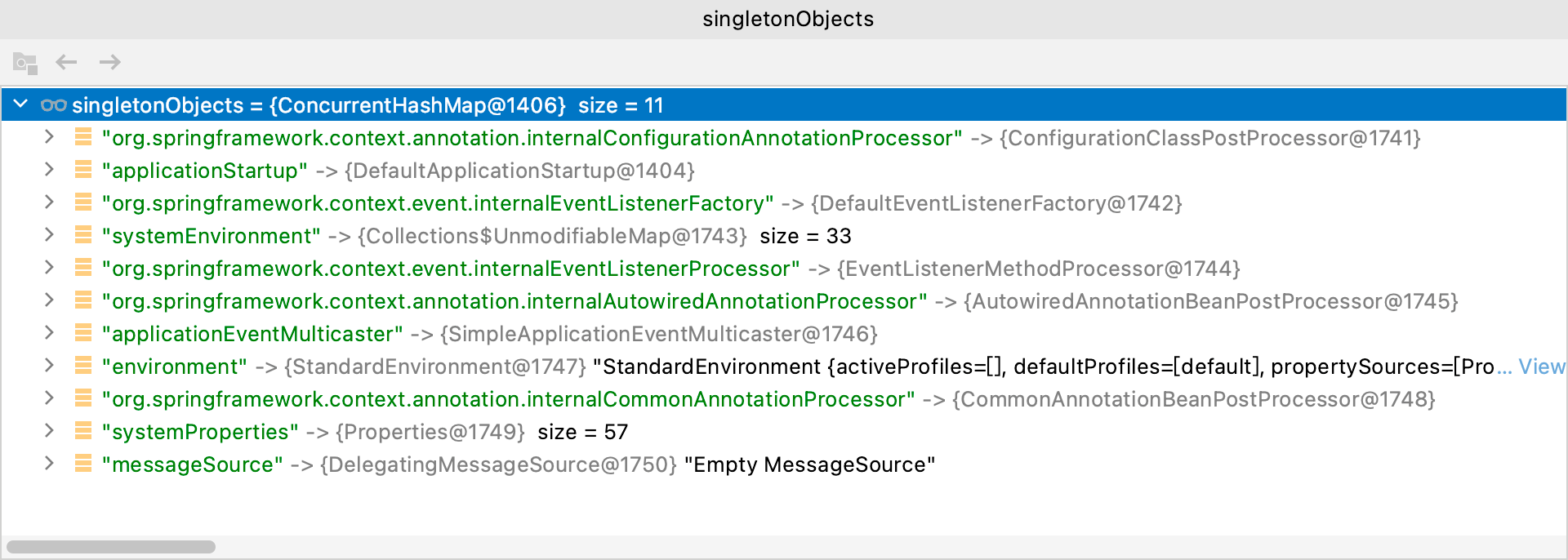


可以看到一级缓存和二级缓存没有什么不一样,但三级缓存中已经存在BeanA和BeanB的工厂对象了!
所以此时getSingleton(String beanName, boolean allowEarlyReference)方法内的逻辑如下:
1 | public class DefaultSingletonBeanRegistry extends SimpleAliasRegistry implements SingletonBeanRegistry { |
此时查看二级缓存:

可以看到,BeanA确实只是早期实例,属性BeanB还未被赋值呢。
随后BeanB在属性填充的时候获取到了BeanA早期实例,完成属性填充、初始化等后续操作,BeanB创建完毕。BeanB完整创建完毕后,BeanA随之也完成属性填充、初始化等后续操作,BeanA也创建完毕,循环依赖得以解决。
BeanB虽然获取到的是BeanA的早期对象,但当BeanA完整创建完毕后,BeanB里的BeanA也将会是完整的,因为指针指向的都是同一个BeanA地址。
画个图总结上面的过程(可右键选择新标签页中打开图片):

普通Bean和代理Bean之间的循环依赖和上面过程差不多,不过细节上有些许差异。
删除上面创建的CircularReferenceTest类。为了模拟AOP代理的情况,我们需要引入AOP依赖:
1 | <dependency> |
然后修改Boot入口类:
1 |
|
因为MyAspect切面类的存在,BeanA将会是个代理类,而BeanB则是普通Bean,程序输出如下:
1 | onBefore:getBeanB方法开始执行 |
假设容器先创建BeanA,过程和上面的例子一致,属性填充时,发现BeanA依赖BeanB,然后Spring开始创建BeanB。创建BeanB时候又发现其依赖BeanA,这时三级缓存中已经存在BeanA的工厂对象了,所以直接通过该工厂对象获取BeanA的早期实例:
1 | public class DefaultSingletonBeanRegistry extends SimpleAliasRegistry implements SingletonBeanRegistry { |
singletonFactory.getObject()实际实现为lambda表达式() -> getEarlyBeanReference(beanName, mbd, bean),getEarlyBeanReference方法源码:
1 | protected Object getEarlyBeanReference(String beanName, RootBeanDefinition mbd, Object bean) { |
在引入AOP依赖后,容器中将会有一个SmartInstantiationAwareBeanPostProcessor接口的实现类AbstractAutoProxyCreator,用于创建AOP代理,所以上面getEarlyBeanReference方法里的bp.getEarlyBeanReference(exposedObject, beanName)逻辑实际上为AbstractAutoProxyCreator实现的getEarlyBeanReference方法:
1 | public abstract class AbstractAutoProxyCreator extends ProxyProcessorSupport |
所以BeanB从三级缓存中获取到的为代理后的BeanA实例:
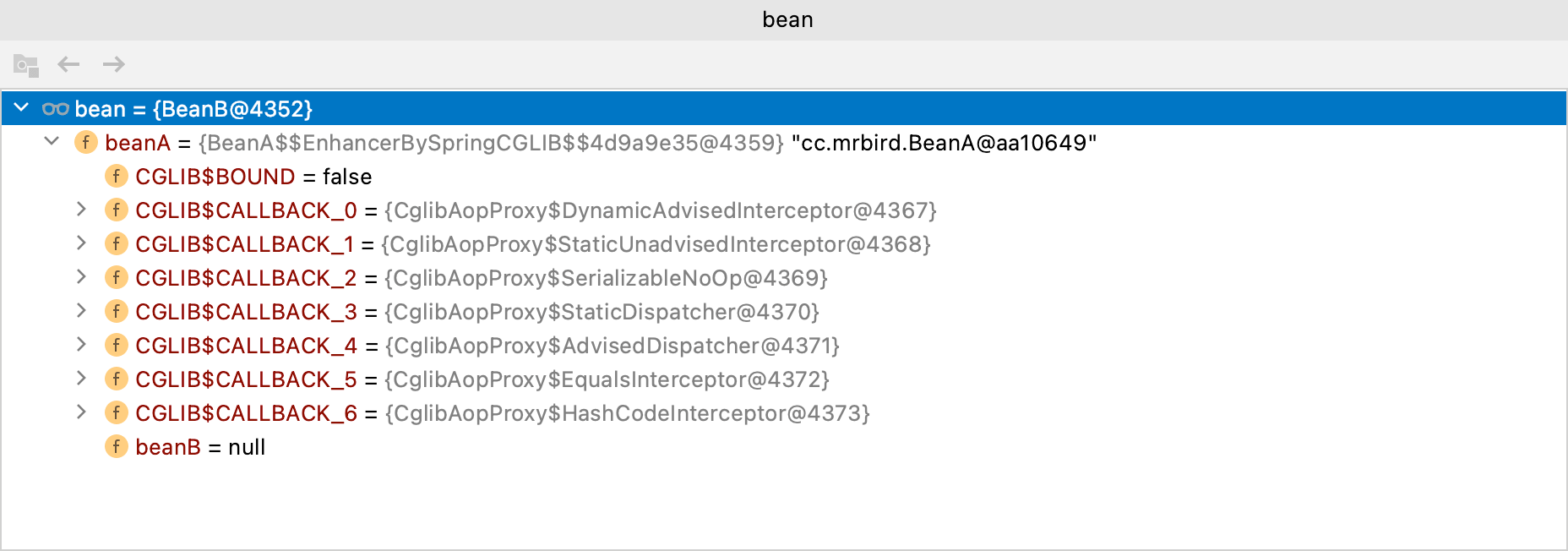
BeanB创建完毕后,BeanA属性填充操作随之结束。
通过深入理解Spring-AOP原理对AOP的学习我们知道,代理对象是在后置处理BeanPostProcessor的postProcessAfterInitialization方法内完成的,而该方法的调用时机为Bean属性填充后的初始化操作时,所以在BeanA属性填充操作结束时,BeanA还只是一个普通对象,而BeanB里的BeanA已经是代理对象了。
继续BeanA的创建过程,BeanA属性填充完后,执行initializeBean(beanName, exposedObject, mbd)方法进行初始化操作:
1 | public abstract class AbstractAutowireCapableBeanFactory extends AbstractBeanFactory |
我们主要关注初始化操作阶段执行动态代理的后置处理方法过程:
1 | public abstract class AbstractAutoProxyCreator extends ProxyProcessorSupport |
到这里BeanA依旧是普通对象,继续查看doCreateBean方法的后续逻辑:
1 | public abstract class AbstractAutowireCapableBeanFactory extends AbstractBeanFactory |
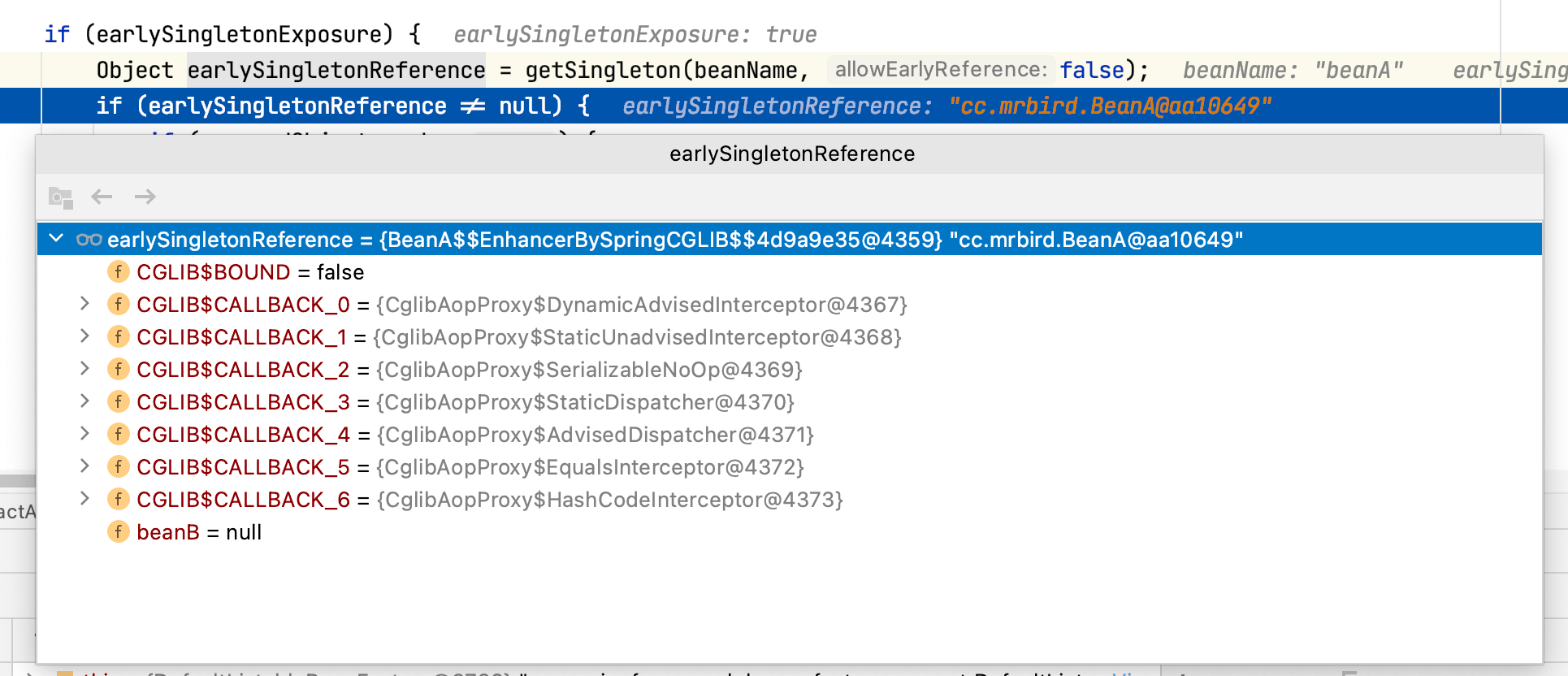
到这里,无论是BeanB里的BeanA,还是IOC容器中的BeanA,都是代理后的BeanA了。
画张图总结下上面的过程(可右键选择新标签页中打开图片):

上面的例子都是基于属性注入的情况,假如存在构造器注入情况下的循环依赖,Spring将没办法解决。这是因为对象的提前曝光时机发生在对象实例化之后,而构造器注入时机为对象实例化时,所以此时还未进行提前曝光操作,循环依赖也就没办法解决了,比如下面这种情况:
1 |
|
程序将抛出如下异常:
1 | *************************** |
此外,这里讨论了普通Bean与普通Bean之间的循环依赖,代理Bean与普通Bean之间的循环依赖,实际情况还可能存在工厂Bean与普通Bean、代理Bean之间的循环依赖,这种情况比较复杂,本文不讨论,因为就理解Spring解决循环依赖的思想而言,上面两种情况搞清楚了就OK了。
]]>本节用于记录Java HashMap底层数据结构、方法实现原理等,基于JDK 1.8。
Java HashMap底层采用哈希表结构(数组+链表、JDK1.8后为数组+链表或红黑树)实现,结合了数组和链表的优点:
数组优点:通过数组下标可以快速实现对数组元素的访问,效率极高;
链表优点:插入或删除数据不需要移动元素,只需修改节点引用,效率极高。
HashMap图示如下所示:
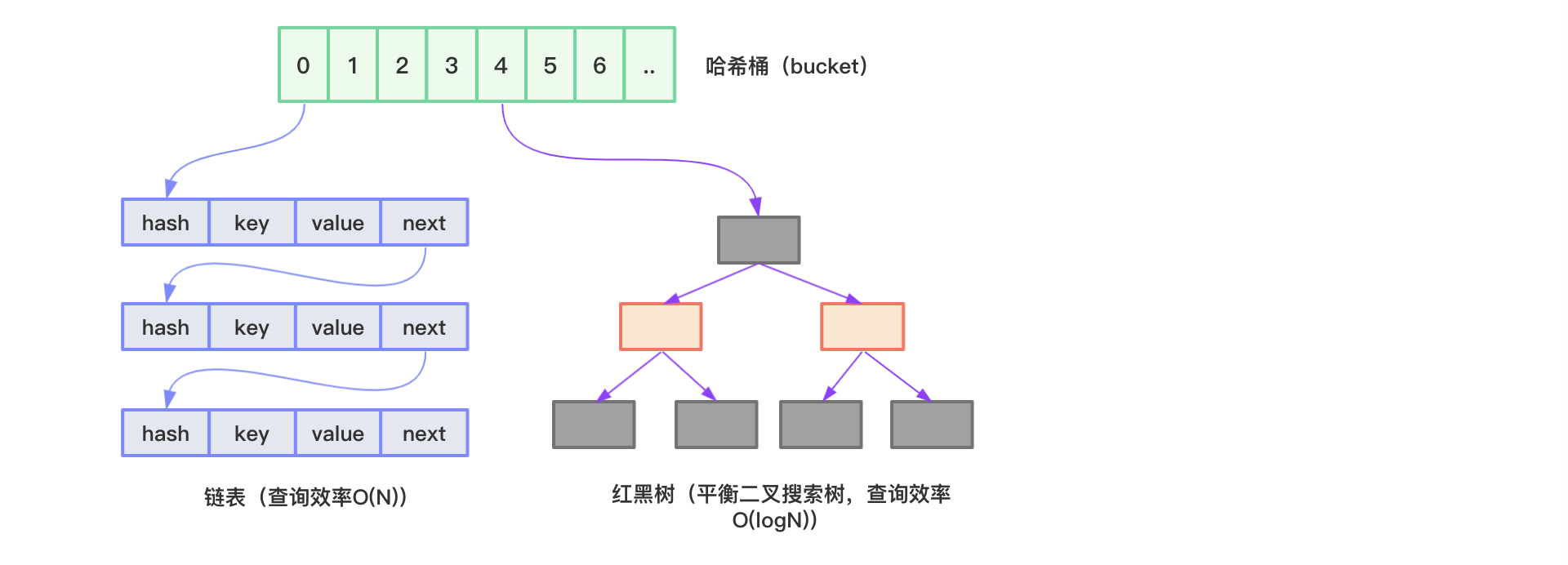
HashMap内部使用数组存储数据,数组中的每个元素类型为Node<K,V>:
1 | static class Node<K,V> implements Map.Entry<K,V> { |
Node包含了四个字段:hash、key、value、next,其中next表示链表的下一个节点。
HashMap通过hash方法计算key的哈希码,然后通过(n-1)&hash公式(n为数组长度)得到key在数组中存放的下标。当两个key在数组中存放的下标一致时,数据将以链表的方式存储(哈希冲突,哈希碰撞)。我们知道,在链表中查找数据必须从第一个元素开始一层一层往下找,直到找到为止,时间复杂度为O(N),所以当链表长度越来越长时,HashMap的效率越来越低。
为了解决这个问题,JDK1.8开始采用数组+链表+红黑树的结构来实现HashMap。当链表中的元素超过8个(TREEIFY_THRESHOLD)并且数组长度大于64(MIN_TREEIFY_CAPACITY)时,会将链表转换为红黑树,转换后数据查询时间复杂度为O(logN)。
红黑树的节点使用TreeNode表示:
1 | static final class TreeNode<K,V> extends LinkedHashMap.Entry<K,V> { |
HashMap包含几个重要的变量:
1 | // 数组默认的初始化长度16 |
上面这些字段在下面源码解析的时候尤为重要,其中需要着重讨论的是加载因子是什么,为什么默认值为0.75f。
加载因子也叫扩容因子,用于决定HashMap数组何时进行扩容。比如数组容量为16,加载因子为0.75,那么扩容阈值为16*0.75=12,即HashMap数据量大于等于12时,数组就会进行扩容。我们都知道,数组容量的大小在创建的时候就确定了,所谓的扩容指的是重新创建一个指定容量的数组,然后将旧值复制到新的数组里。扩容这个过程非常耗时,会影响程序性能。所以加载因子是基于容量和性能之间平衡的结果:
可以看到容量占用和性能是此消彼长的关系,它们的平衡点由加载因子决定,0.75是一个即兼顾容量又兼顾性能的经验值。
此外用于存储数据的table字段使用transient修饰,通过transient修饰的字段在序列化的时候将被排除在外,那么HashMap在序列化后进行反序列化时,是如何恢复数据的呢?HashMap通过自定义的readObject/writeObject方法自定义序列化和反序列化操作。这样做主要是出于以下两点考虑:
所以在HashXXX类中(如HashTable,HashSet,LinkedHashMap等等),我们可以看到,这些类用于存储数据的字段都用transient修饰,并且都自定义了readObject/writeObject方法。readObject/writeObject方法这节就不进行源码分析了,有兴趣自己研究。
put方法源码如下:
1 | public V put(K key, V value) { |
put方法通过hash函数计算key对应的哈希值,hash函数源码如下:
1 | static final int hash(Object key) { |
如果key为null,返回0,不为null,则通过(h = key.hashCode()) ^ (h >>> 16)公式计算得到哈希值。该公式通过hashCode的高16位异或低16位得到哈希值,主要从性能、哈希碰撞角度考虑,减少系统开销,不会造成因为高位没有参与下标计算从而引起的碰撞。
得到key对应的哈希值后,再调用putVal(hash(key), key, value, false, true)方法插入元素:
1 | final V putVal(int hash, K key, V value, boolean onlyIfAbsent, |
put操作过程总结:
(n-1) & hash计算key在数组中的存放索引;目标索引位置不为空的话,分下面三种情况:
4.1. key相同,覆盖旧值;
4.2. 该节点类型是红黑树的话,执行红黑树插入操作;
4.3. 该节点类型是链表的话,遍历到最后一个元素尾插入,如果期间有遇到key相同的,则直接覆盖。如果链表长度大于等于TREEIFY_THRESHOLD,并且数组容量大于等于MIN_TREEIFY_CAPACITY,则将链表转换为红黑树结构;
判断HashMap元素个数是否大于等于threshold,是的话,进行扩容操作。
get和put相比,就简单多了,下面是get操作源码:
1 | public V get(Object key) { |
由前面的put源码分析我们知道,数组的初始化和扩容都是通过调用resize方法完成的,所以现在来关注下resize方法的源码:
1 | final Node<K,V>[] resize() { |
JDK1.8在扩容时通过高位运算e.hash & oldCap结果是否为0来确定元素是否需要移动,主要有如下两种情况:
情况一:
扩容前oldCap=16,hash=5,(n-1)&hash=15&5=5,hash&oldCap=5&16=0;
扩容后newCap=32,hash=5,(n-1)&hash=31&5=5,hash&oldCap=5&16=0。
这种情况下,扩容后元素索引位置不变,并且hash&oldCap==0。
情况二:
扩容前oldCap=16,hash=18,(n-1)&hash=15&18=2,hash&oldCap=18&16=16;
扩容后newCap=32,hash=18,(n-1)&hash=31&18=18,hash&oldCap=18&16=16。
这种情况下,扩容后元素索引位置为18,即旧索引2加16(oldCap),并且hash&oldCap!=0。
我们通常使用下面两种方式遍历HashMap:
1 | HashMap<String, Object> map = new HashMap<>(); |
程序输出:
1 | 1: a |
通过前面对put源码的分析,我们知道HashMap是无序的,输出元素顺序和插入元素顺序一般都不一样。但是多次运行上面的程序你会发现,每次遍历的顺序都是一样的。那么遍历的原理是什么,内部是如何操作的?
通过entrySet或者keySet遍历,它们的内部原理是一样的,这里以entrySet为例。
通过查看代码对应的class文件,你会发现下面这段代码实际会被转换为iterator遍历:
1 | Set<Map.Entry<String, Object>> entries = map.entrySet(); |
增强for循环会被编译为:
1 | Set<Entry<String, Object>> entries = map.entrySet(); |
我们查看entrySet,iterator,hasNext,next方法的源码就可以清楚的了解到HashMap遍历原理了:
1 | public Set<Map.Entry<K,V>> entrySet() { |
总之,遍历HashMap的过程就是从头查找HashMap数组中的不为空的结点,如果该结点下存在链表,则遍历该链表,遍历完链表后再找HashMap数组中下一个不为空的结点,以此进行下去直到遍历结束。
那么,如果某个结点下是红黑树结构的话,怎么遍历?其实当链表转换为红黑树时,链表节点里包含的next字段信息是保留的,所以我们依旧可以通过红黑树节点中的next字段找到下一个节点。
JDK1.7 HashMap源码:https://github.com/ZhaoX/jdk-1.7-annotated/blob/master/src/java/util/HashMap.java。
JDK1.8 HashMap数组元素类型为Node<K,V>,JDK1.7 HashMap数组元素类型为Entry<K,V>:
1 | transient Entry<K,V>[] table = (Entry<K,V>[]) EMPTY_TABLE; |
实际就是换了个类名,并没有什么本质不同。
JDK1.7 hash计算规则为:
1 | final int hash(Object k) { |
相比于JDK1.8的hash方法,JDK1.7的hash方法的性能会稍差一点。
JDK1.7并没有使用红黑树,如果哈希冲突后,都用链表解决。区别于JDK1.8的尾部插入,JDK1.7采用头部插入的方式:
1 | public V put(K key, V value) { |
JDK1.8在扩容时通过高位运算e.hash & oldCap结果是否为0来确定元素是否需要移动,JDK1.7重新计算了每个元素的哈希值,按旧链表的正序遍历链表、在新链表的头部依次插入,即在转移数据、扩容后,容易出现链表逆序的情况:
1 | void resize(int newCapacity) { |
此时若多线程并发执行resize操作,容易出现环形链表,从而在获取数据、遍历链表时造成死循环,具体可以参考:https://blog.csdn.net/hhx0626/article/details/54024222。
]]>树(Tree)是一种很有趣的数据结构,它既能像链表那样快速的插入和删除,又能像有序数组那样快速查找。树的种类很多,本节将记录一种特殊的树————二叉树(Binary Tree)。二叉树的每个节点最多只能有两个子节点,通常称为左子节点和右子节点。如果一个二叉树的每个节点的左子节点的关键字值小于该节点,右子节点的关键字值大于等于该节点,那么这种二叉树也称为二叉搜索树(Binary Search Tree,BST),本节主要关注BST。
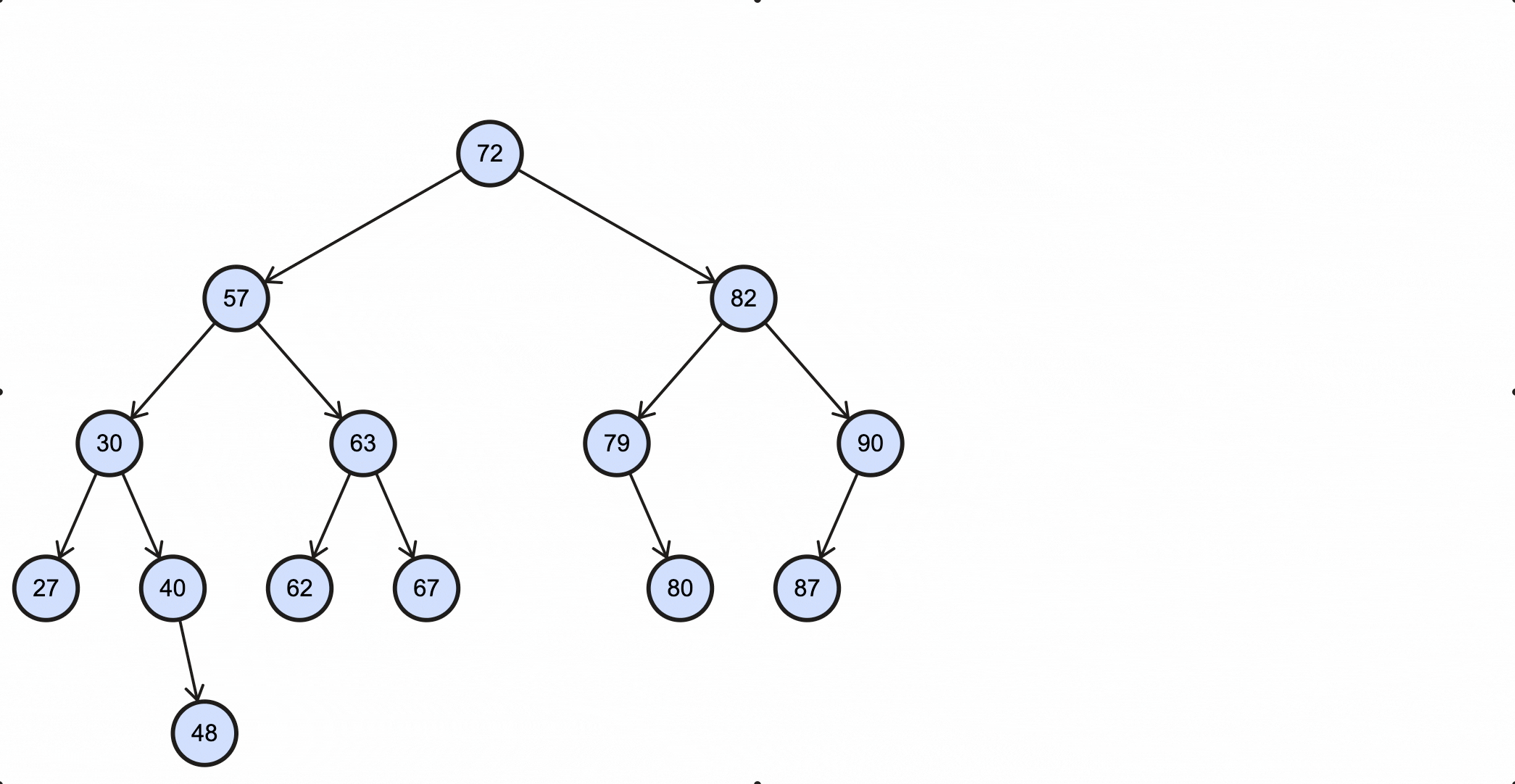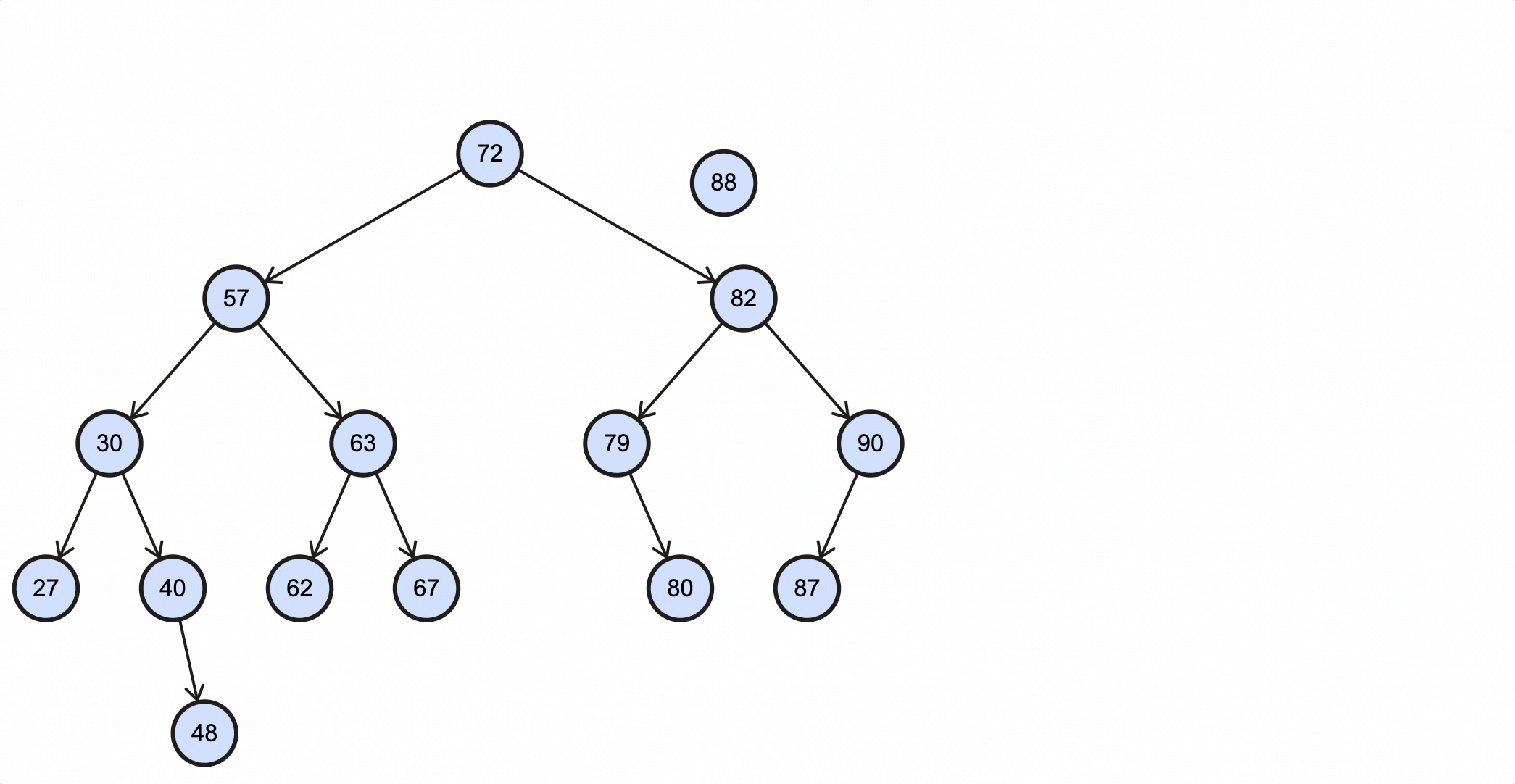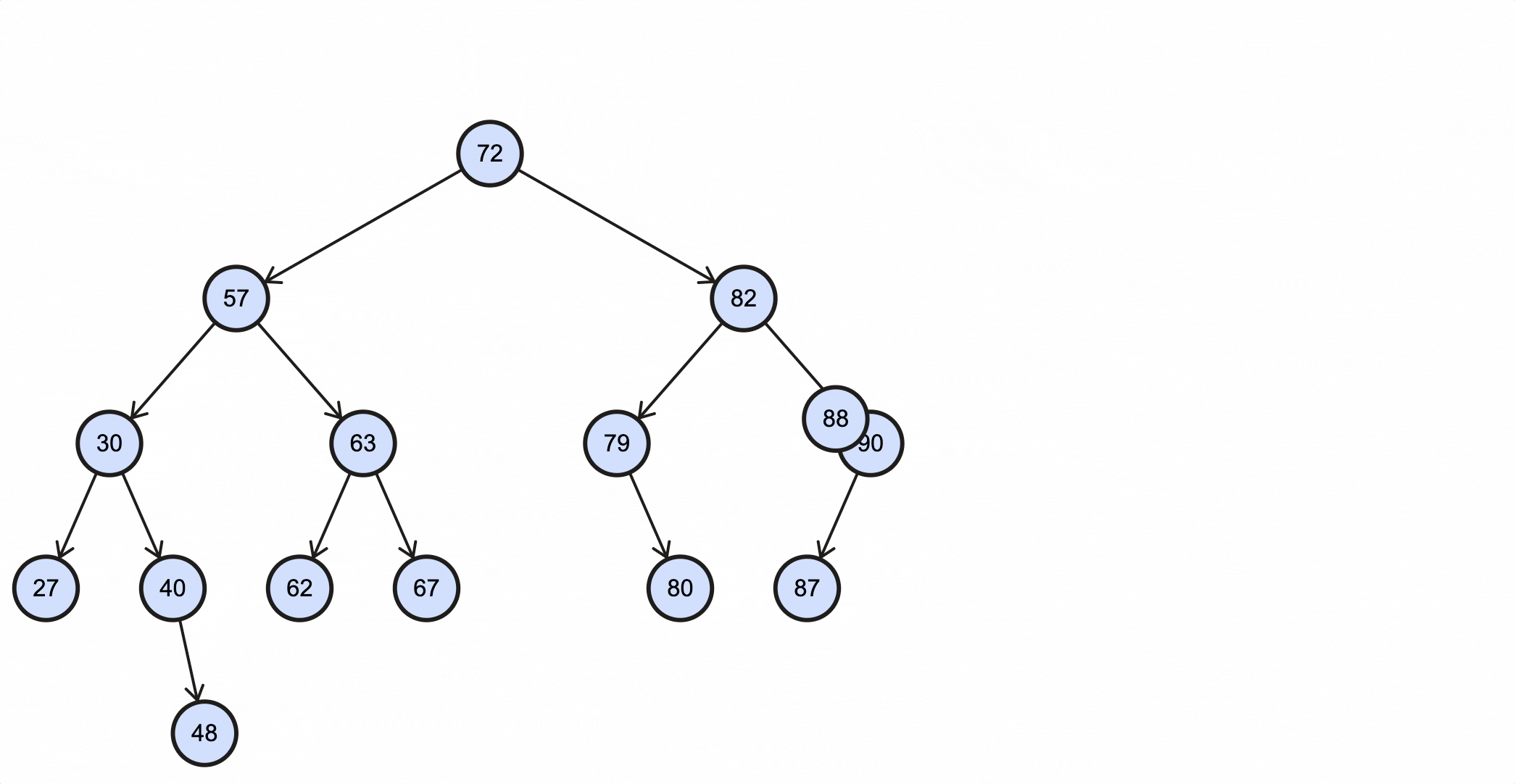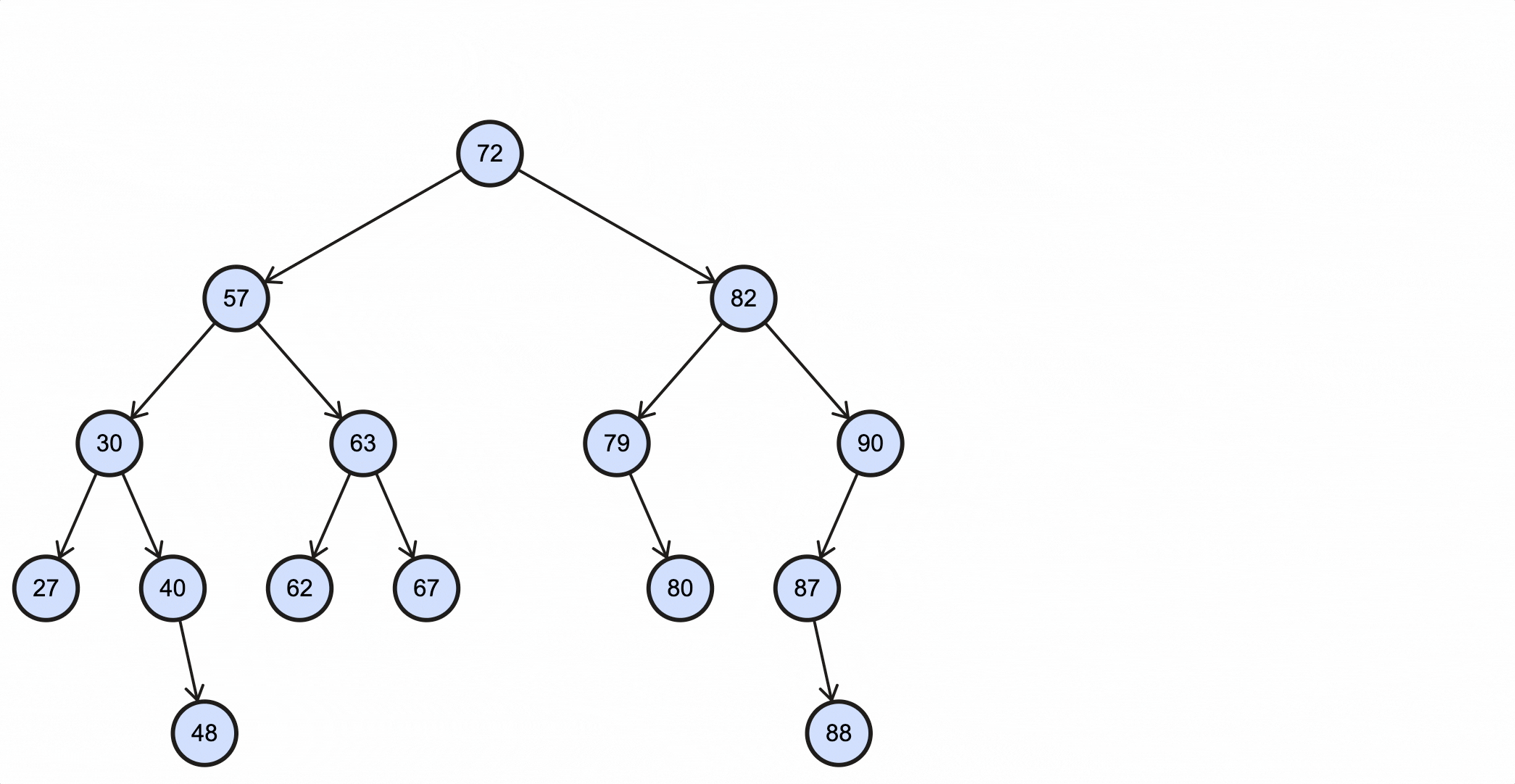
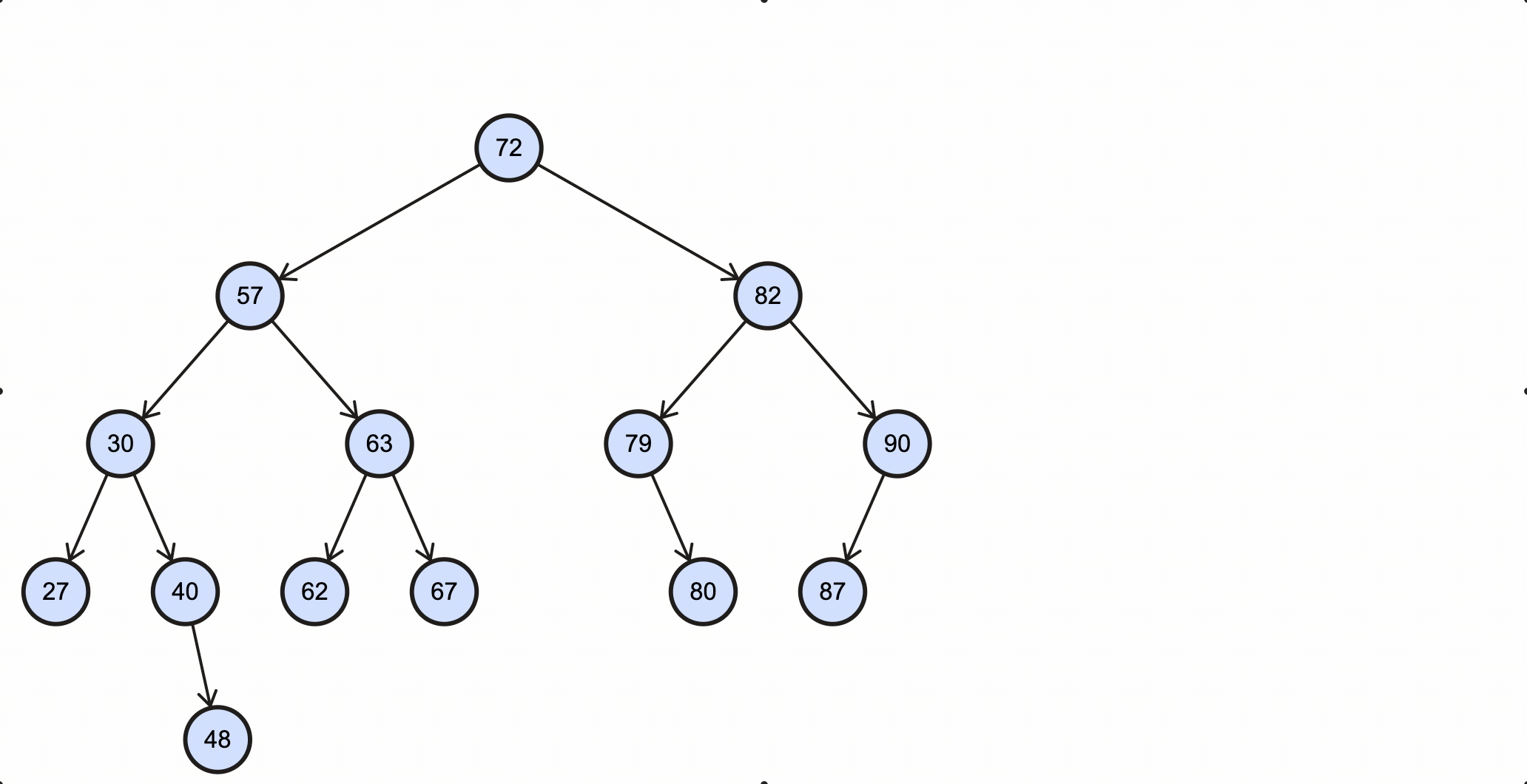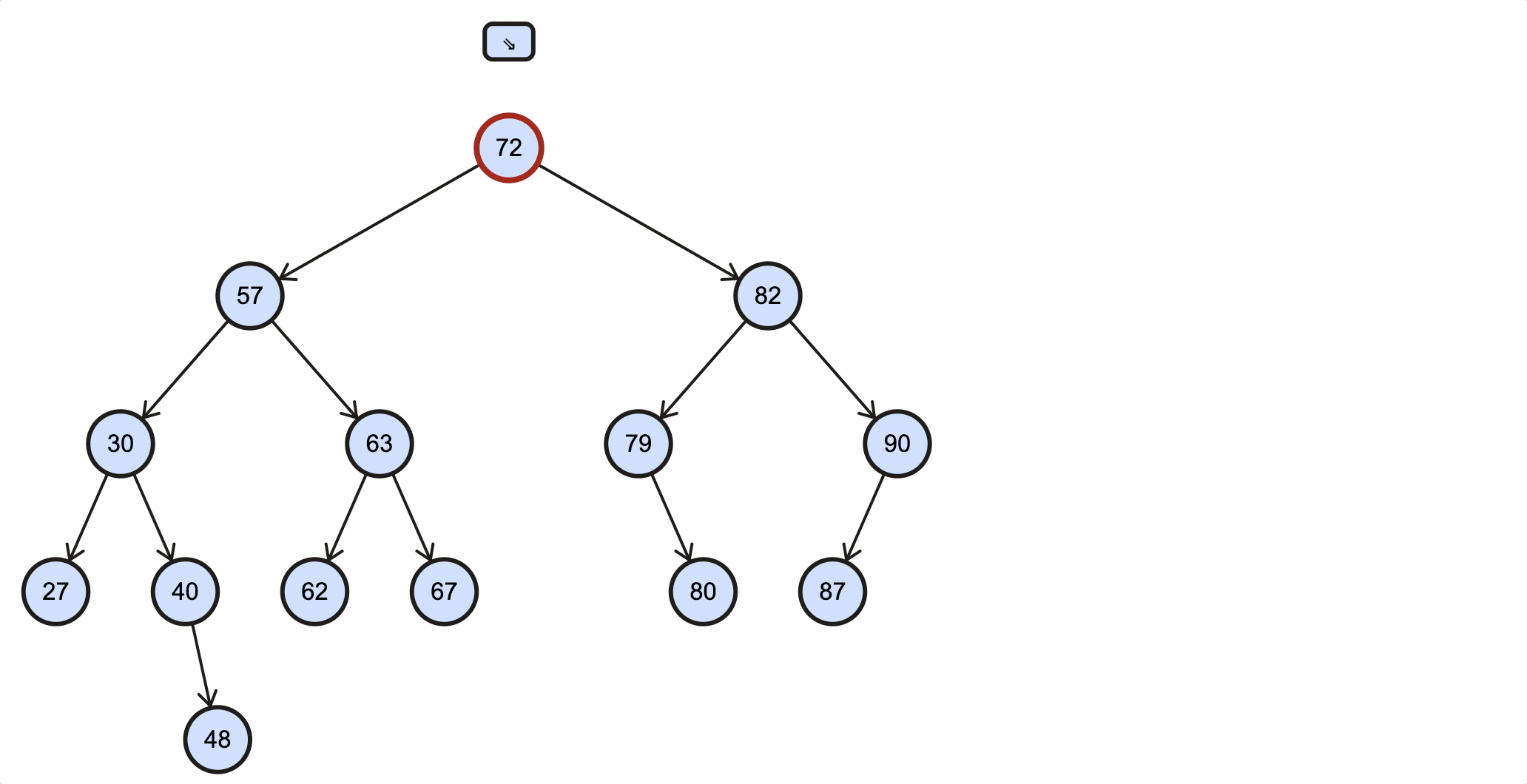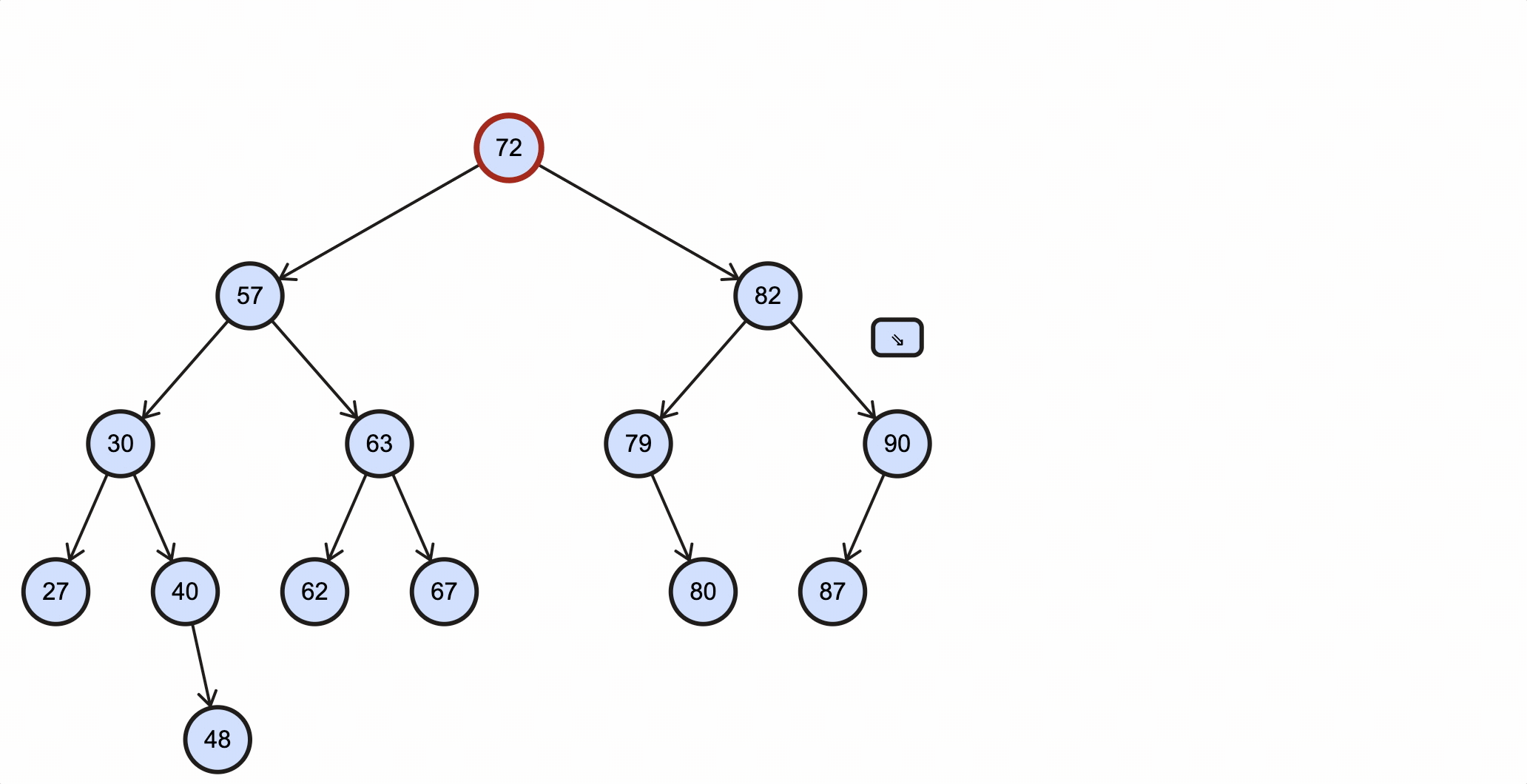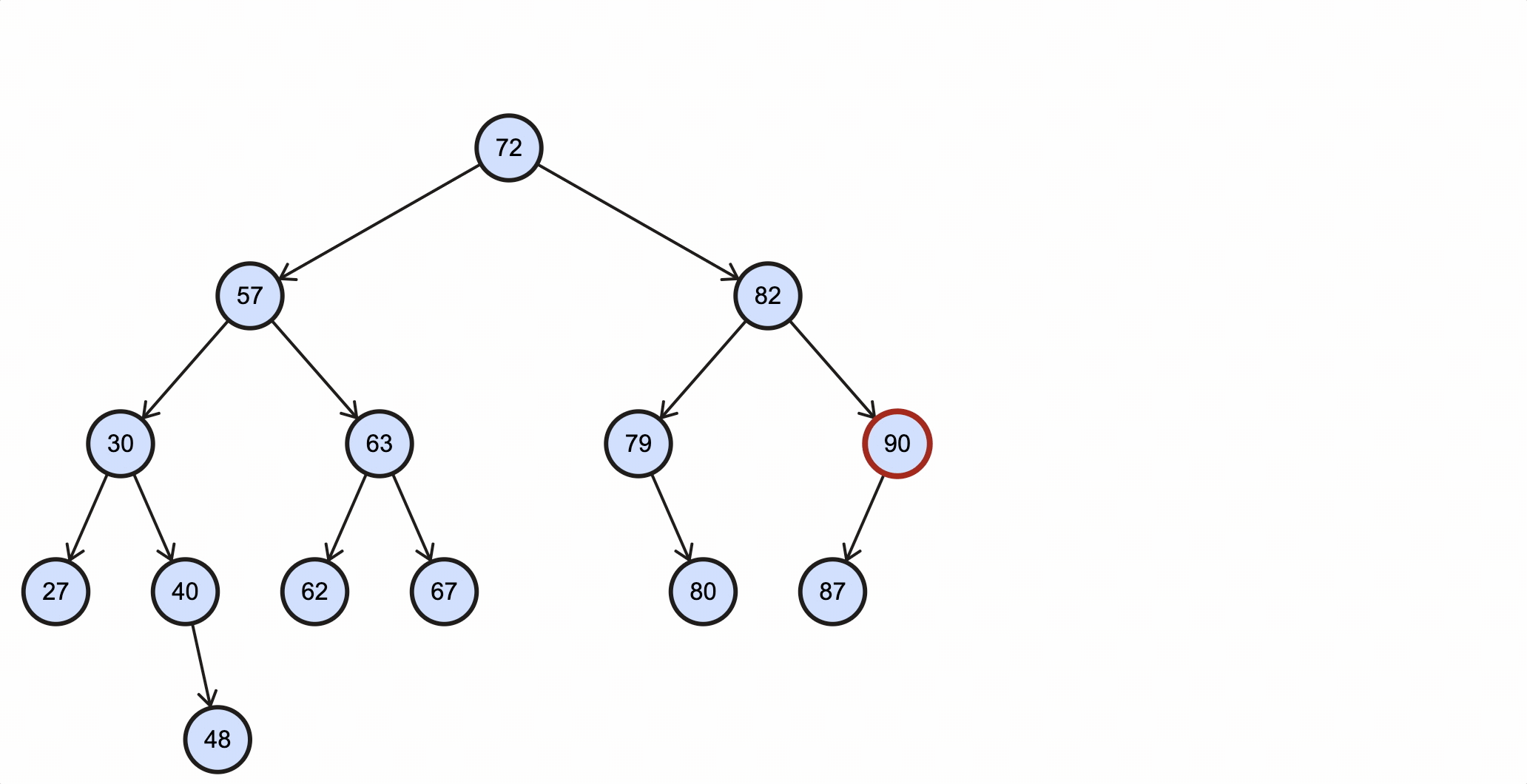
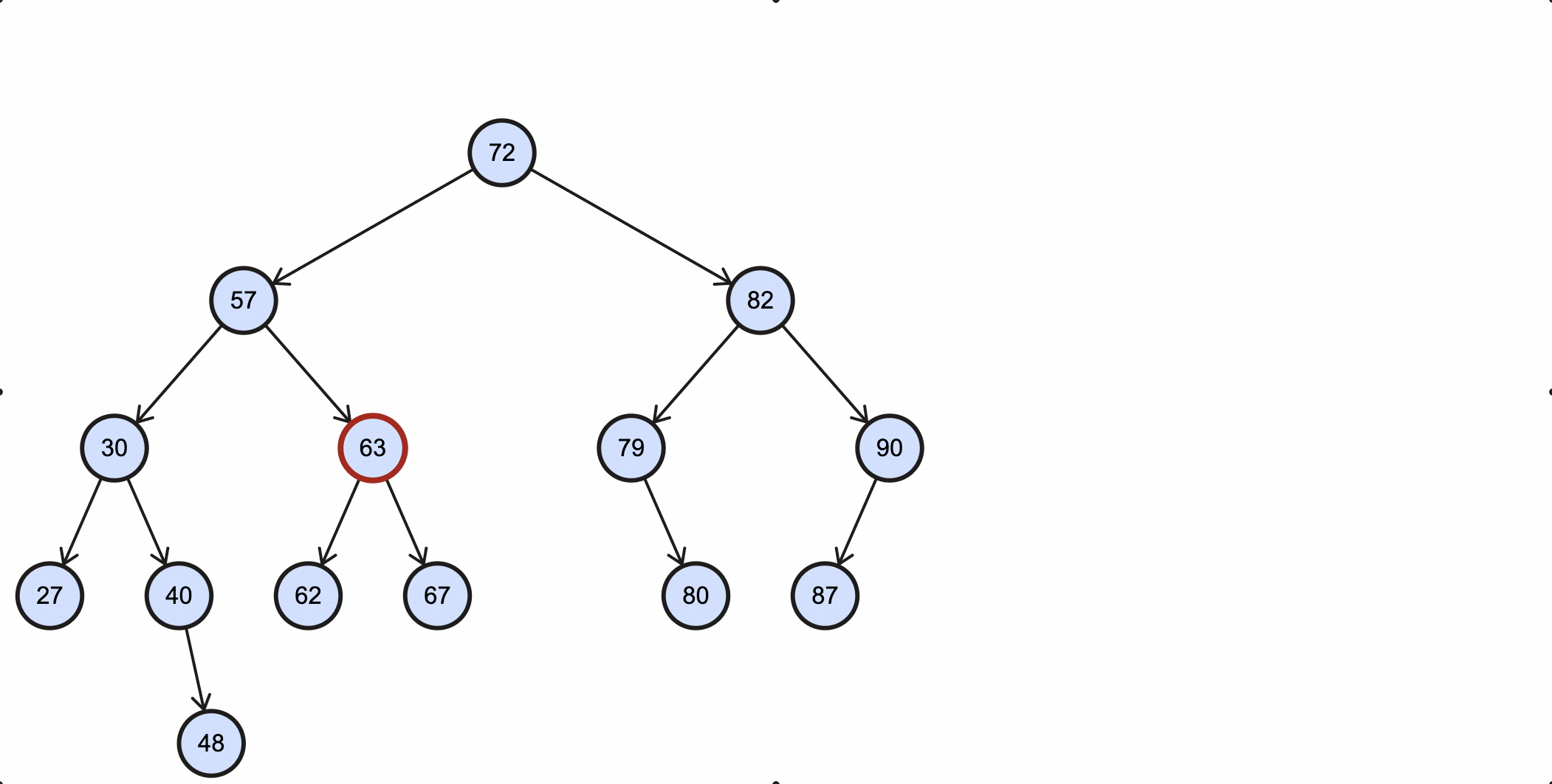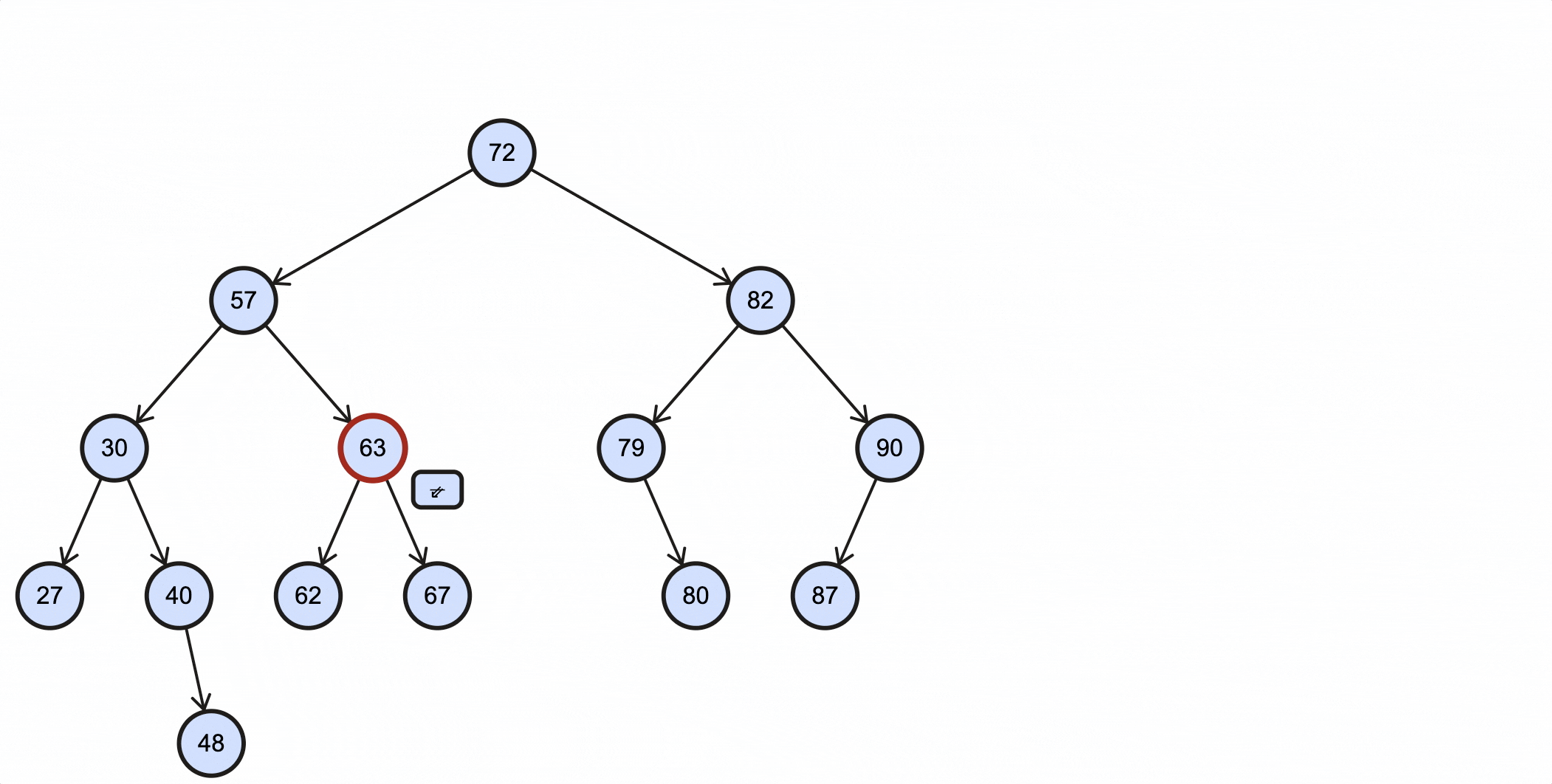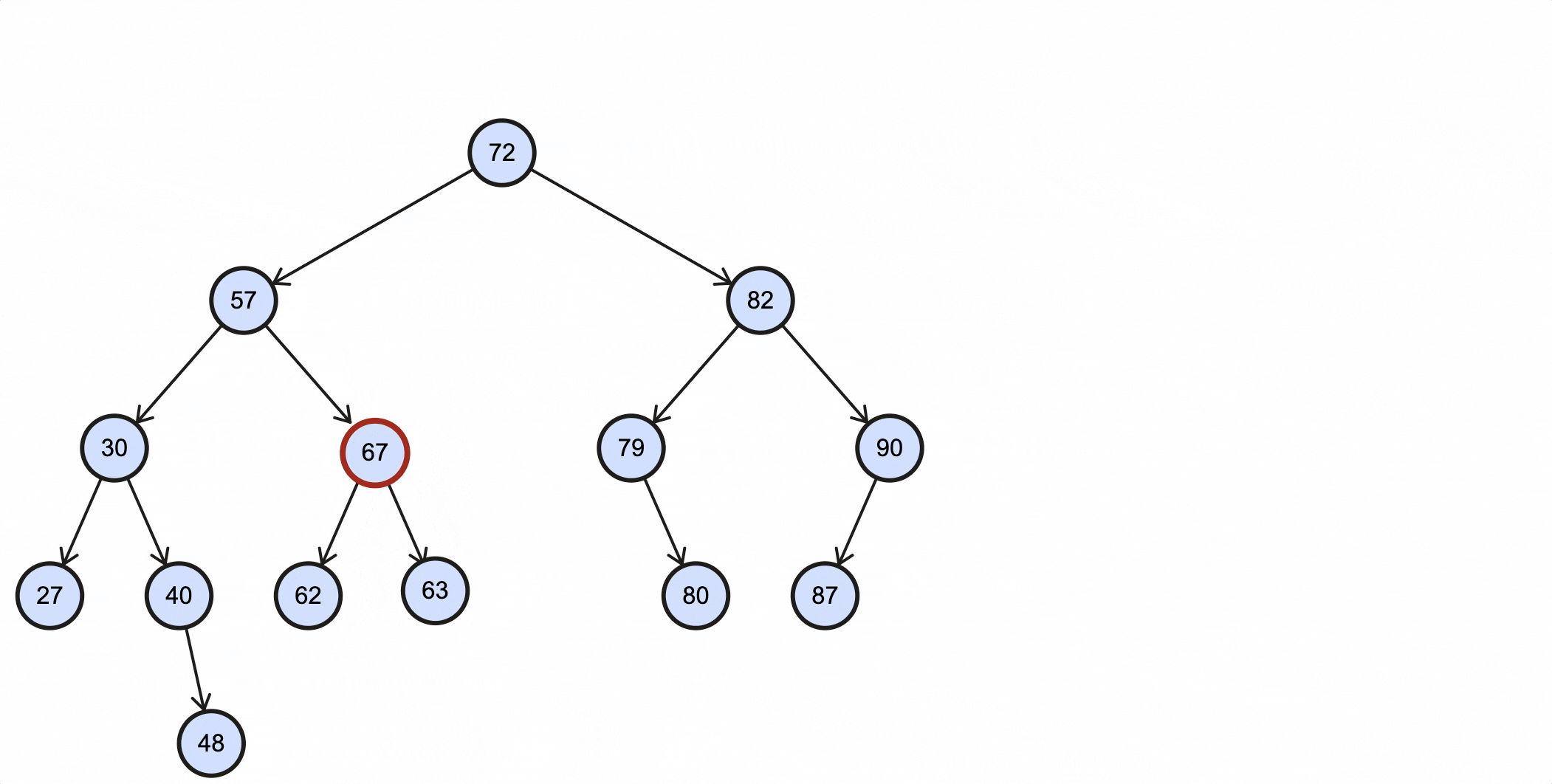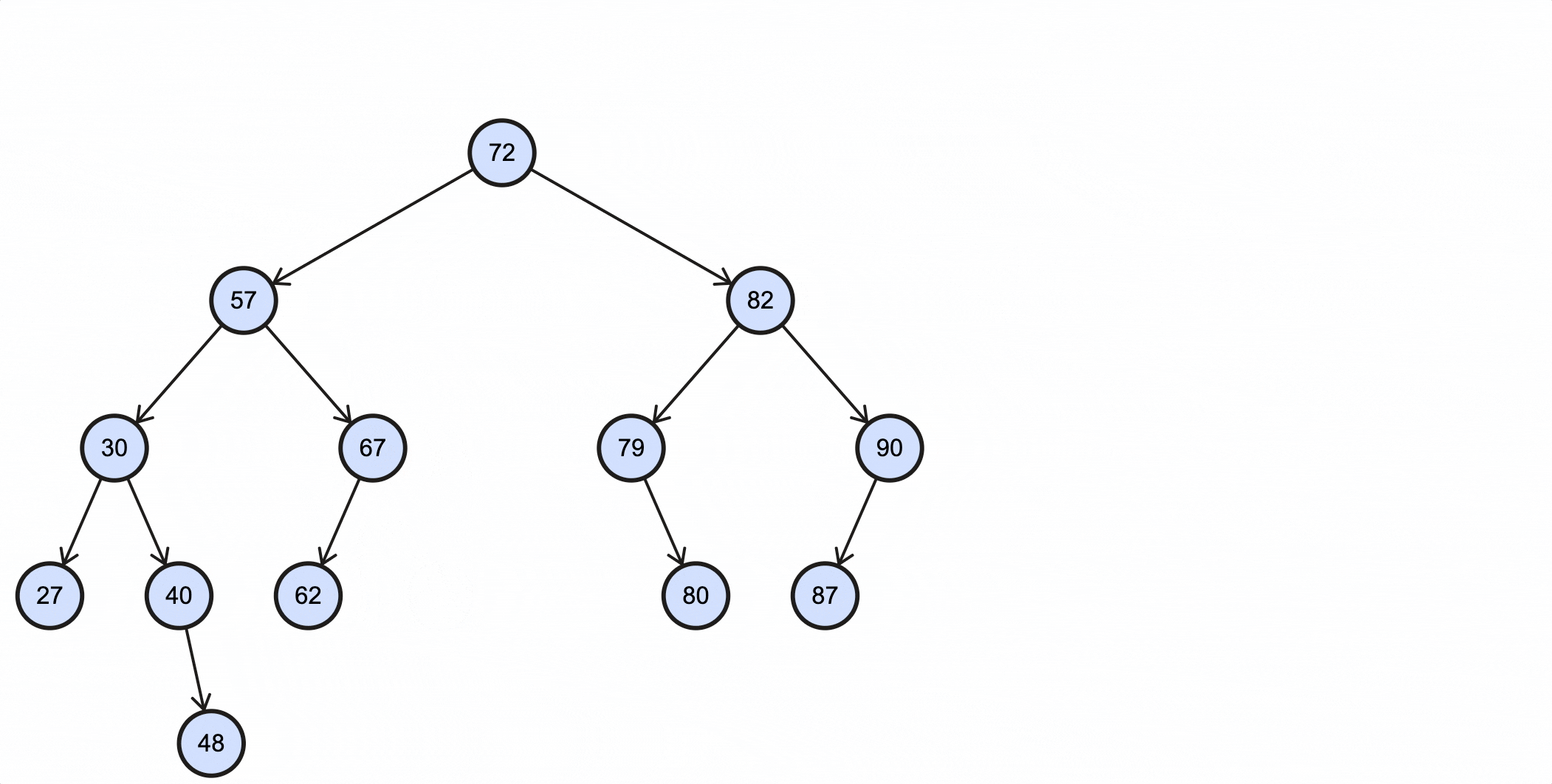
查看一个BST例子:
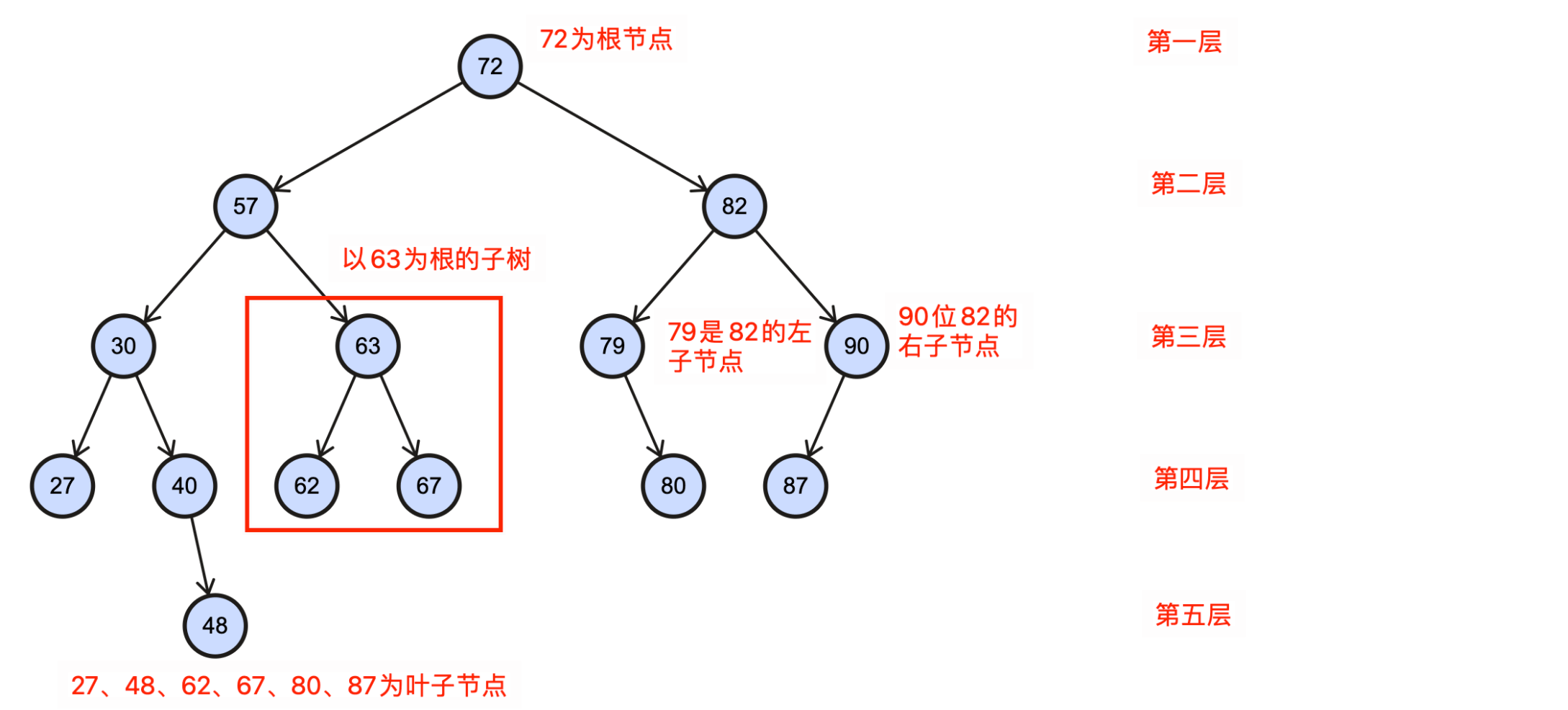
在操作BST前,我们先用代码定义一个BST的骨架:
1 | /** BST */ |
下面的这些操作都以这个BST为例:
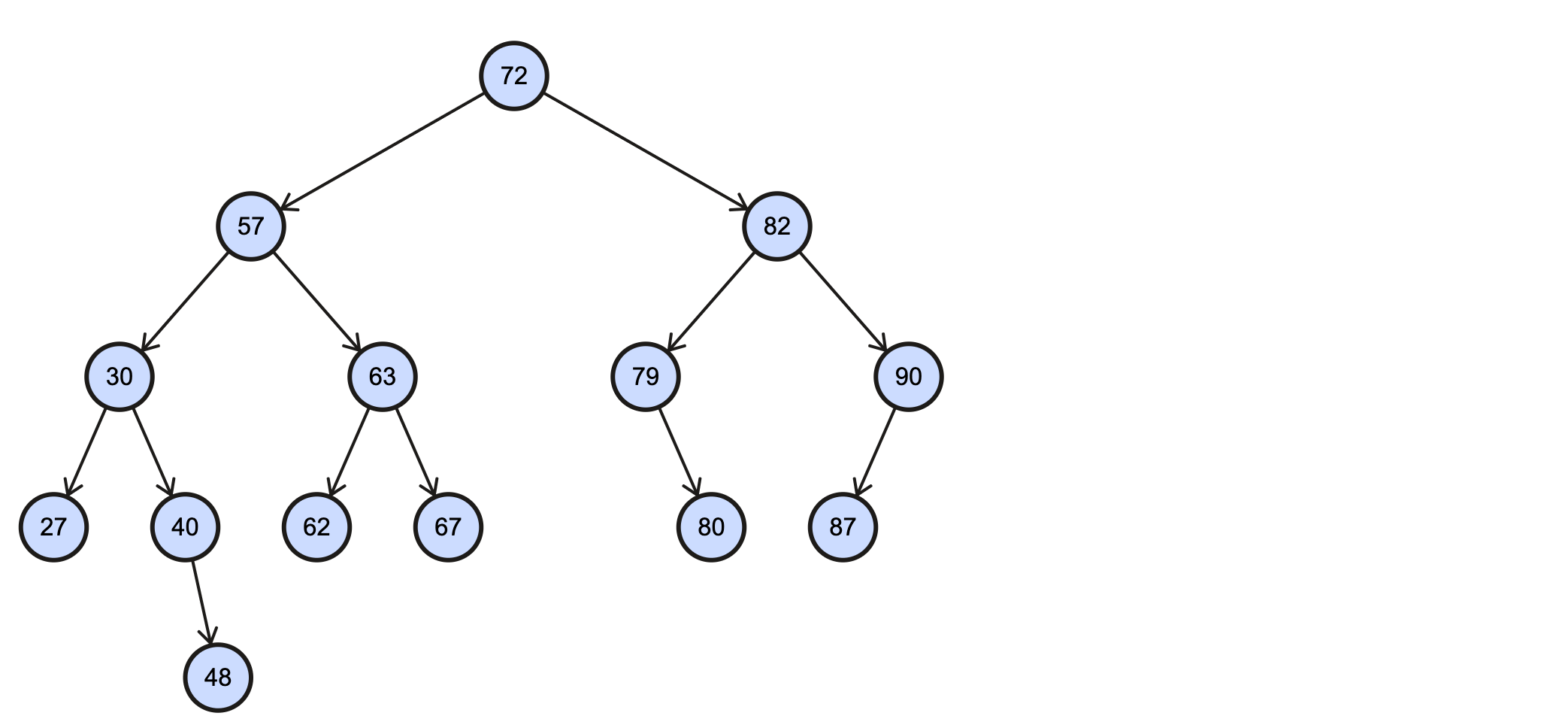
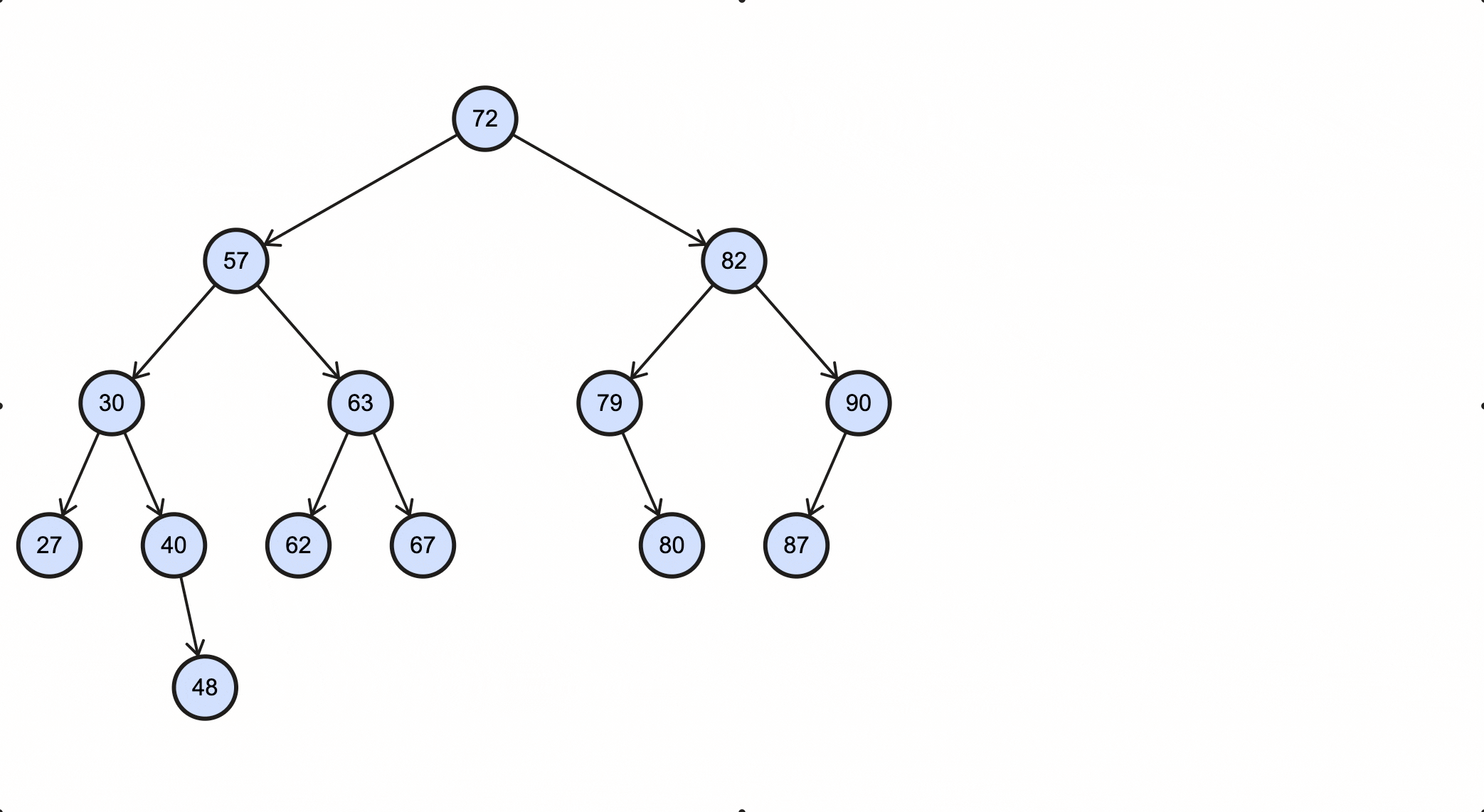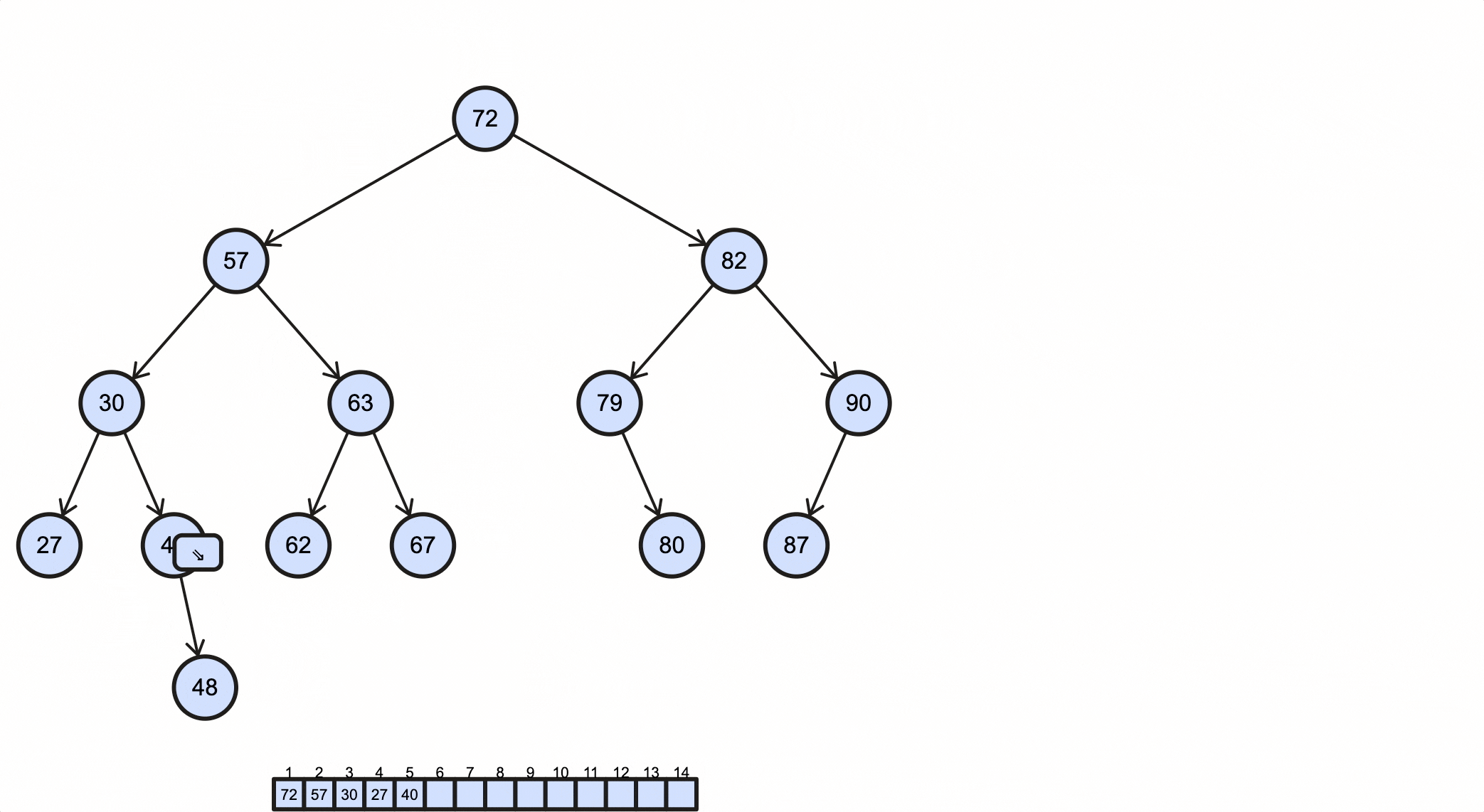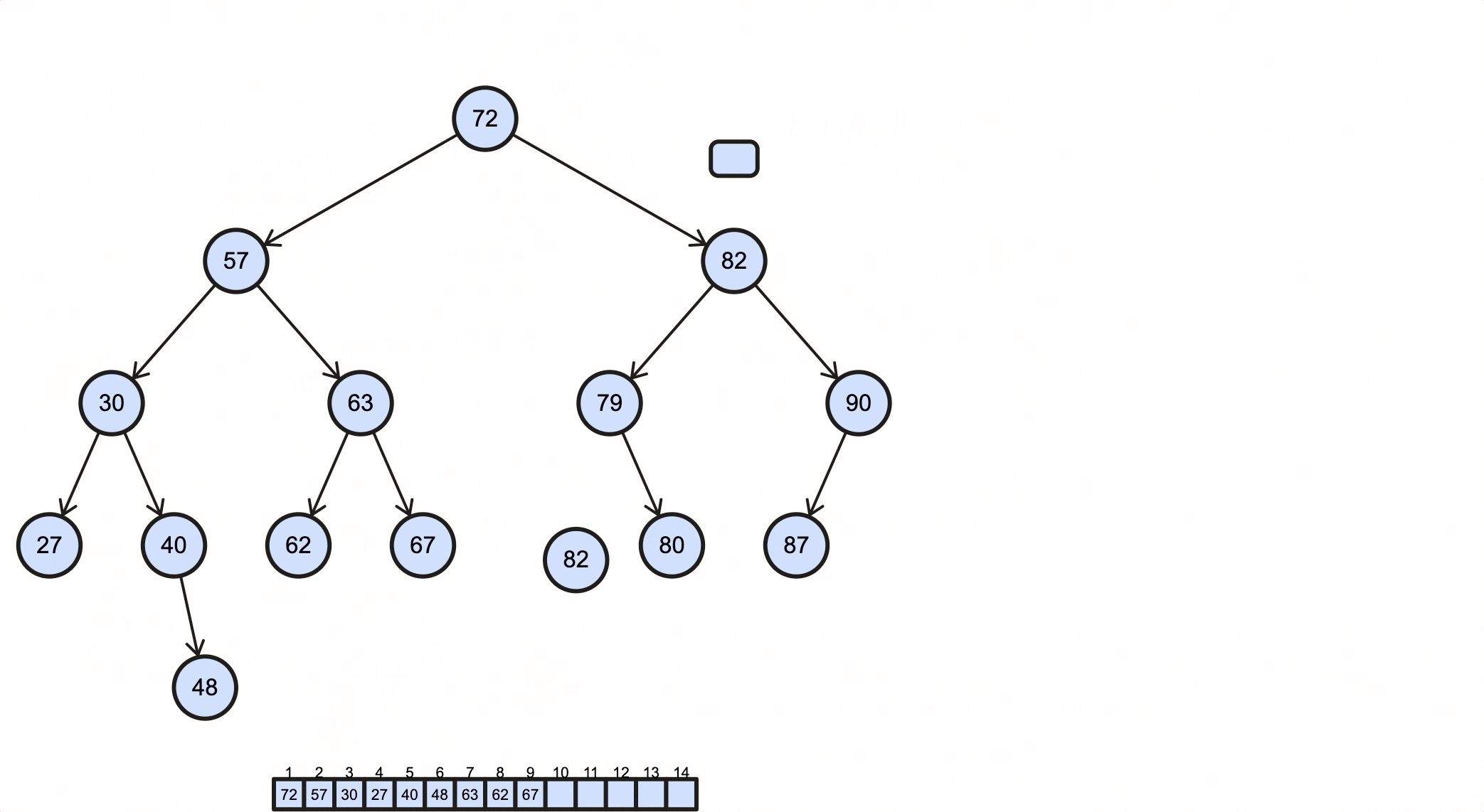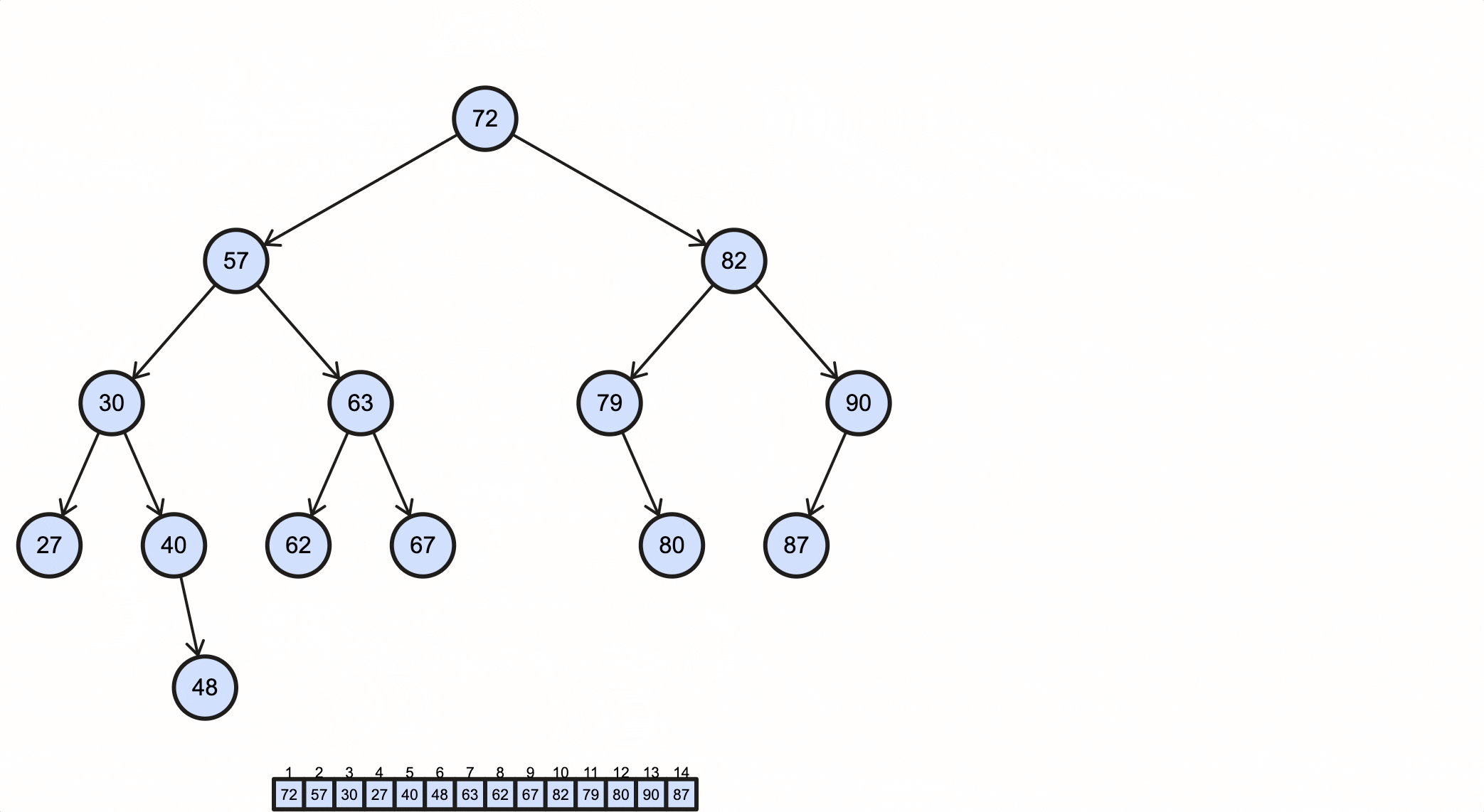
假如我们需要插入一个key为88的节点,需要经过如下步骤:
当key重复时,可以选择覆盖或者忽略,这由业务决定。
上述过程动态图如下所示:
Java代码实现如下:
1 | /** BST */ |
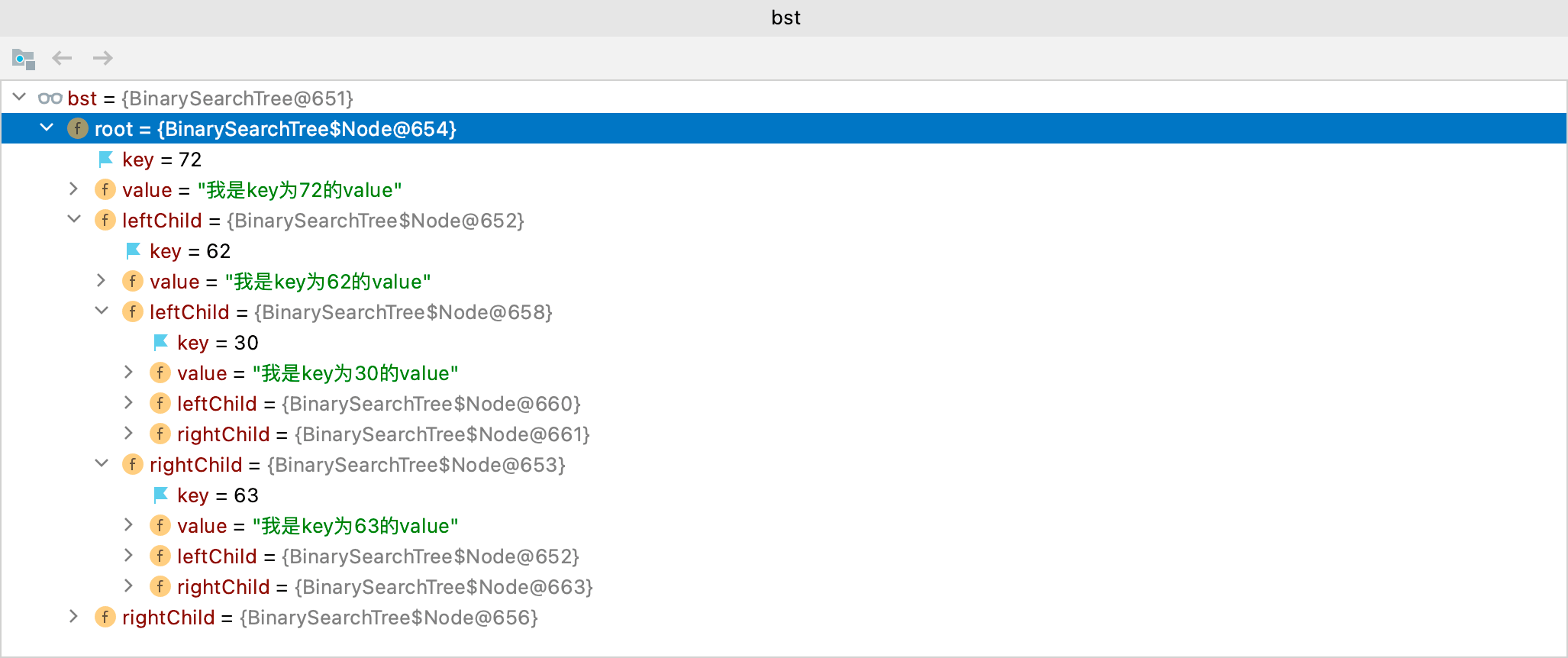
编写测试程序:
1 |
|
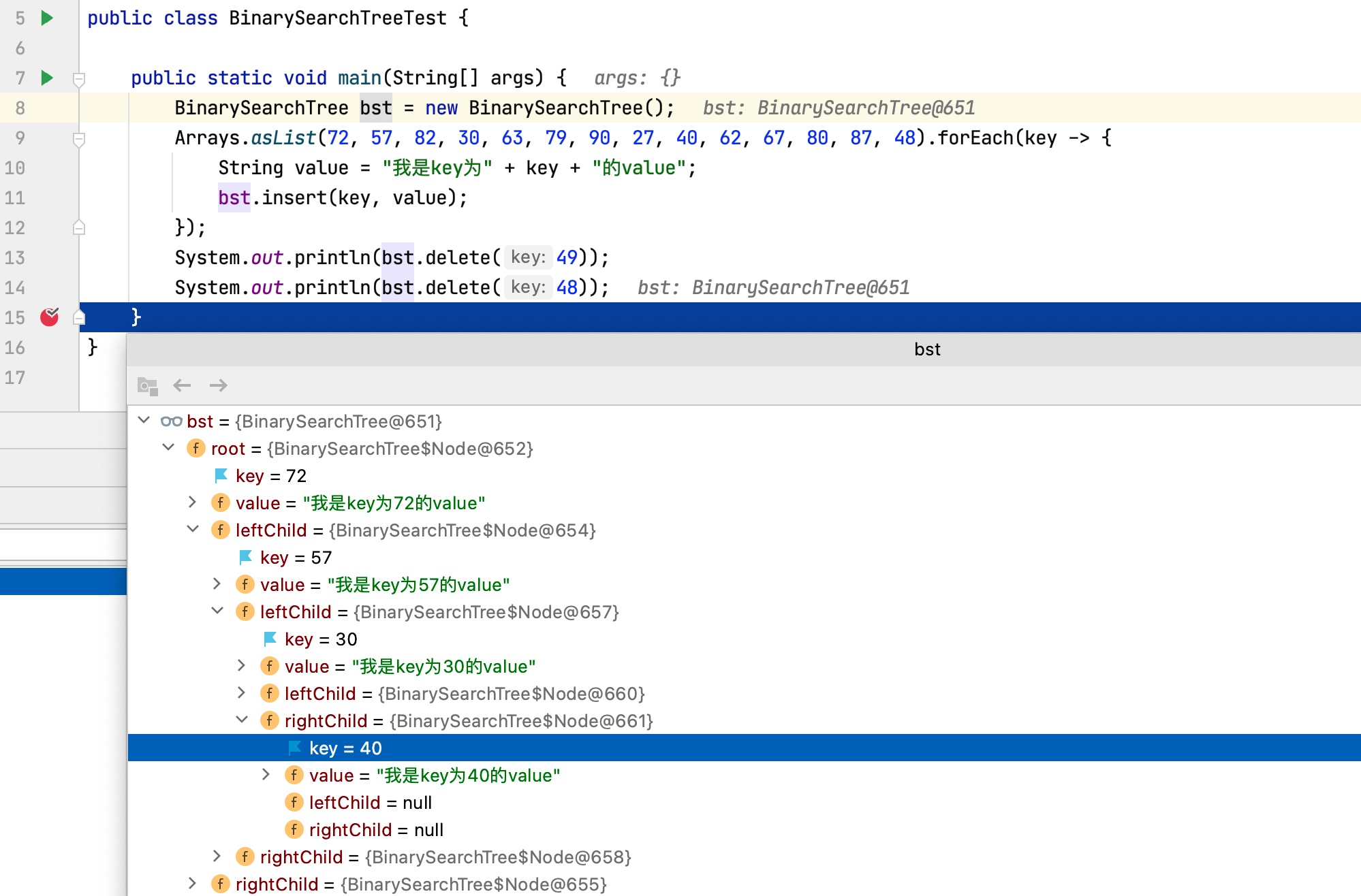
以debug的方式运行程序,查看bst结构:
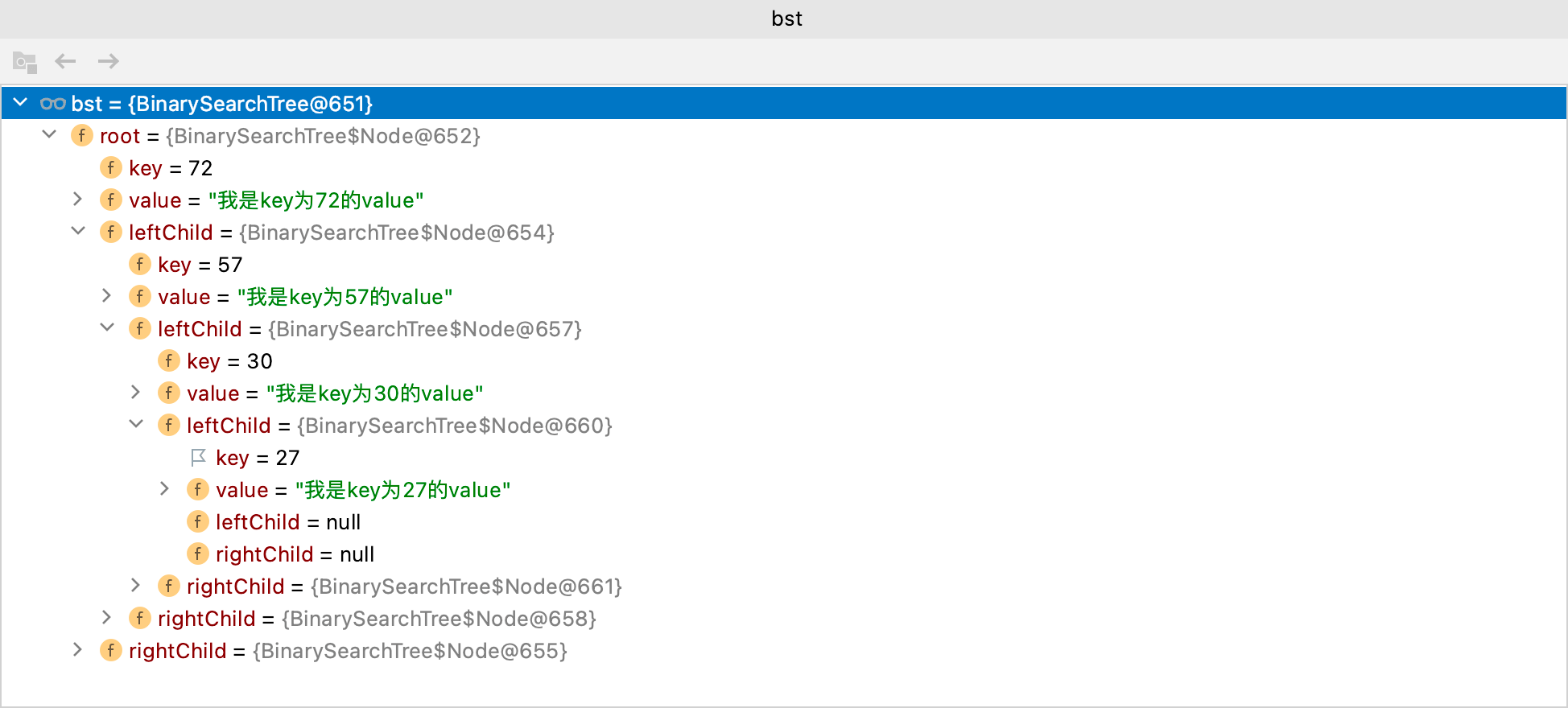
bst结构和上图一致,有兴趣可以自己验证。
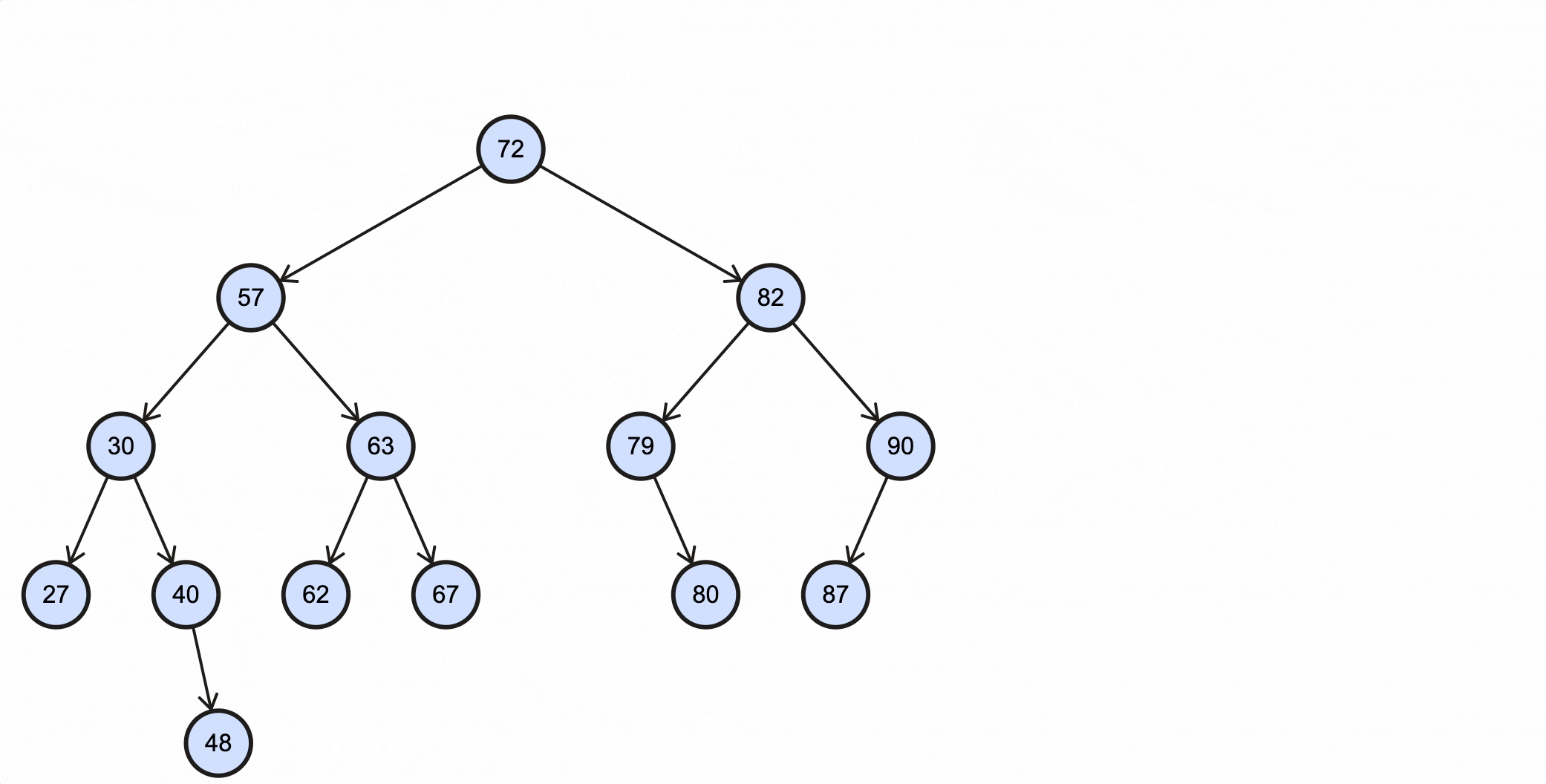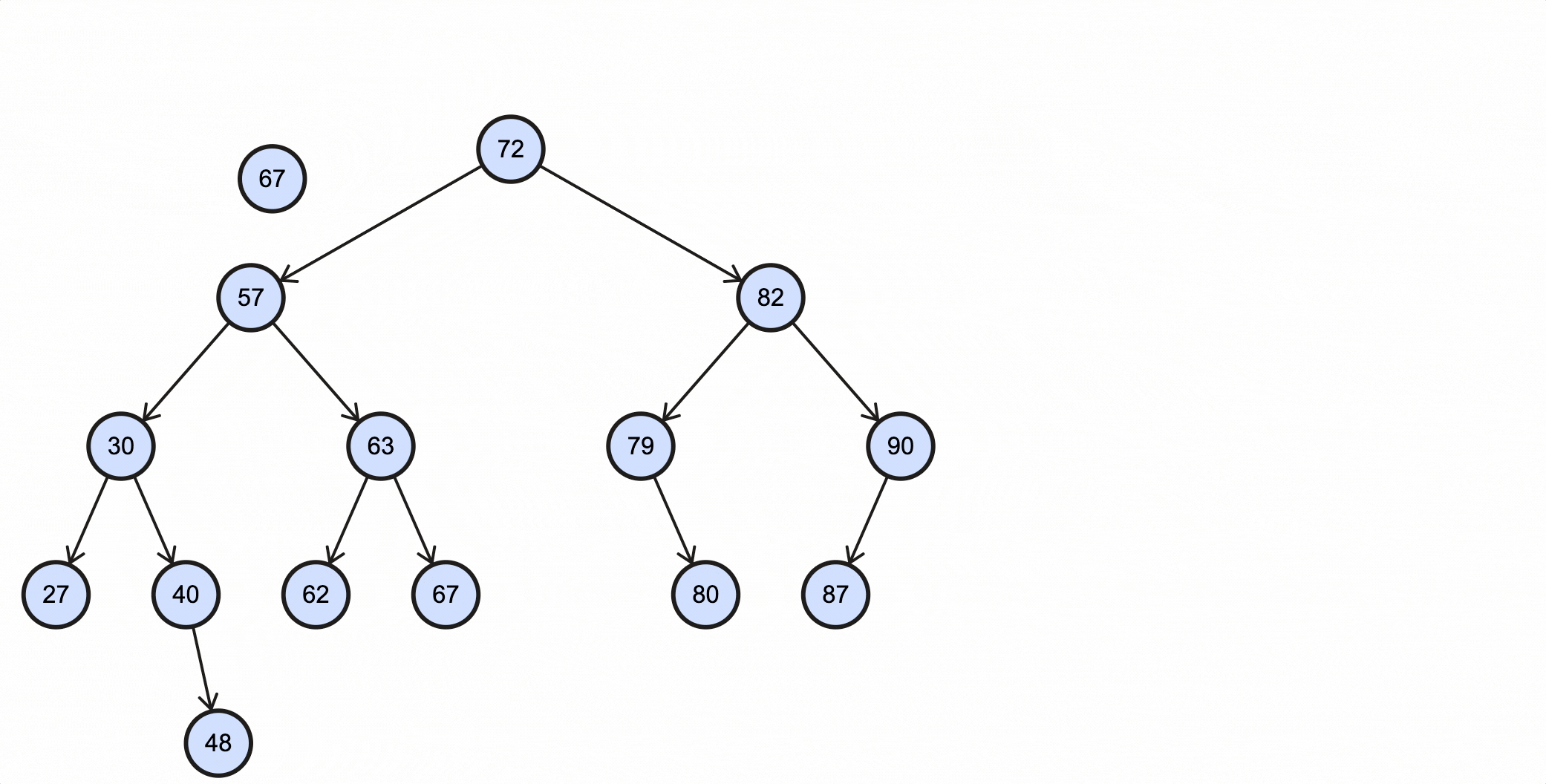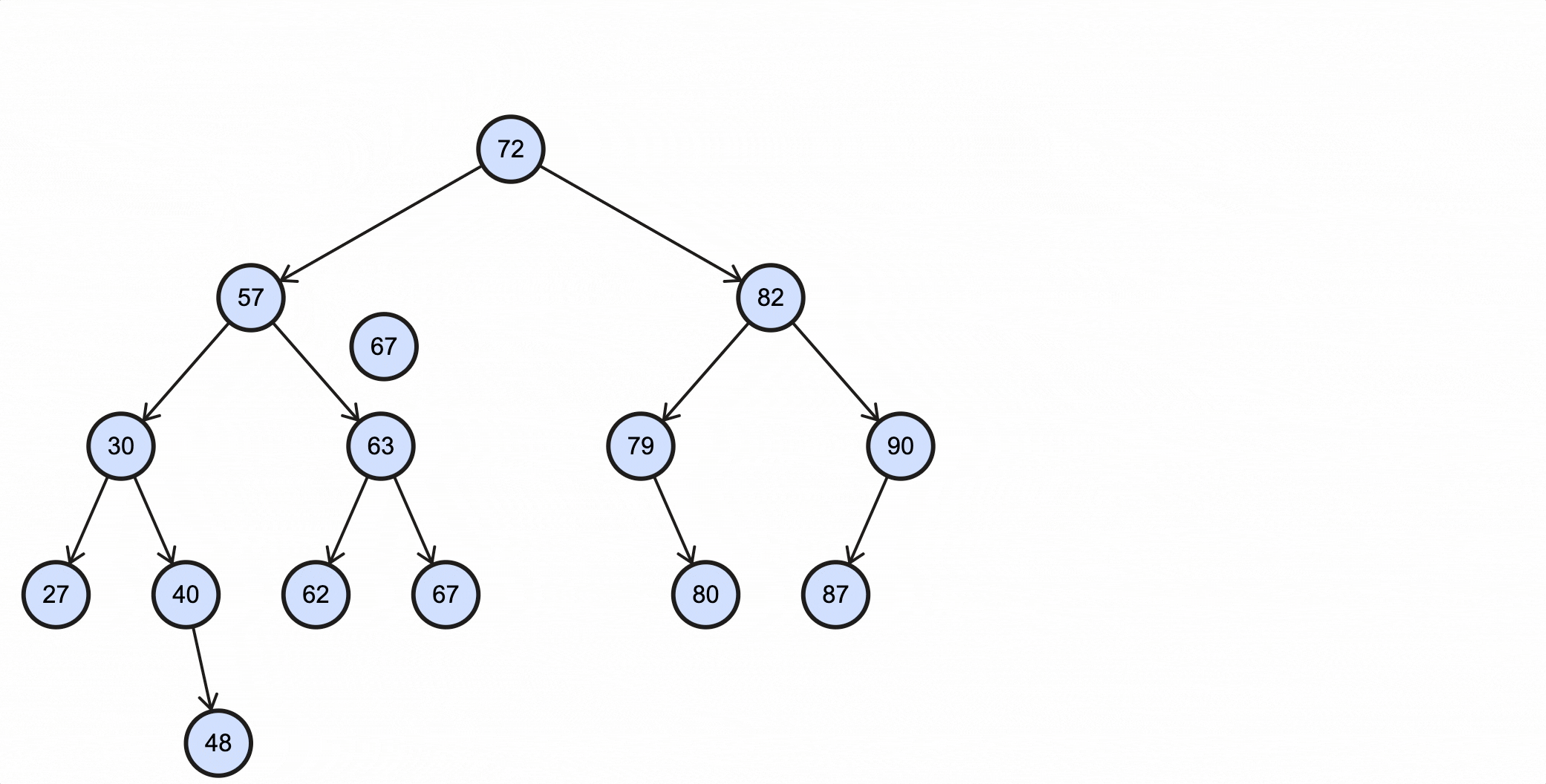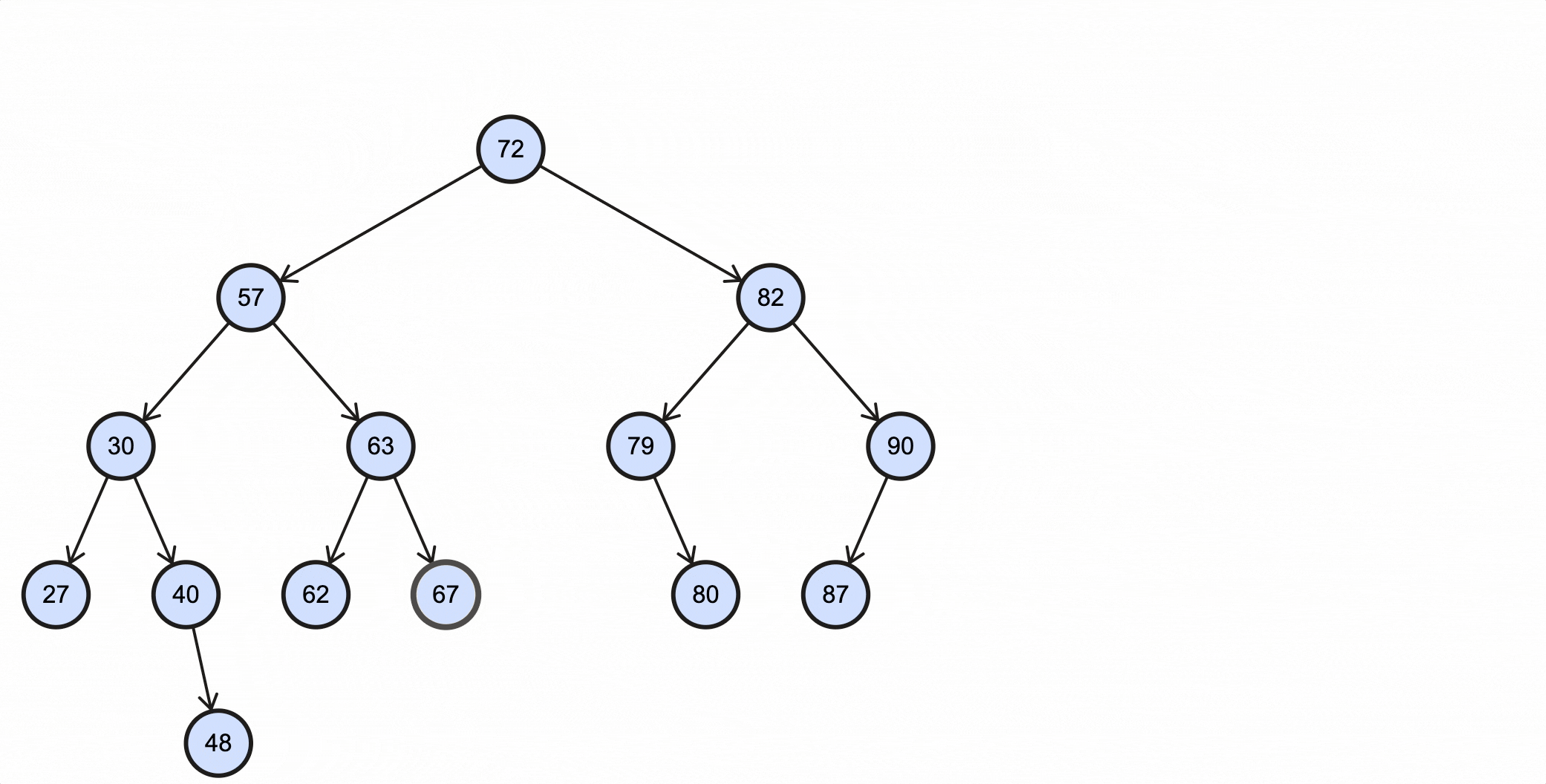
假如我们需要查找key为67的节点,需要经过如下步骤:
上述过程动态图如下所示:
Java代码实现如下:
1 | /** BST */ |
编写测试程序:
1 | public class BinarySearchTreeTest { |
输出如下:
1 | 我是key为87的value |
在BST里查找最大值和最小值是非常容易的一件事,根据BST特性,小的值都分布在左节点,大的值都分布在右节点,所以最小值查找方法为:从根节点出发,一直往下查找左子节点,当该节点不再有左子节点时,该节点就是最小节点;最大值查找方法为:从根节点出发,一直往下查找右子节点,当该节点不再有右子节点时,该节点就是最大节点。
查找最小值图示:
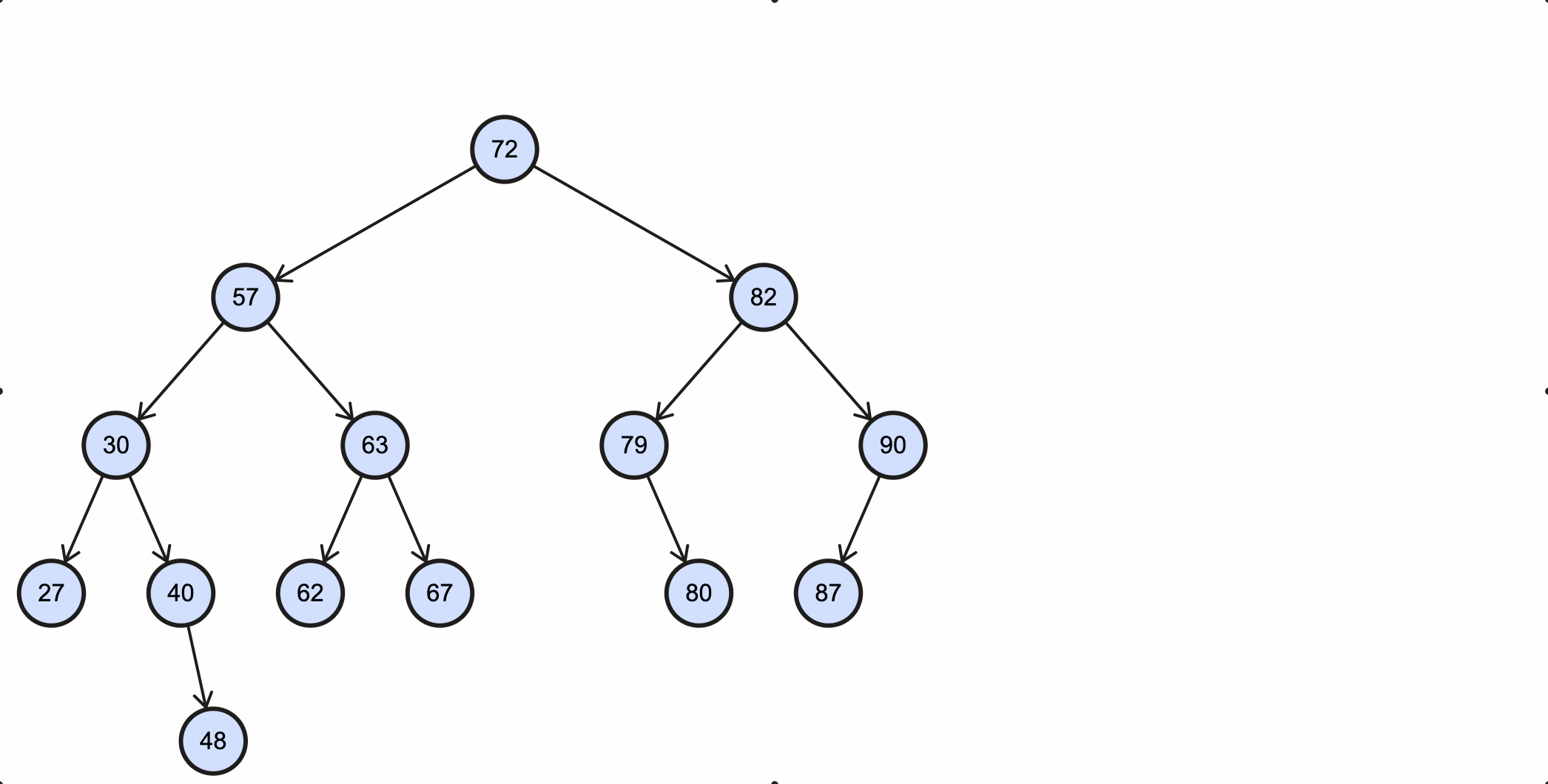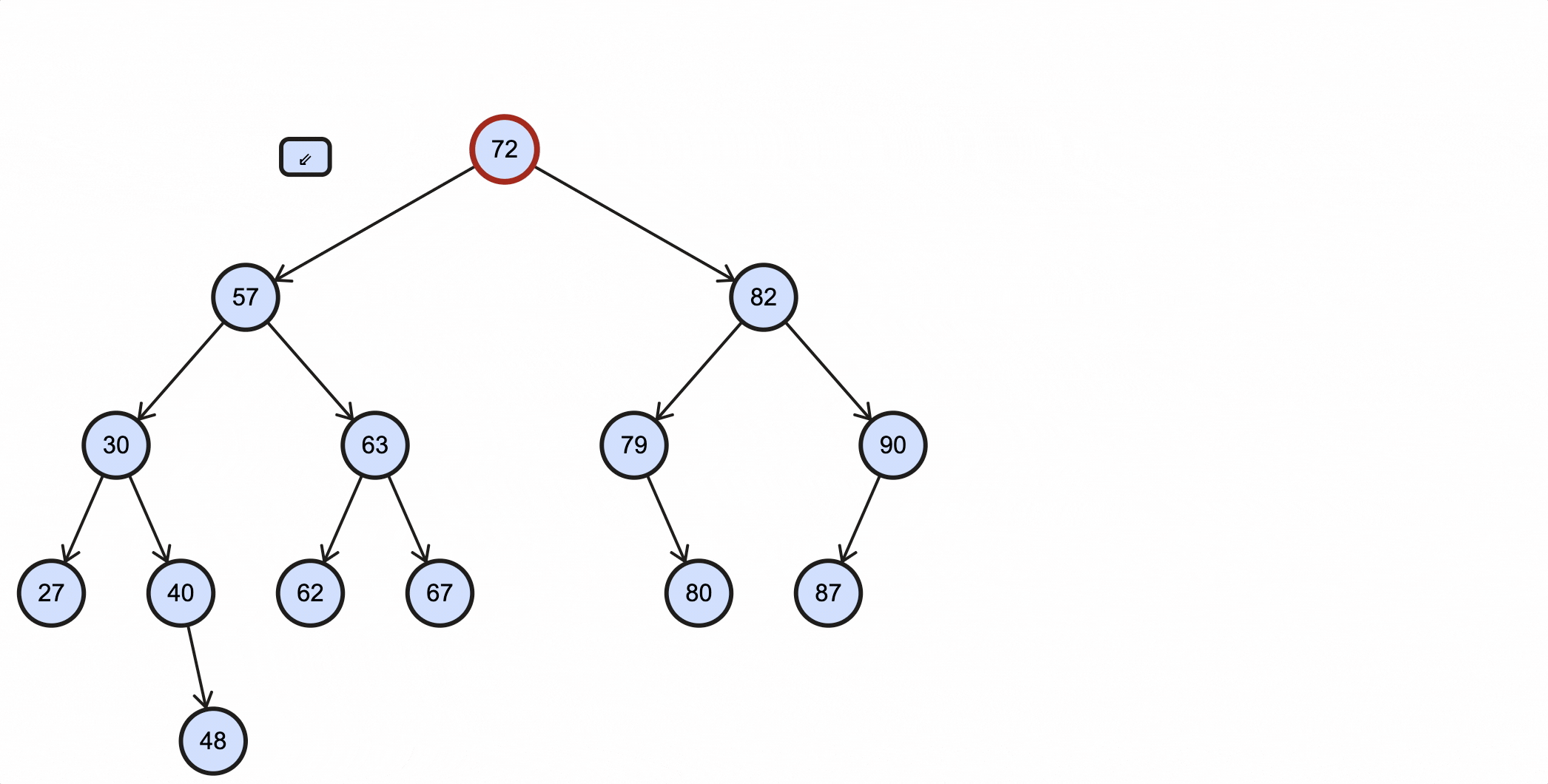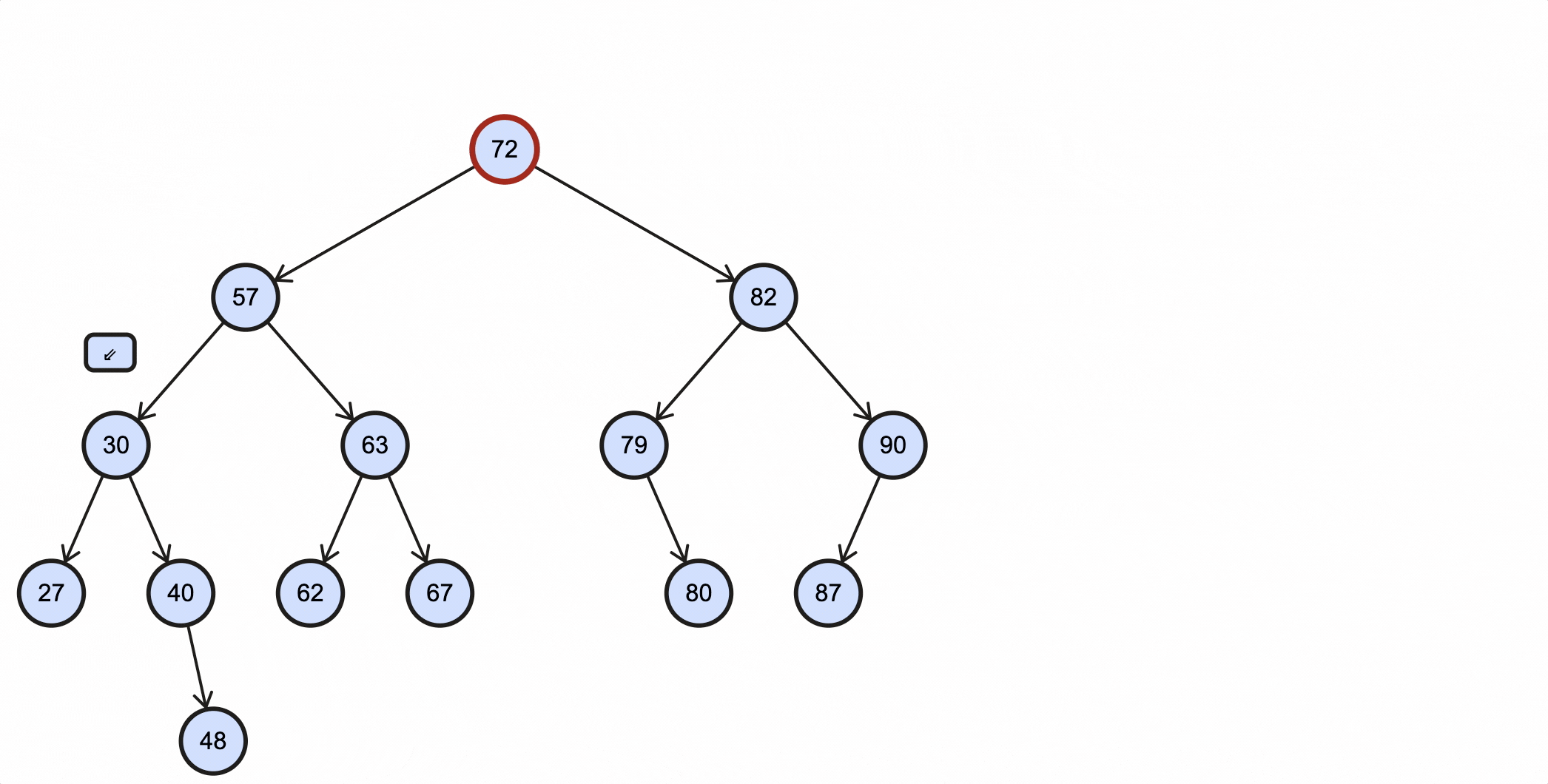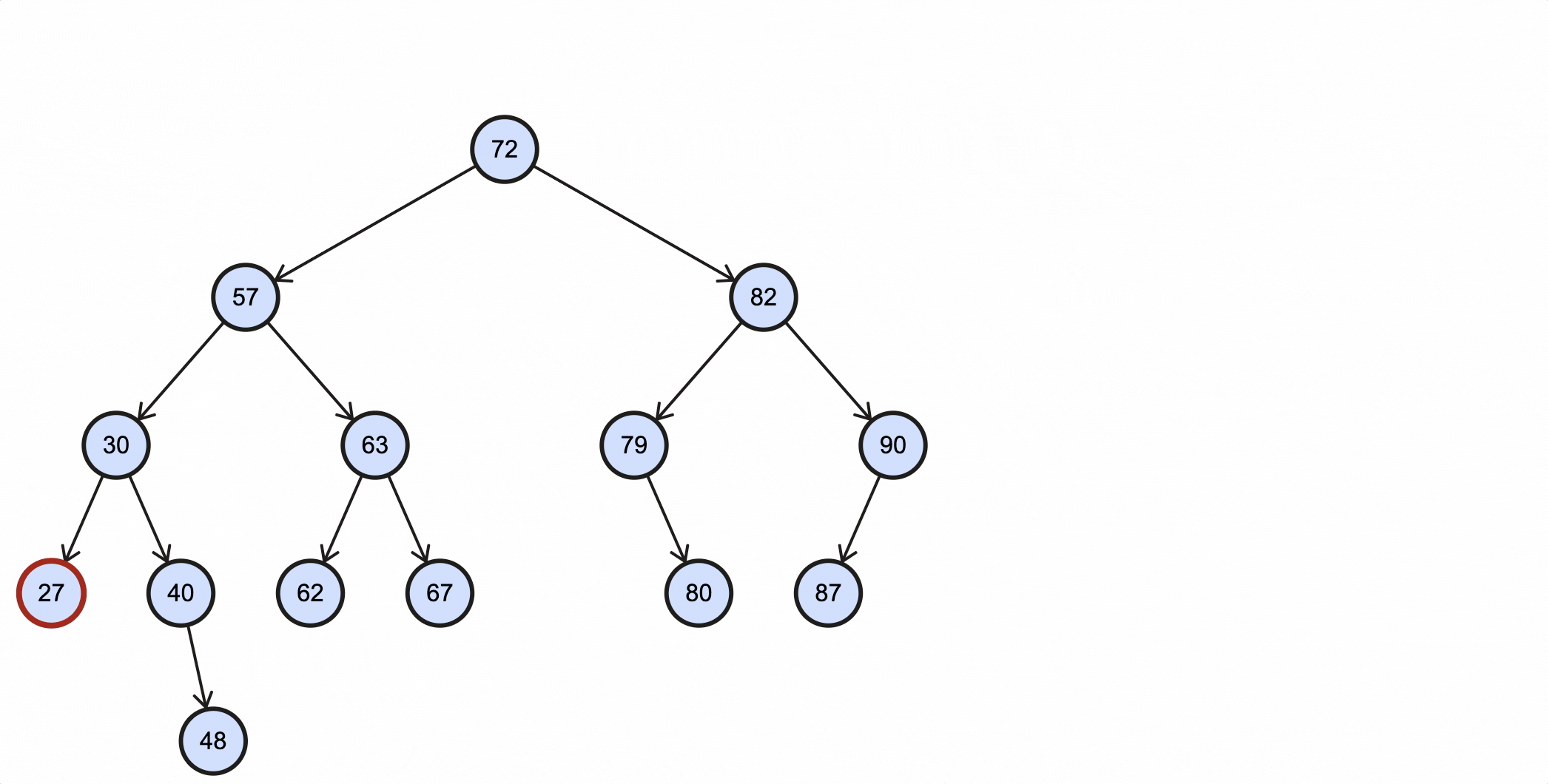
查找最大值图示:
Java代码实现如下:
1 |
|
编写测试程序:
1 | public class BinarySearchTreeTest { |
输出如下所示:
1 | 我是key为27的value |
删除是BST操作里最复杂的一个,因为需要考虑的因素比较多:
下面我们逐个分析:
这种情况最为简单,删除节点前需要先找到该节点,过程和上面的查找类似。找到需要删除的节点后,如果是叶子节点,则将该节点的父节点引用置为null,被删除的节点没了引用,后续由GC自动回收。
假如我们需要删除key为48的节点,需要经过如下步骤:
该过程如下图所示:
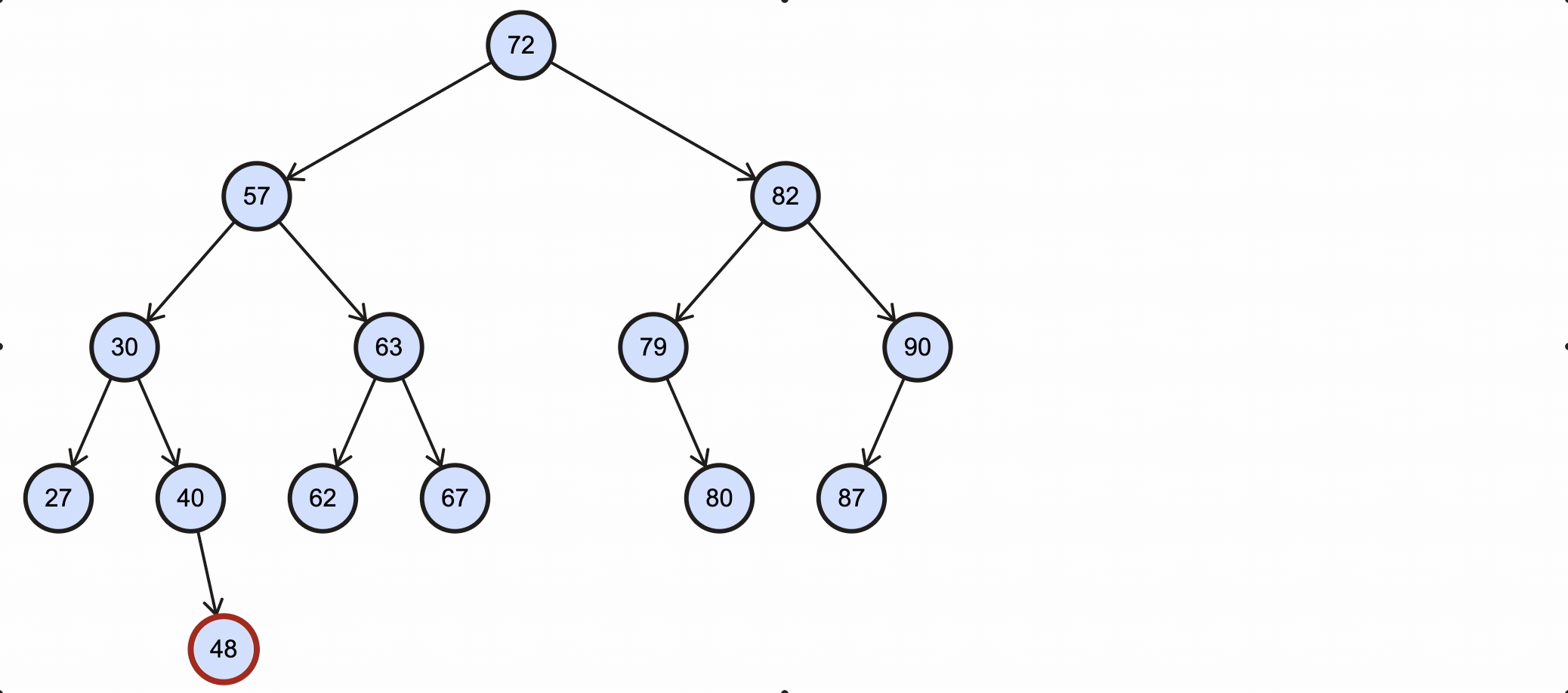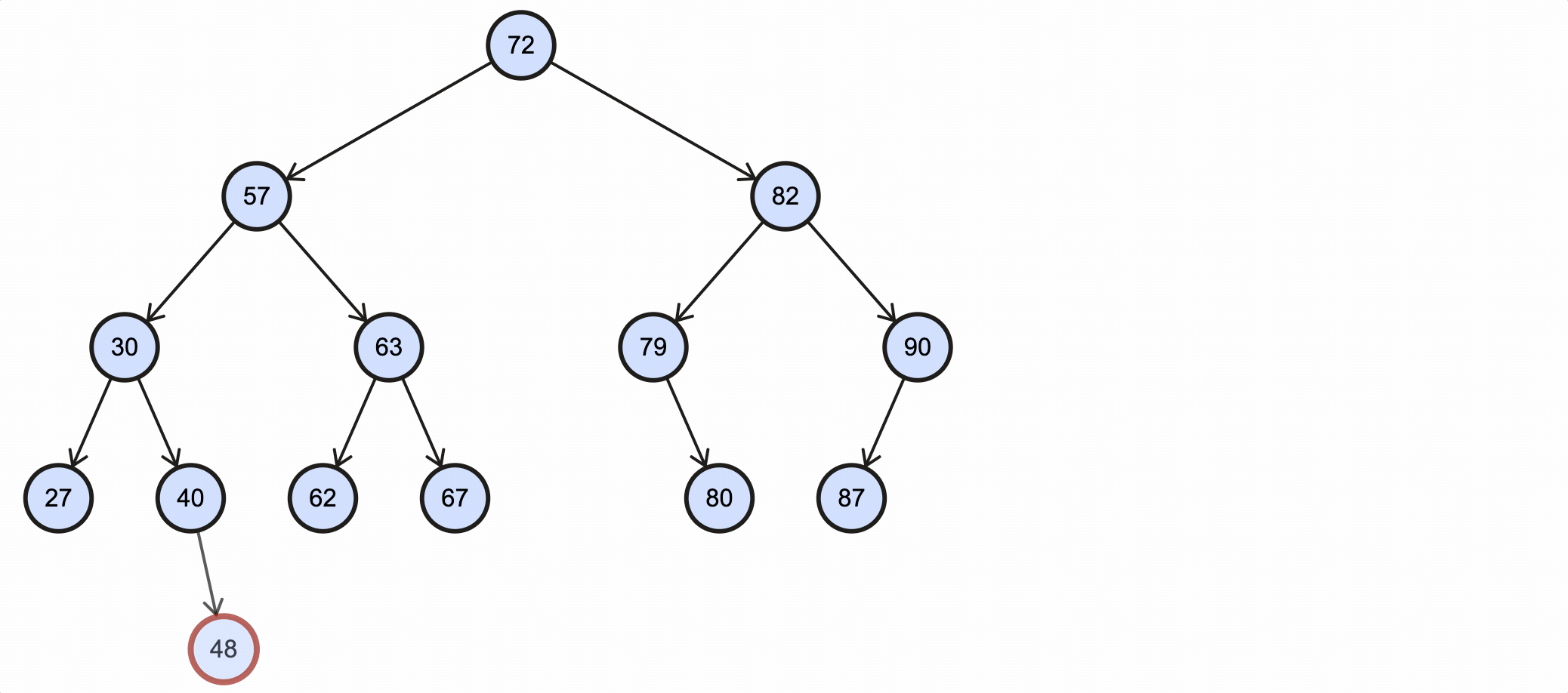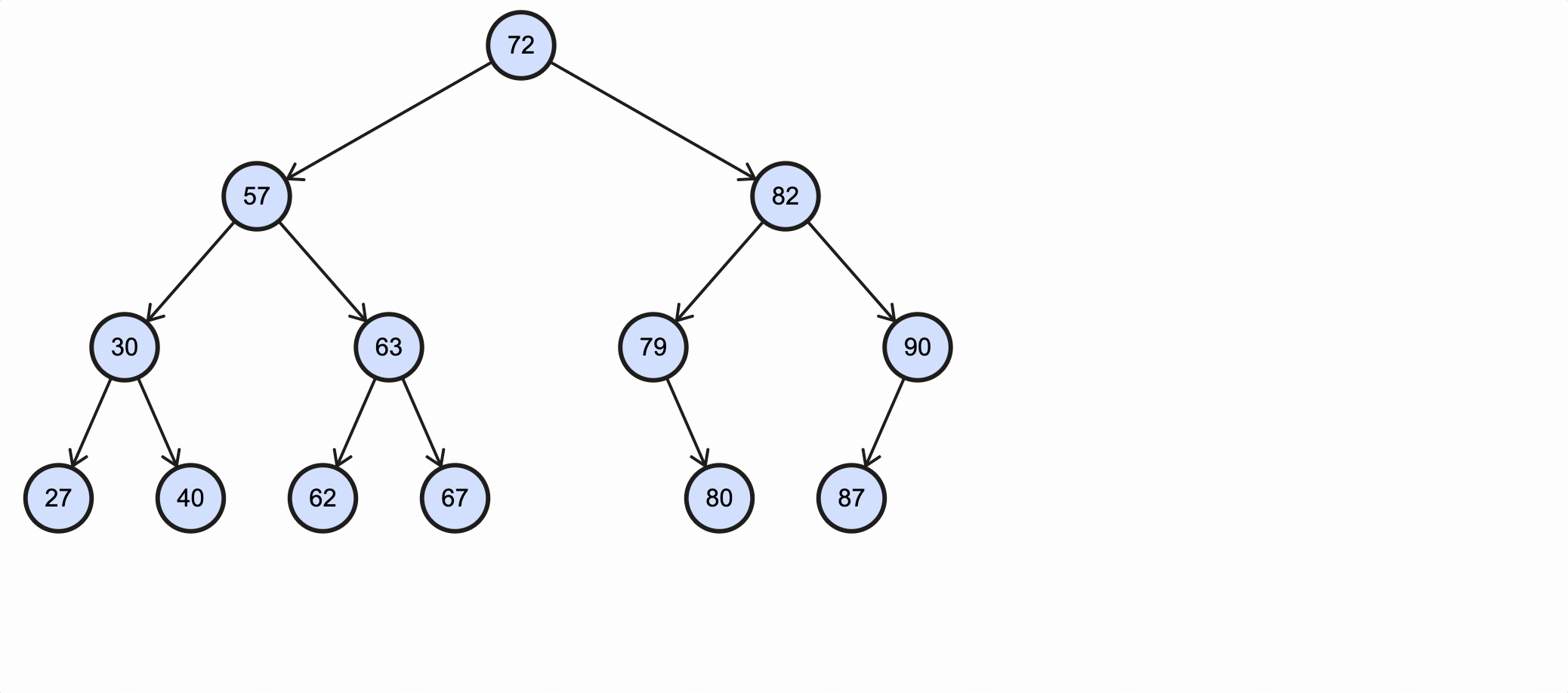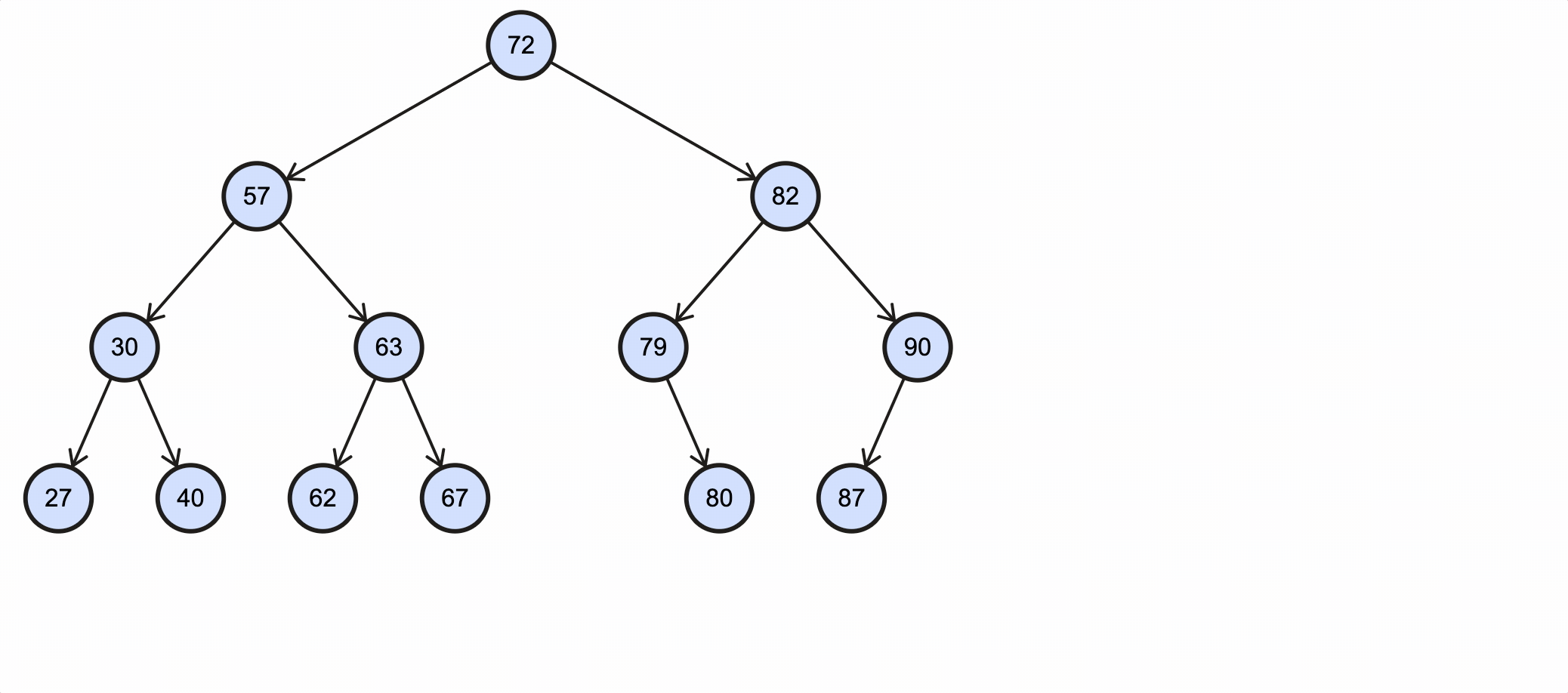
Java代码实现如下:
1 | /** BST */ |
编写测试程序:
1 | public class BinarySearchTreeTest { |
1 | false |
可以看到40的右子节点已经被删除。
这种情况也比较简单,只需要将被删除节点的子节点和其父节点建立连接关系即可。
假如我们需要删除key为79的节点,需要经过如下步骤:
该过程如下图所示:
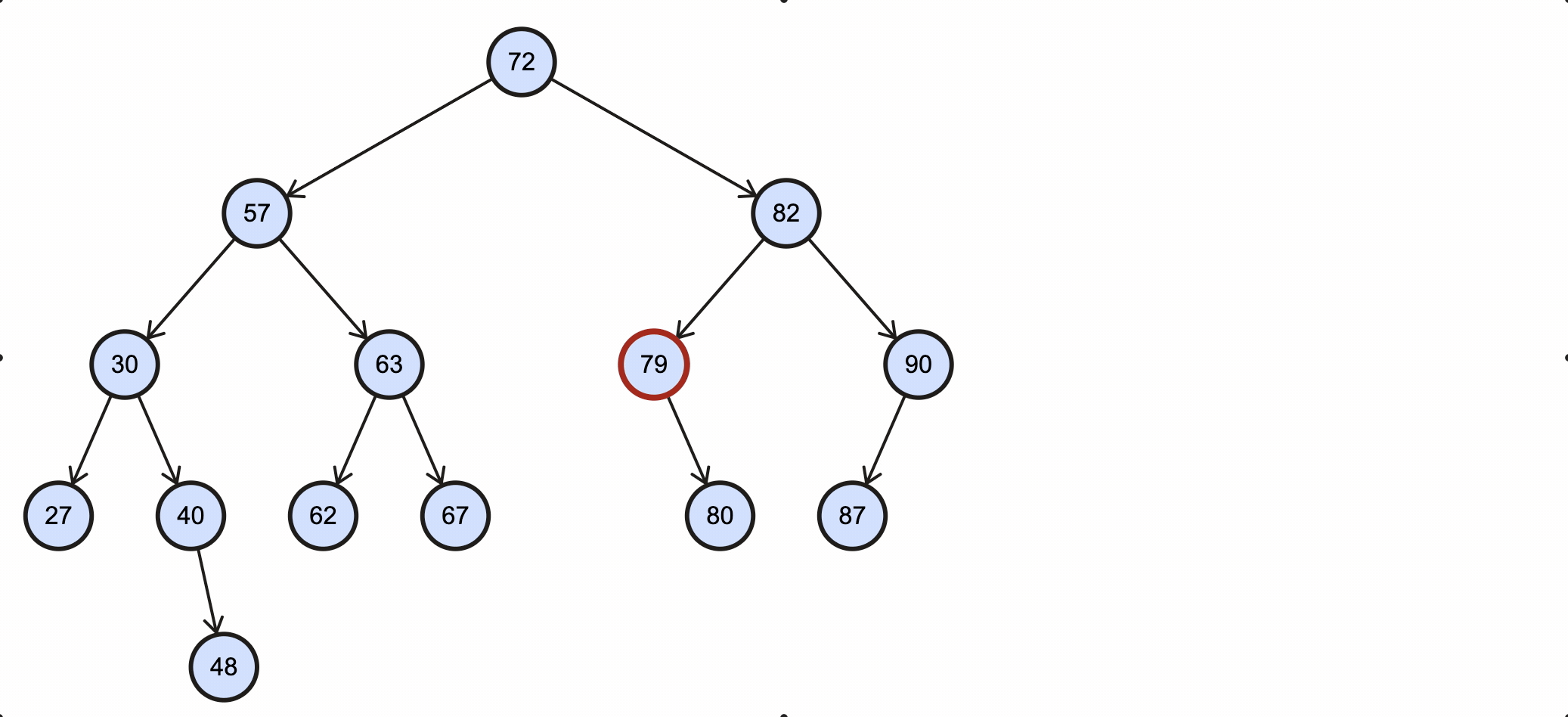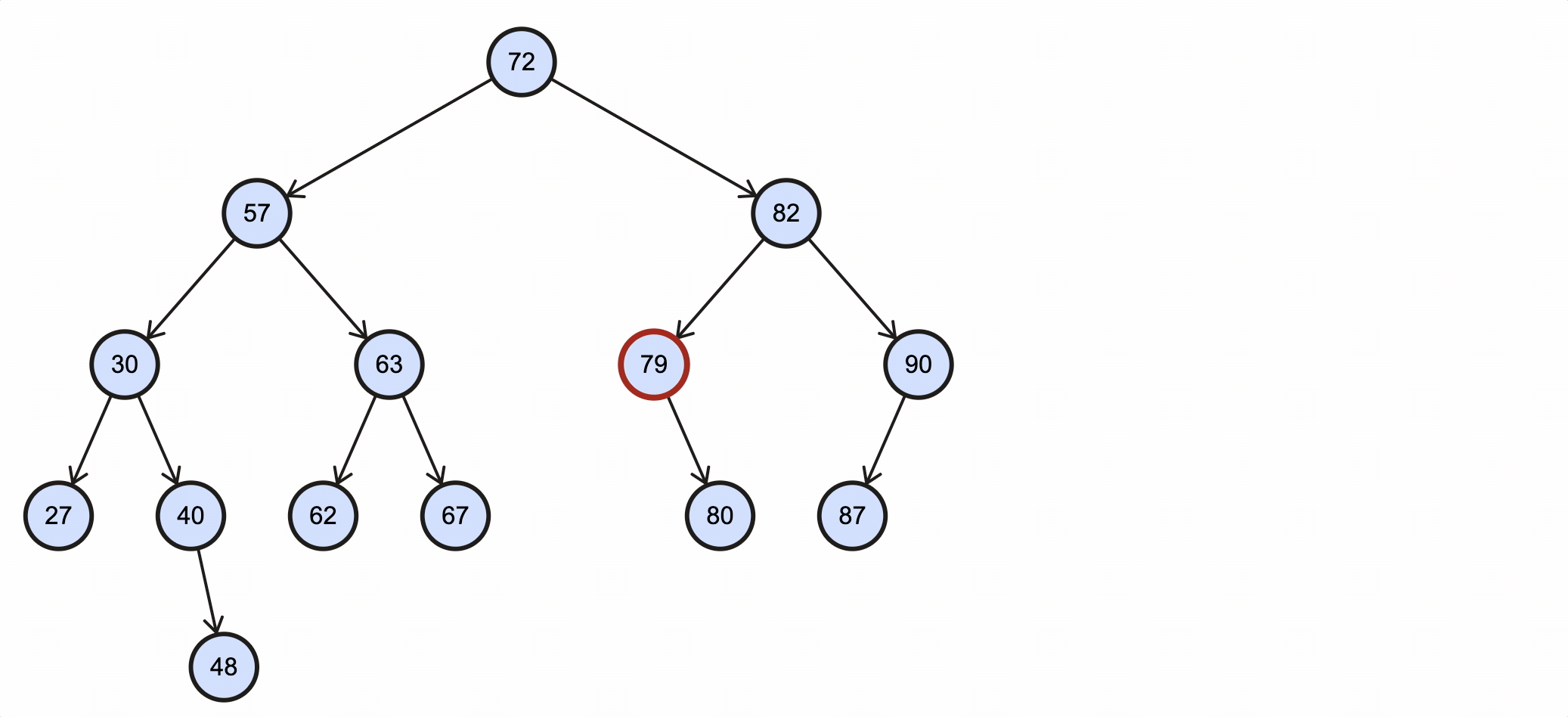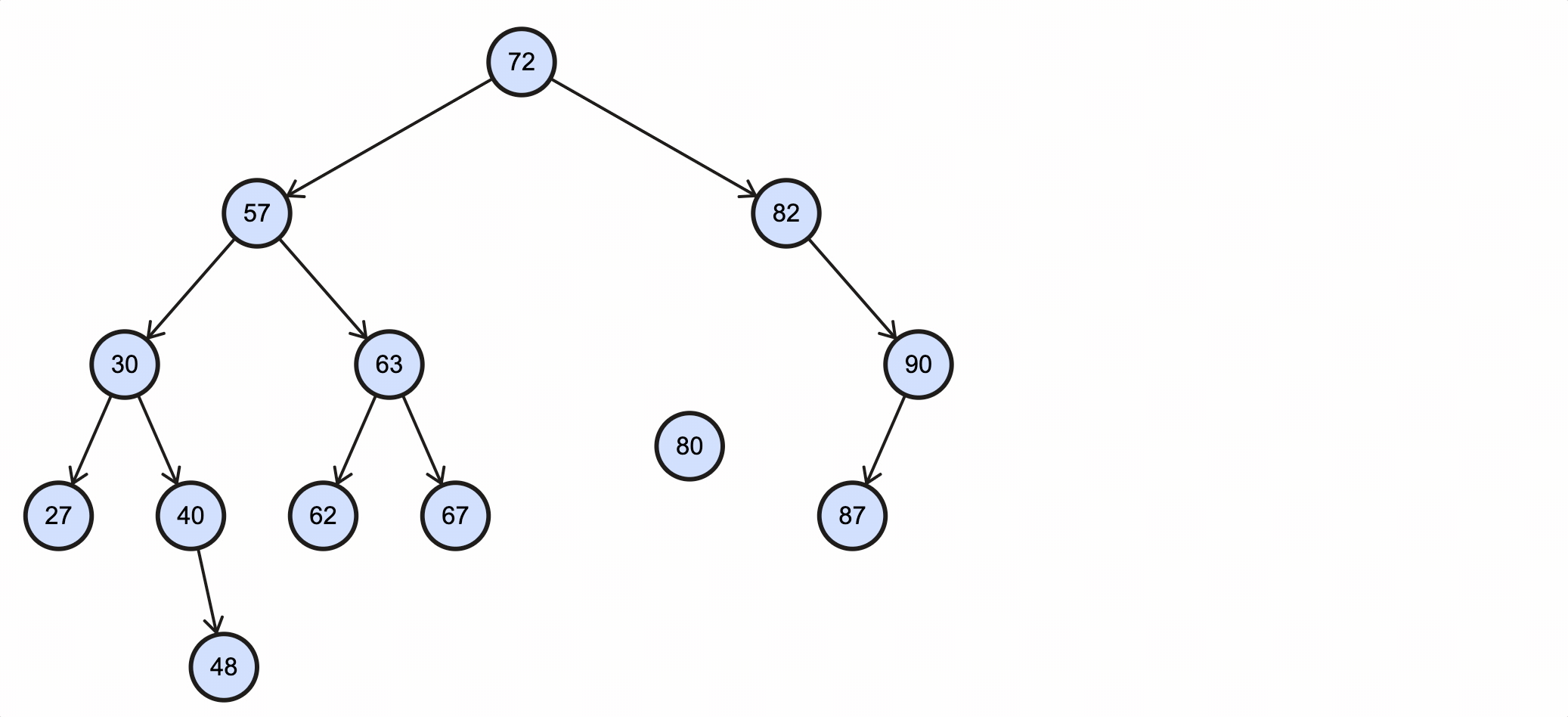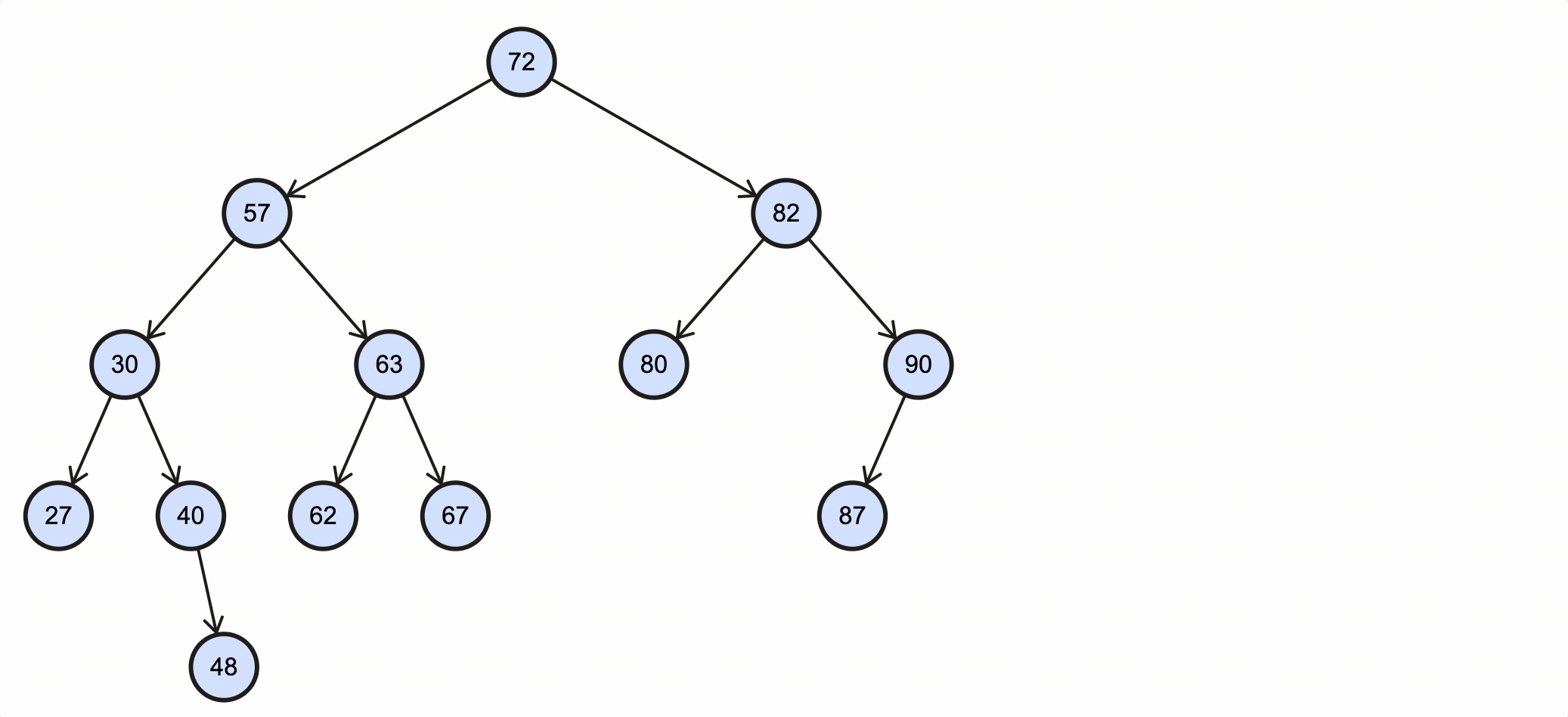
Java代码实现如下:
1 | /** BST */ |
编写测试程序:
1 | public class BinarySearchTreeTest { |
程序输出:
1 | true |
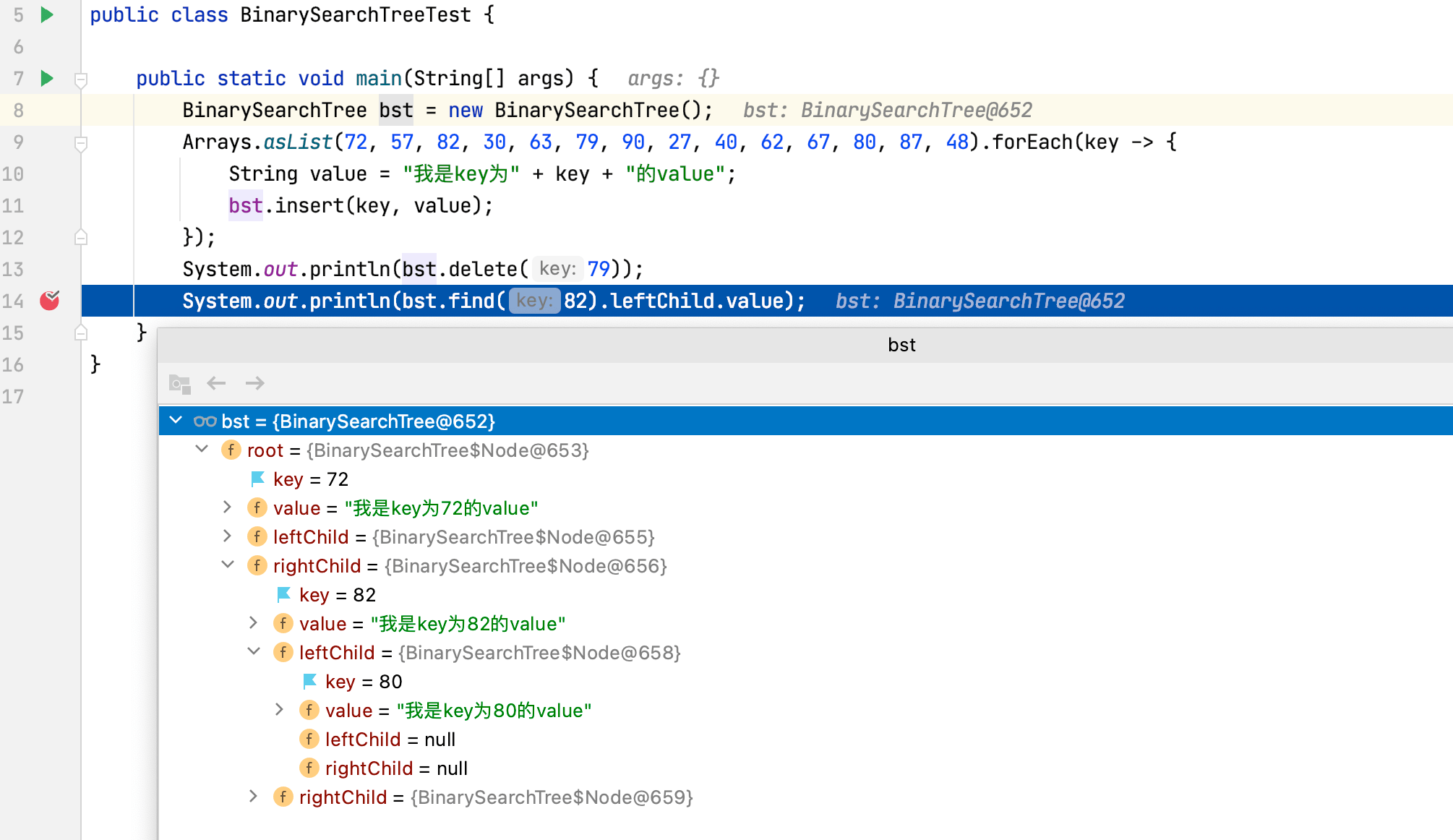
这种情况比较复杂,删除的节点不能用删除节点的某个子节点来代替。比如现在需要删除上述BST的57节点,假如用57节点的右子节点63代替该节点,那么63的左子节点既不能是62,也不能是57的左子节点30。
这种情况下需要找到被删除节点的中序后继节点(successor)来代替它。所谓的中序后继节点就是:整个树中关键字值比被删除节点大,并且比被删除节点右子节点小的那部分节点中的关键字值最小的节点。
根据中序后继节点的定义来看,要找到它也很简单:
举个例子,比如现在需要删除上述BST的57节点,那么它的中序后继节点为62;假如要删除的节点为63,那么它的中序后继为67:
当删除的节点为57时,过程如下所示:
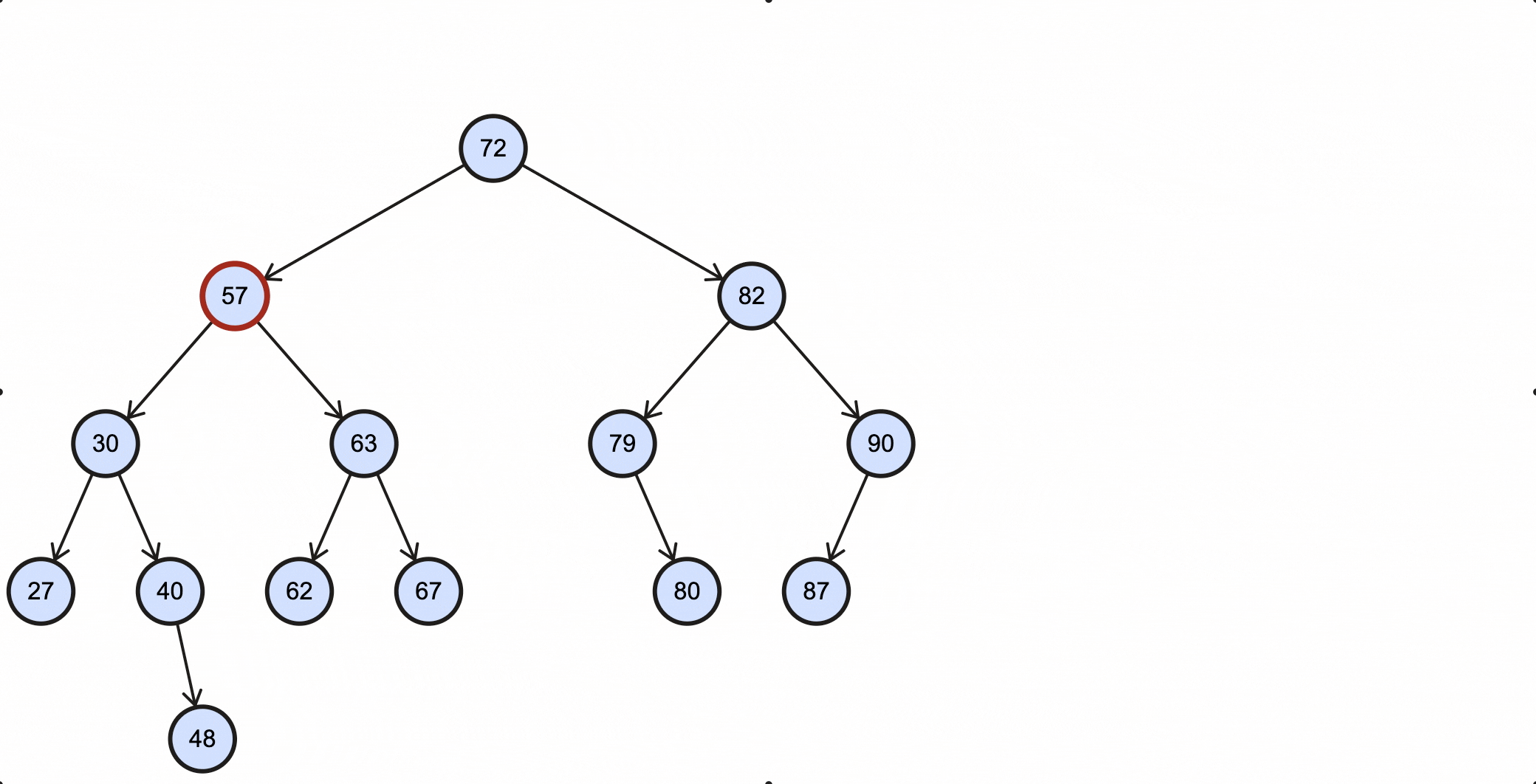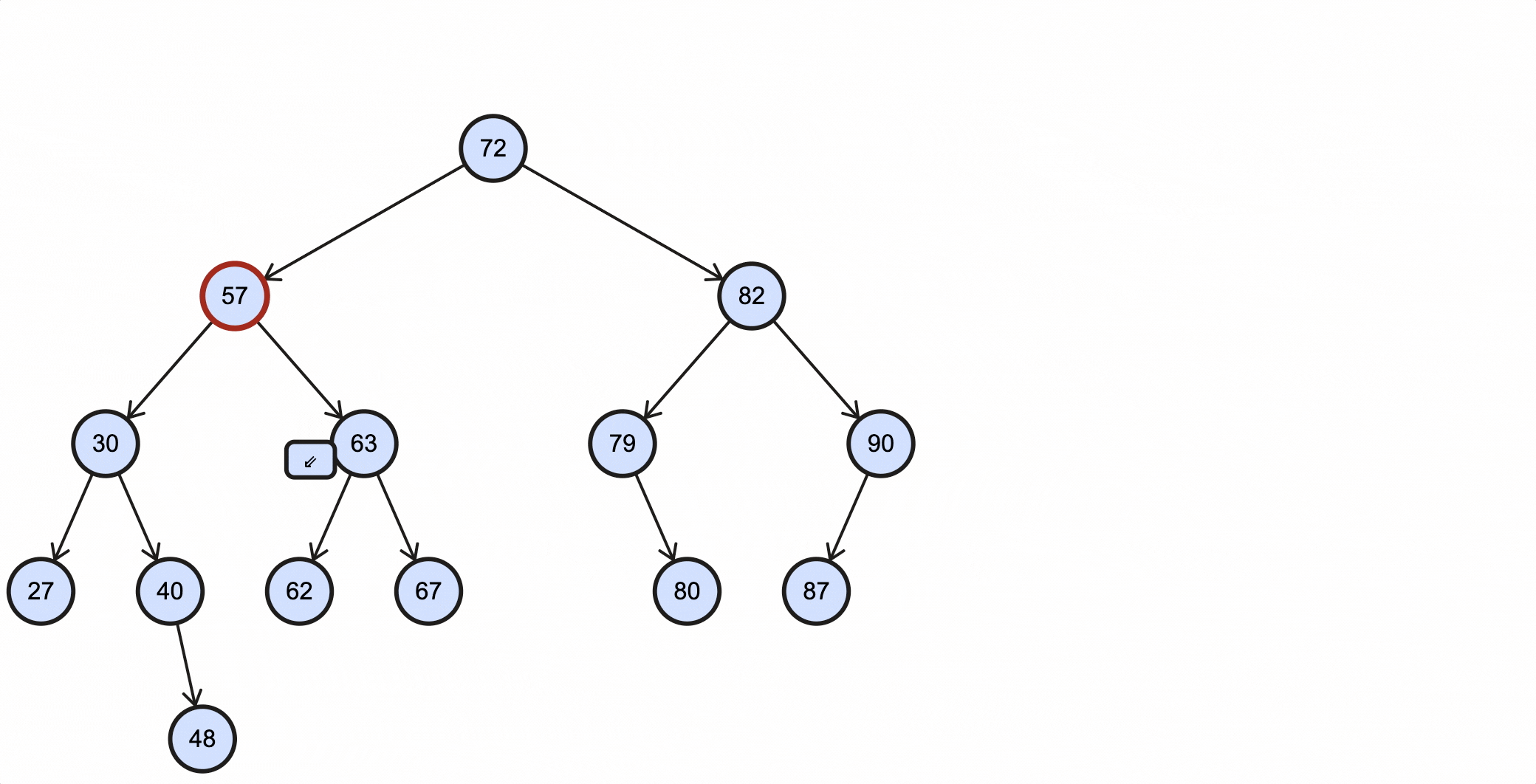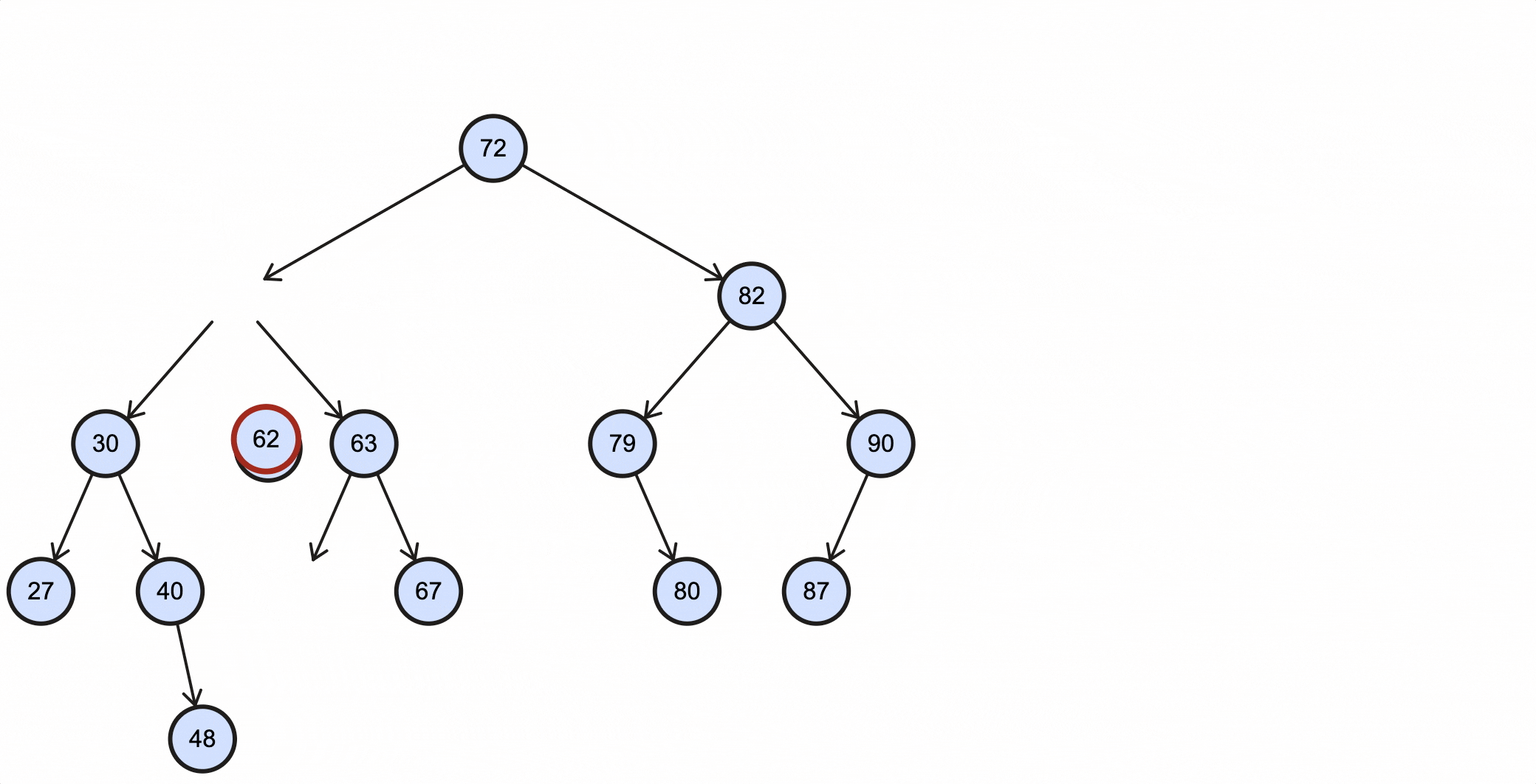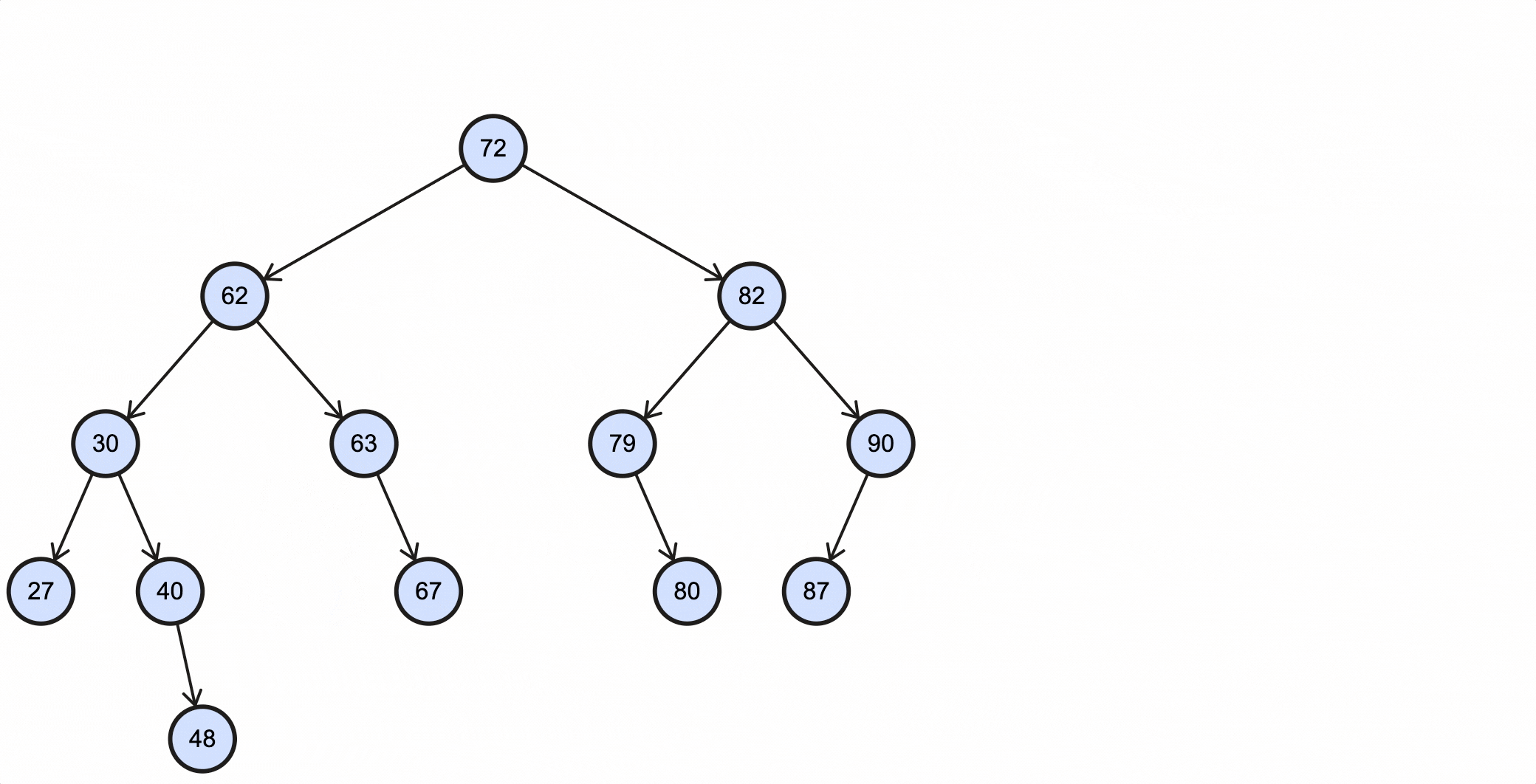
当删除的节点为63时,过程如下所示:
编写查找中序后继节点的方法:
1 | /** BST */ |
完成删除方法的最后一个部分:
1 | /** BST */ |
编写测试程序测试一下:
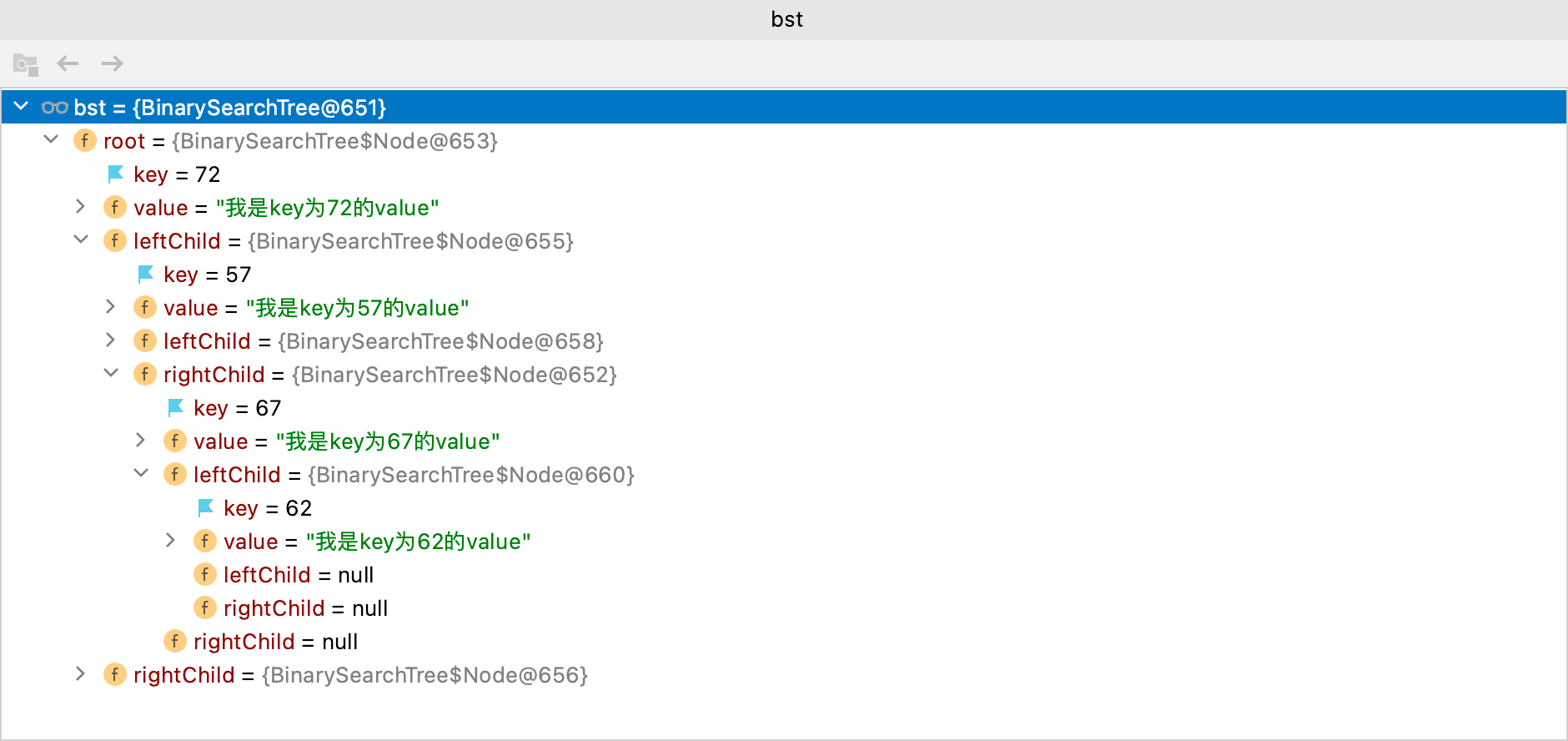
当删除的节点为57时:
1 | public class BinarySearchTreeTest { |
输出如下:
1 | 删除57节点: true |
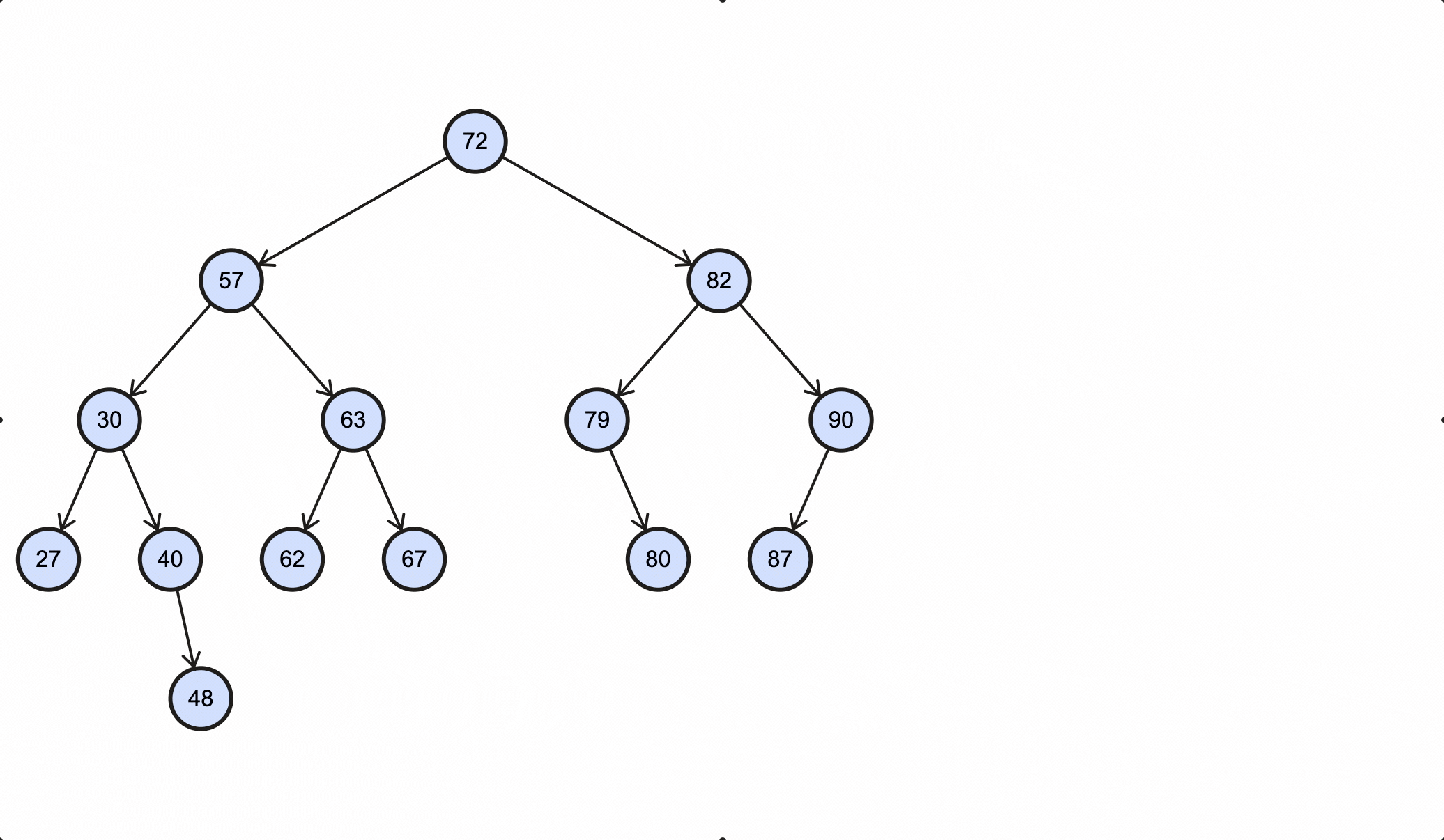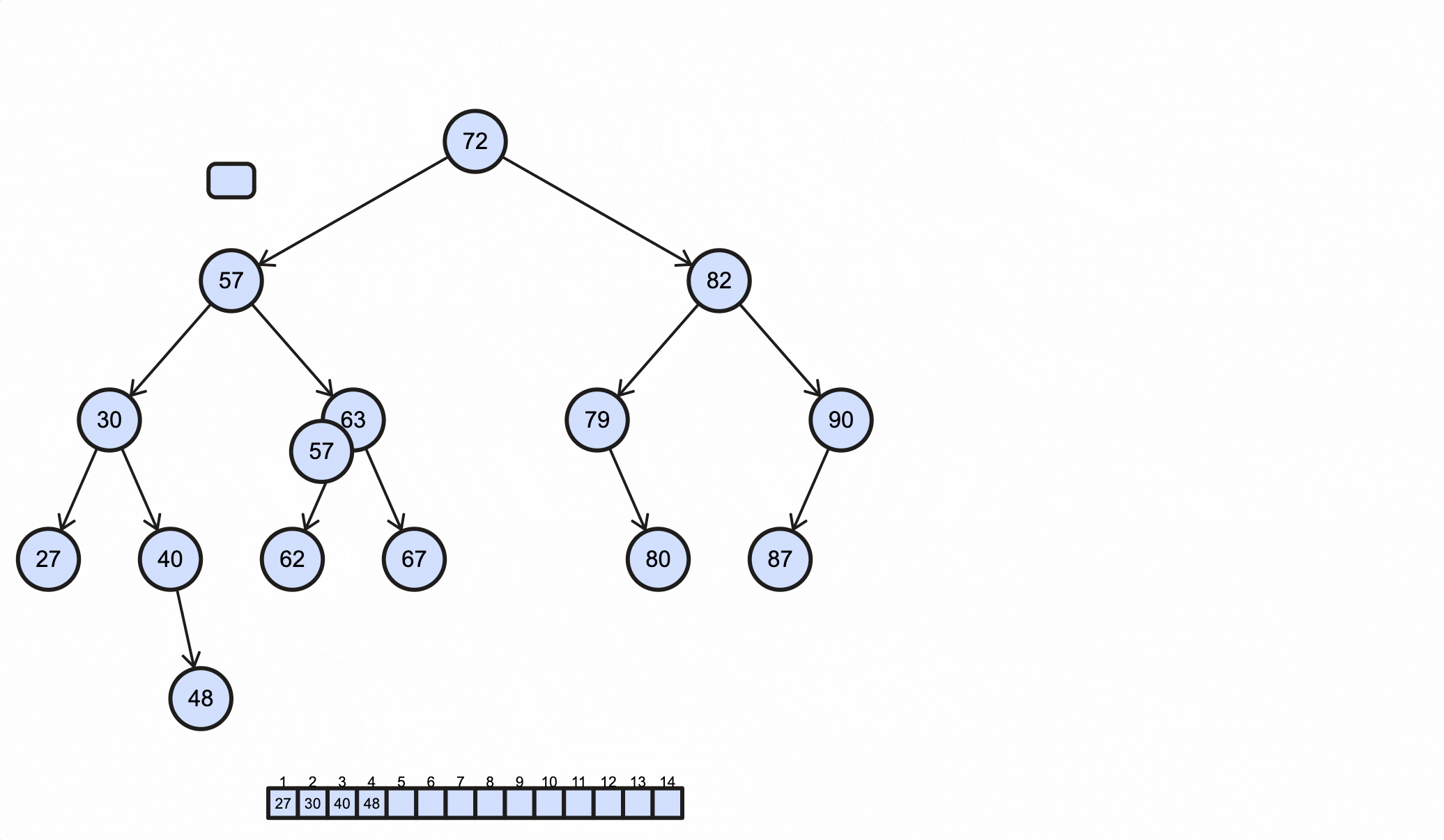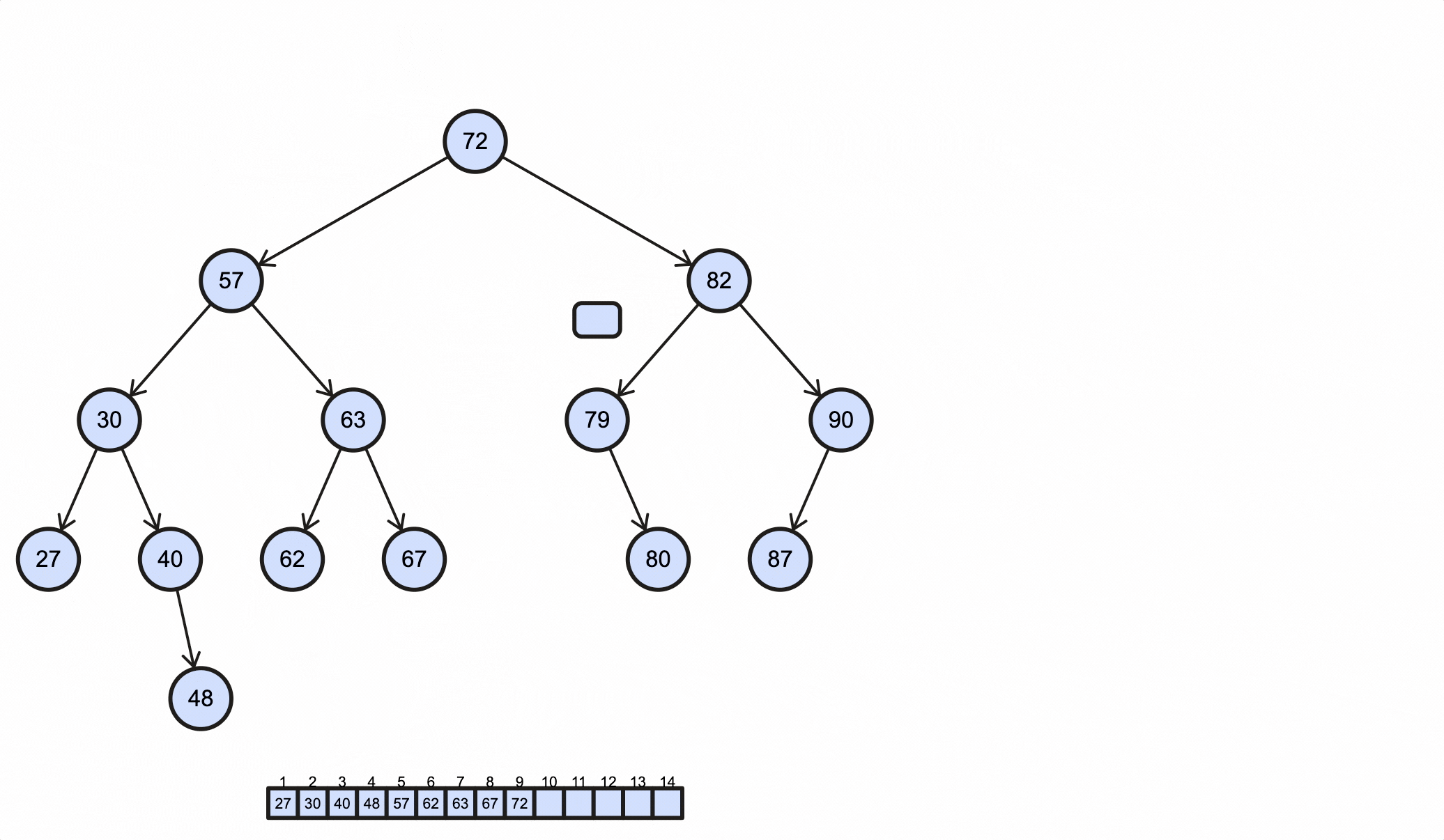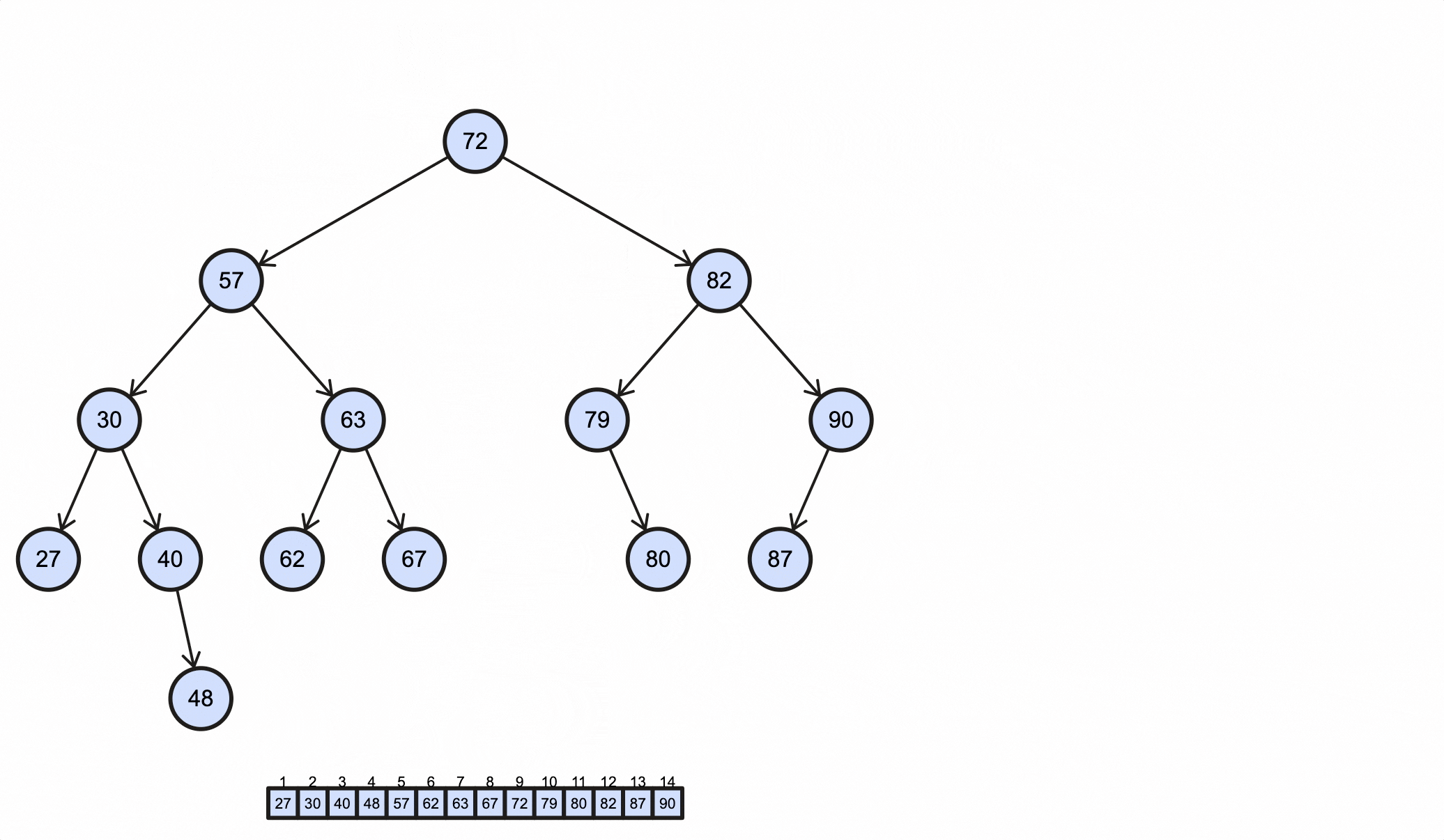
当删除的节点为63时:
1 | public class BinarySearchTreeTest { |
输出如下:
1 | 删除63节点: true |
遍历树指的是以一种特定顺序访问树的每一个节点,这个顺序分为:中序、前序和后序。
中序遍历的步骤为:
Java实现如下:
1 | /** BST */ |
编写测试程序:
1 | public class BinarySearchTreeTest { |
输出如下:
1 | 27 30 40 48 57 62 63 67 72 79 80 82 87 90 |
这个过程如下动图所示:
前序遍历的步骤为:
Java实现如下:
1 | /** BST */ |
编写测试程序:
1 | public class BinarySearchTreeTest { |
输出如下:
1 | 72 57 30 27 40 48 63 62 67 82 79 80 90 87 |
这个过程如下动图所示:
前序遍历的步骤为:
Java实现如下:
1 | /** BST */ |
编写测试程序:
1 | public class BinarySearchTreeTest { |
输出如下:
1 | 27 48 40 30 62 67 63 57 80 79 87 90 82 72 |
这个过程如下动图所示:
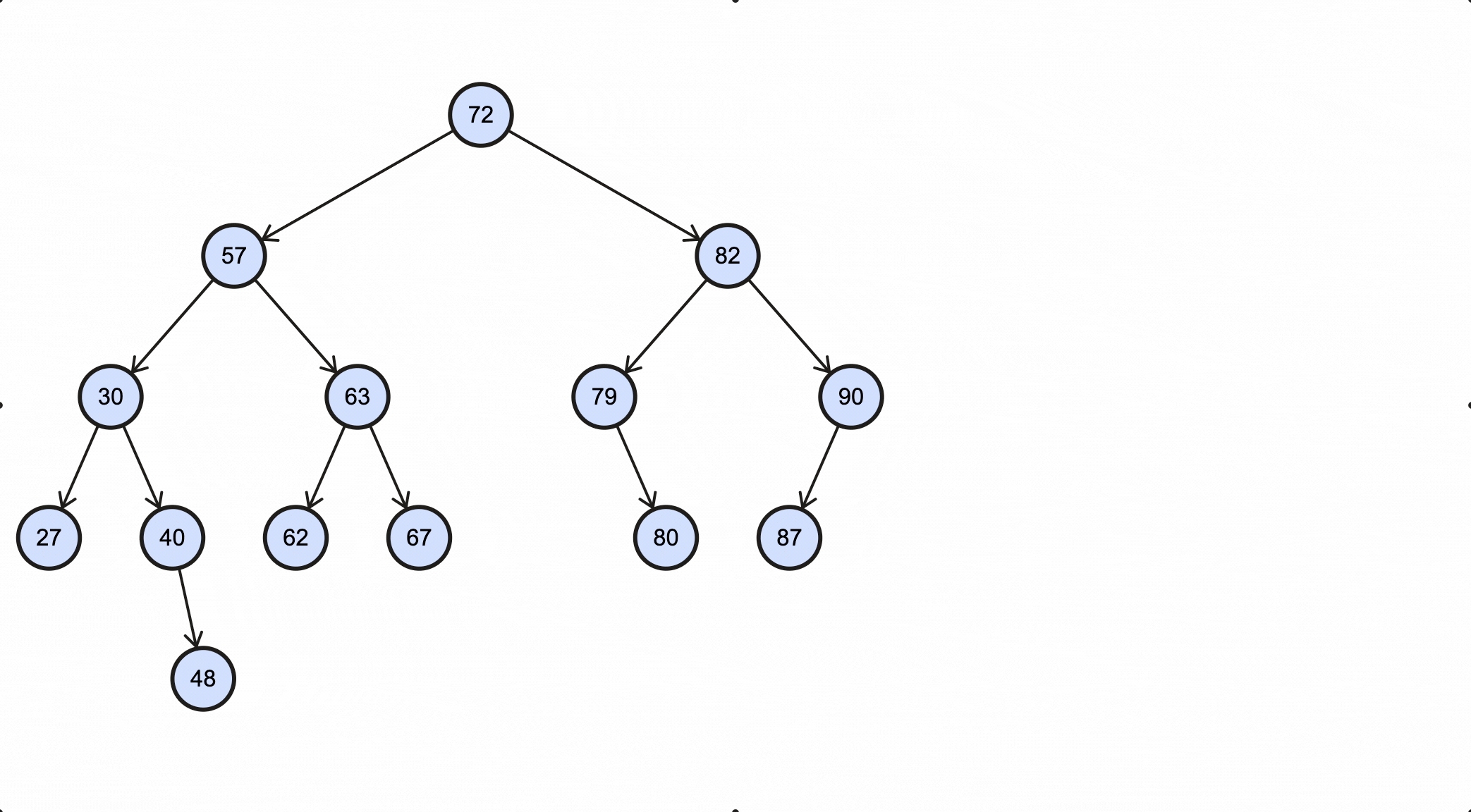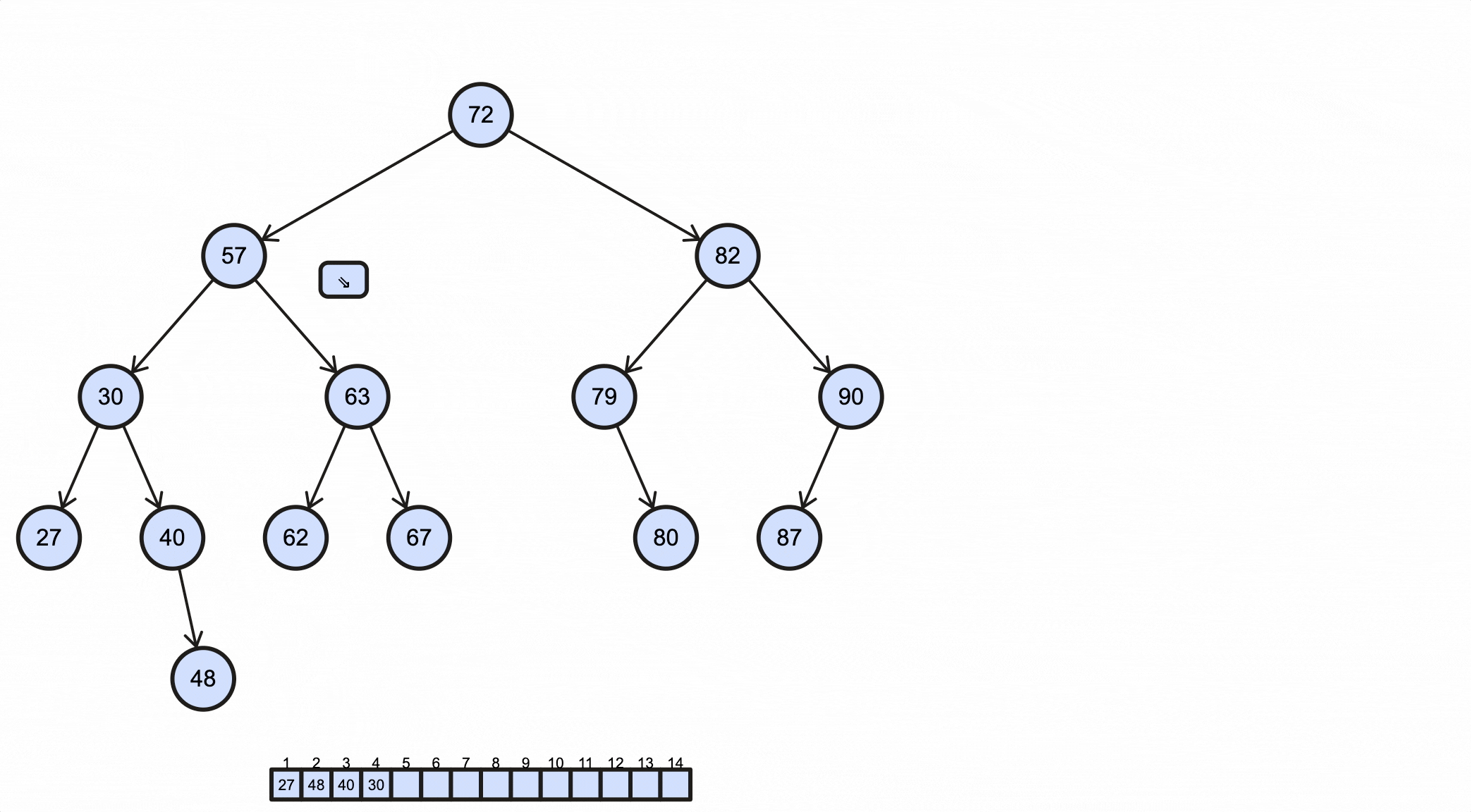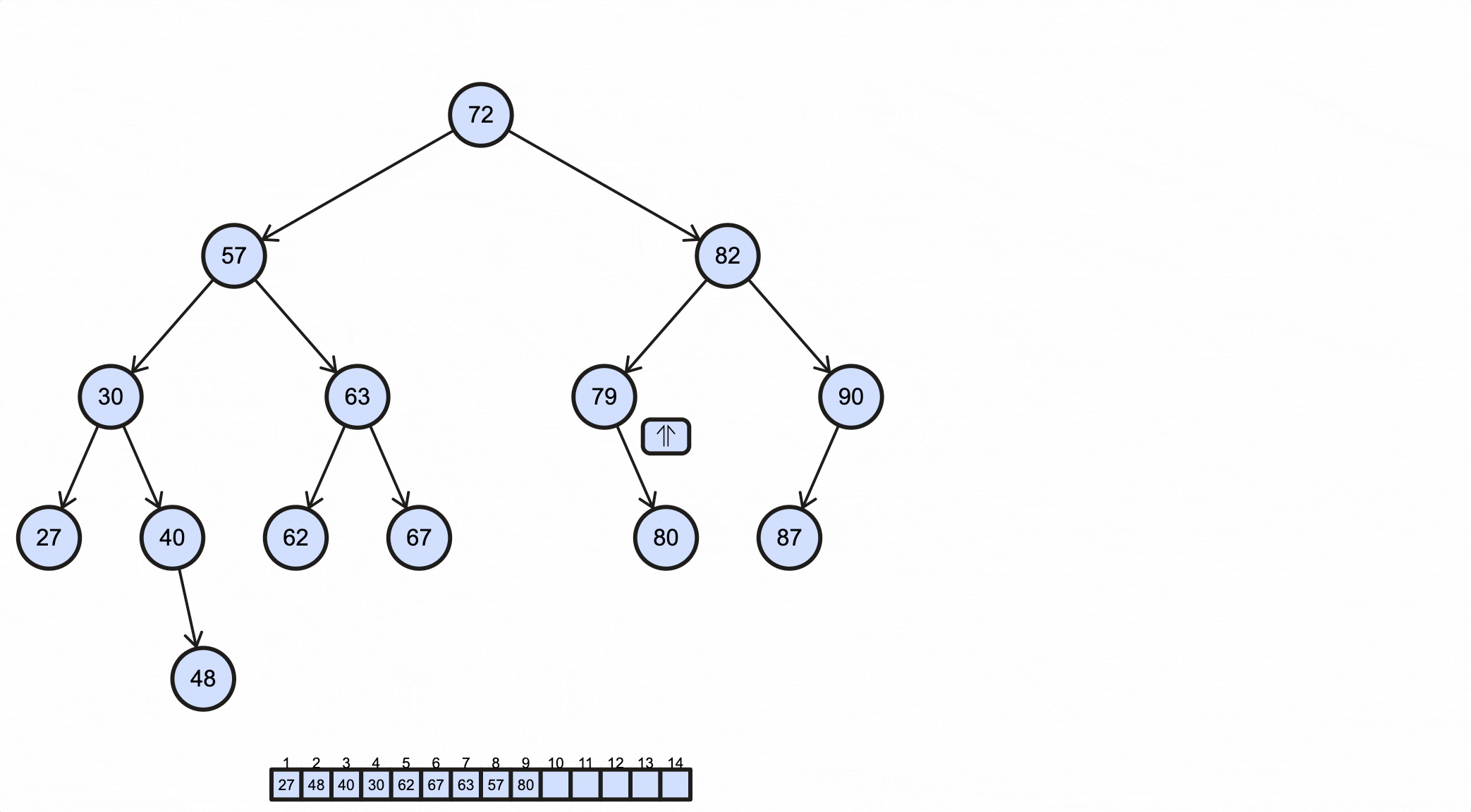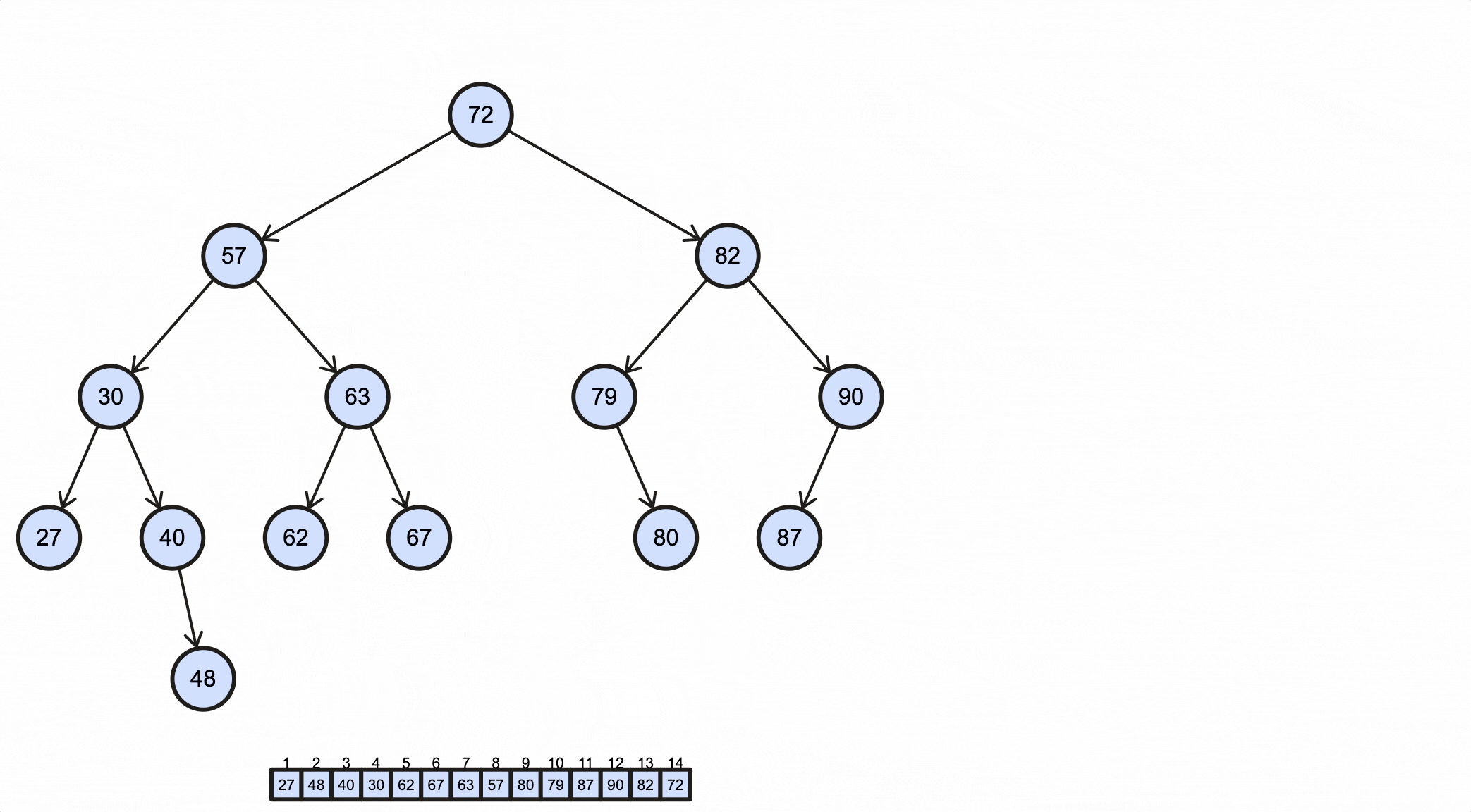
1 | /** |
节点的查找需要从根节点开始一层一层往下找,树节点数和层数的关系如下表所示:
| 节点数 | 层数 |
|---|---|
| 1 | 1 |
| 3 | 2 |
| 7 | 3 |
| 15 | 4 |
| 31 | 5 |
| … | … |
| 1023 | 10 |
| … | … |
| 32767 | 15 |
| … | … |
| 1048575 | 20 |
| … | … |
| 33554432 | 25 |
| … | … |
| 1073741824 | 30 |
假设节点数为N,层数为L,那么不难看出它们的关系为:N=2^(L-1),所以L=log2(N+1),大约为log2N,大O表示法为O(logN)。
虽然BST结合了数组和链表的优势,但它也不是完美的,当BST不平衡的时候,查找操作效率急剧下降。举个比较极端的例子:
假如插入的数据是升序数据:2,4,6,8,10,12…,这时候BST如下所示:

这时候BST实际上就是一个链表结构了,搜索效率为O(N)。一个BST完全平衡和完全不平衡的情况比较少见,就概率来说,BST的搜索效率介于O(N)与O(logN)之间。
为了解决非平衡树搜索效率下降的问题,人们又提出了红黑树的概念。在红黑树中,每个节点要么是红色的要么是黑色的,红黑树在插入和删除的过程中,需要遵循某些特定的规则,遵循这些规则可以确保数始终是趋于平衡的。
红黑树除了遵循基本的BST规则外,还需遵循以下4个规则:
在数据插入和删除过程中,如果违背了上述4个规则,则树会执行以下操作进行修正,以重新满足上述4个规则:
下面通过一个动图演示红黑树如何处理升序数据:2,4,6,8,10,12的插入,使得树趋于平衡:

]]>参考自《Java数据结构与算法(第二版)》,上述BST图片均来自http://btv.melezinek.cz/binary-search-tree.html网站,红黑树示例来自https://www.wztlink1013.com/visualization/RedBlack.html。
在使用Spring构建的应用程序中,适当使用事件发布与监听的机制可以使我们的代码灵活度更高,降低耦合度。Spring提供了完整的事件发布与监听模型,在该模型中,事件发布方只需将事件发布出去,无需关心有多少个对应的事件监听器;监听器无需关心是谁发布了事件,并且可以同时监听来自多个事件发布方发布的事件,通过这种机制,事件发布与监听是解耦的。
本节将举例事件发布与监听的使用,并介绍内部实现原理。
新建springboot应用,boot版本2.4.0,引入如下依赖:
1 | <dependencies> |
Spring中使用ApplicationEvent接口来表示一个事件,所以我们自定义事件MyEvent需要实现该接口:
1 | public class MyEvent extends ApplicationEvent { |
构造器source参数表示当前事件的事件源,一般传入Spring的context上下文对象即可。
事件发布通过事件发布器ApplicationEventPublisher完成,我们自定义一个事件发布器MyEventPublisher:
1 |
|
在自定义事件发布器MyEventPublisher中,我们需要通过ApplicationEventPublisher来发布事件,所以我们实现了ApplicationEventPublisherAware接口,通过回调方法setApplicationEventPublisher为MyEventPublisher的ApplicationEventPublisher属性赋值;同样的,我们自定义的事件MyEvent构造函数需要传入Spring上下文,所以MyEventPublisher还实现了ApplicationContextAware接口,注入了上下文对象ApplicationContext。
publishEvent方法发布了一个自定义事件MyEvent。事件发布出去后,我们接着编写相应的事件监听器。
我们可以方便地通过@EventListener注解实现事件监听,编写MyEventPublisher:
1 |
|
被@EventListener注解标注的方法入参为MyEvent类型,所以只要MyEvent事件被发布了,该监听器就会起作用,即该方法会被回调。
除了使用@EventListener注解实现事件的监听外,我们也可以手动实现ApplicationListener1
2
3
4
5
6
7
8
9
10
public class MyEventListener implements ApplicationListener<MyEvent> {
private final Logger logger = LoggerFactory.getLogger(this.getClass());
public void onApplicationEvent(MyEvent event) {
logger.info("收到自定义事件MyEvent");
}
}
在springboot的入口类中测试事件的发布:
1 |
|
运行程序,输出如下:
1 | 2020-06-22 16:31:46.667 INFO 83600 --- [ main] c.m.demo.publisher.MyEventPublisher : 开始发布自定义事件MyEvent |
可以看到,两个监听器都监听到了事件的发布。此外细心的读者会发现,事件发布和事件监听是同一个线程完成的,过程为同步操作,只有当所有对应事件监听器的逻辑执行完毕后,事件发布方法才能出栈。后面进阶使用会介绍如何使用异步的方式进行事件监听。
在事件发布方法上打个断点:

以debug的方式启动程序,程序执行到该断点后点击Step Into按钮,程序跳转到AbstractApplicationContext的publishEvent(ApplicationEvent event)方法:
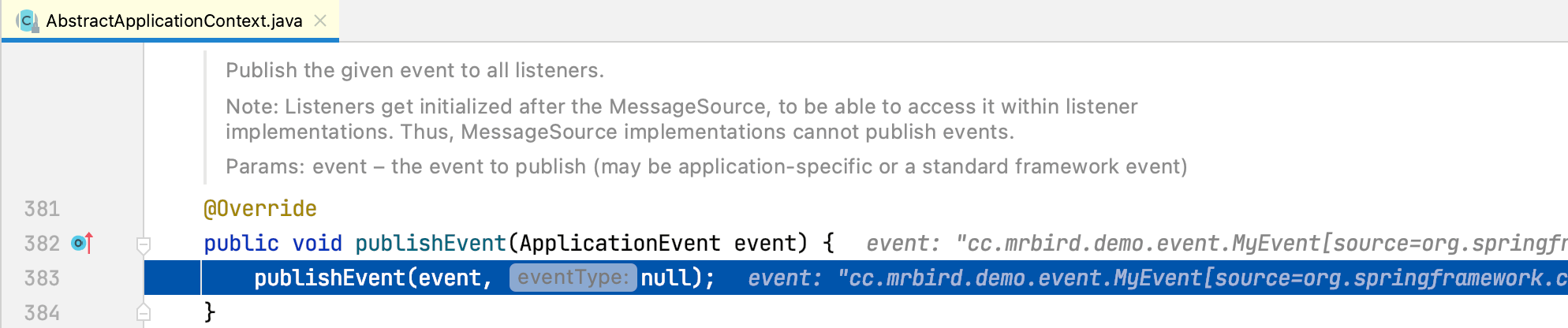
继续点击Step Into,程序跳转到AbstractApplicationContext的publishEvent(Object event, @Nullable ResolvableType eventType)方法:
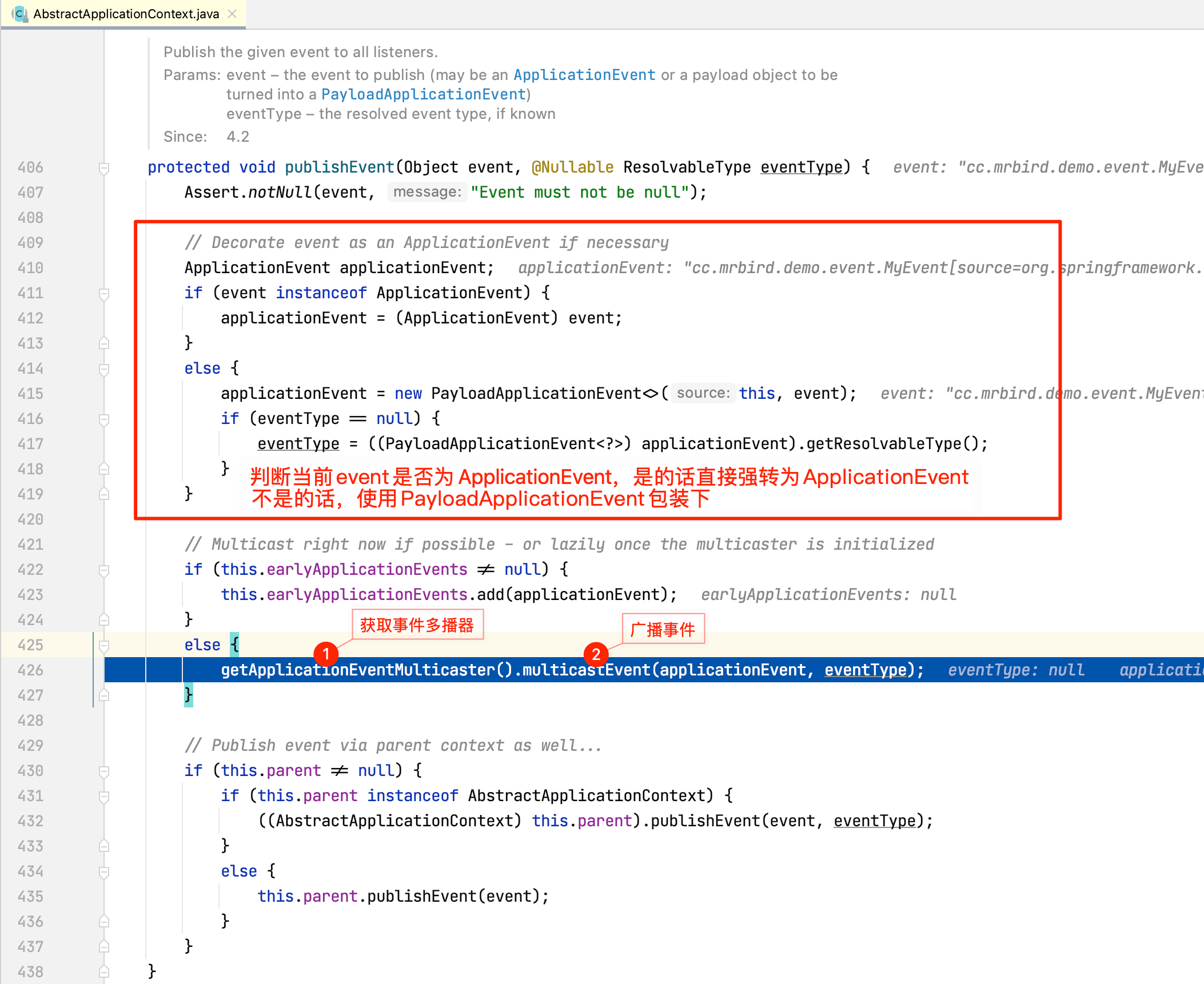
getApplicationEventMulticaster方法用于获取广播事件用的多播器,源码如下所示:
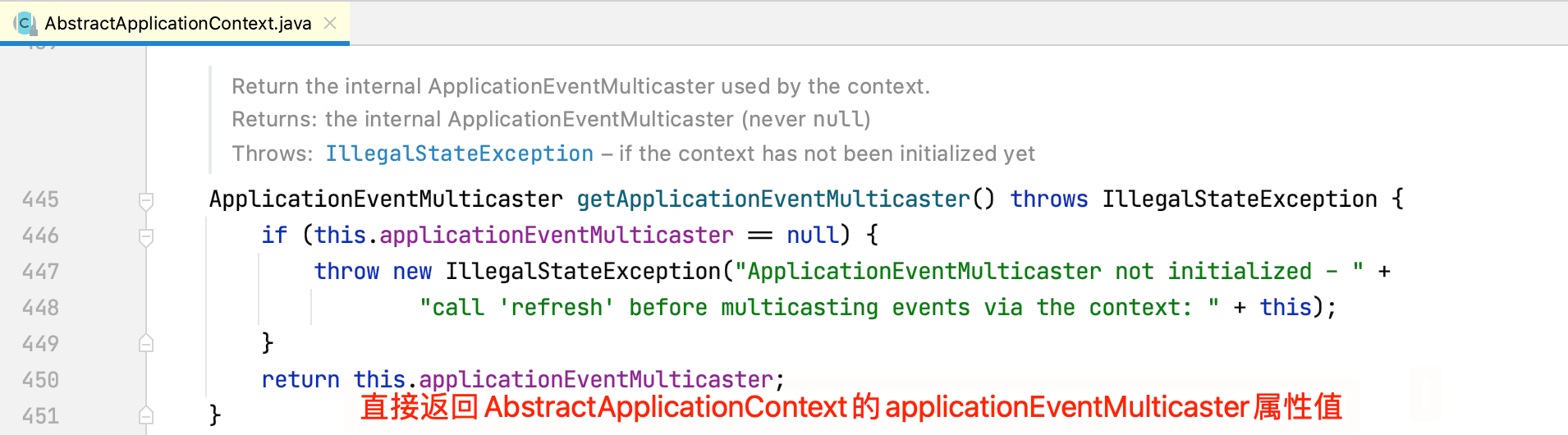
那么AbstractApplicationContext的applicationEventMulticaster属性是何时赋值的呢,下面将会介绍到。
获取到事件多播器后,调用其multicastEvent方法广播事件,点击Step Into进入该方法内部查看具体逻辑:
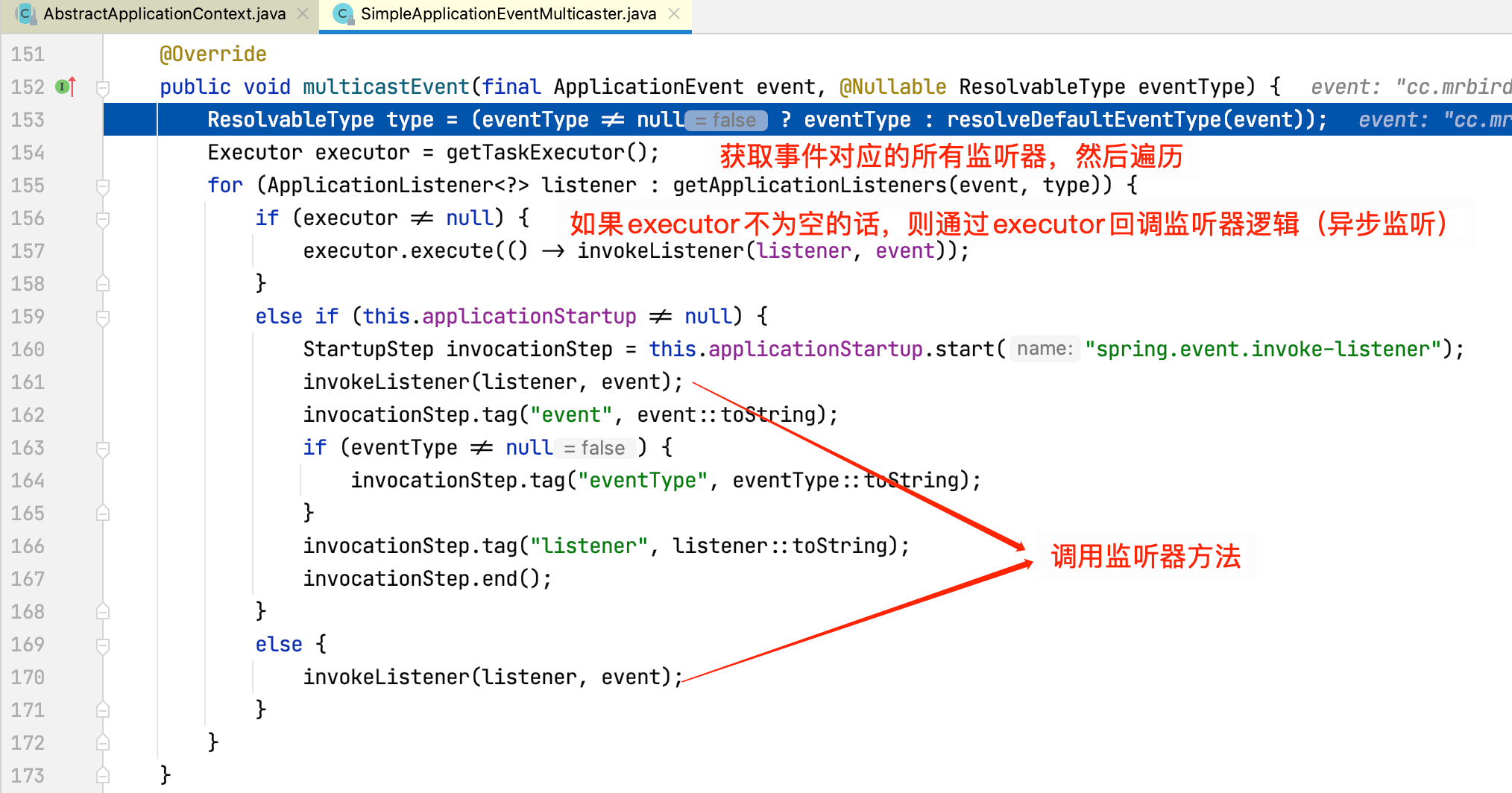
查看invokeListener方法源码:
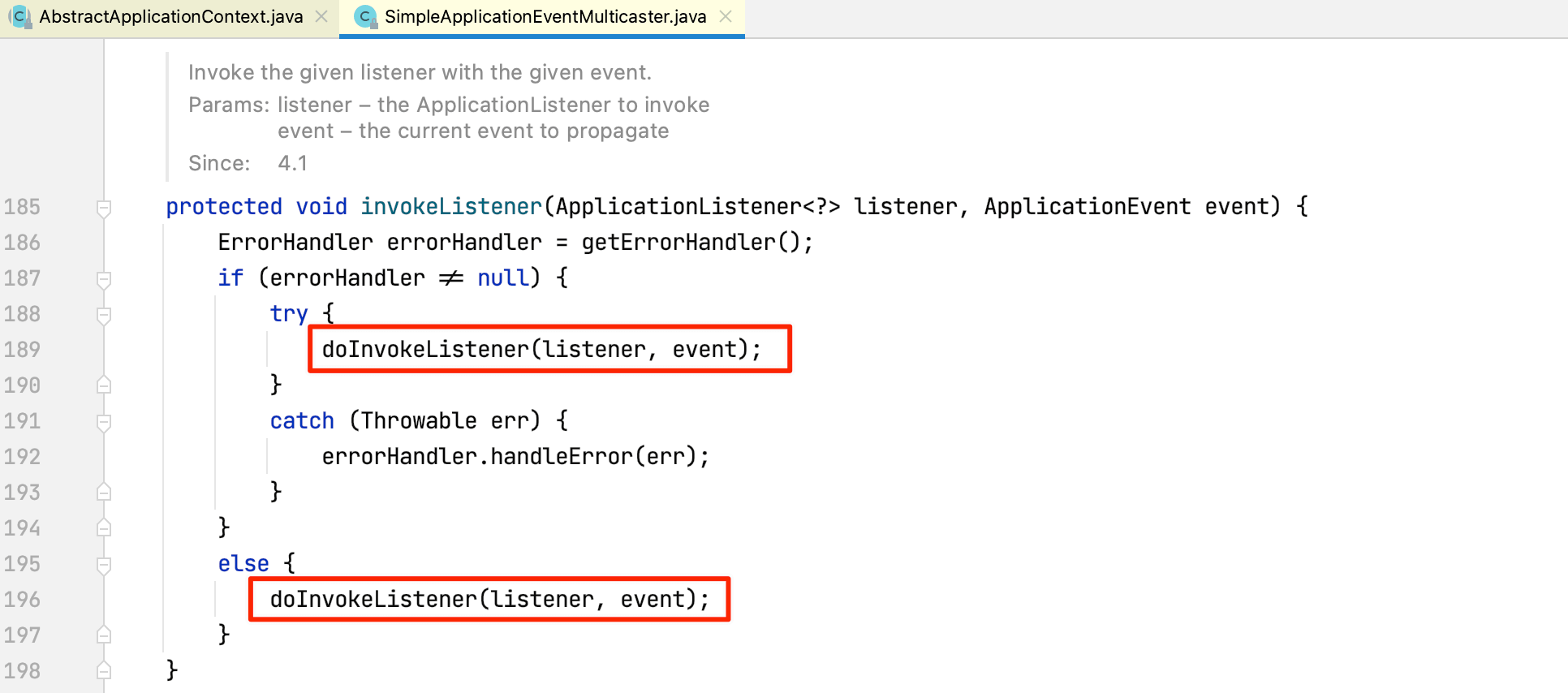
继续查看doInvokeListener方法源码:
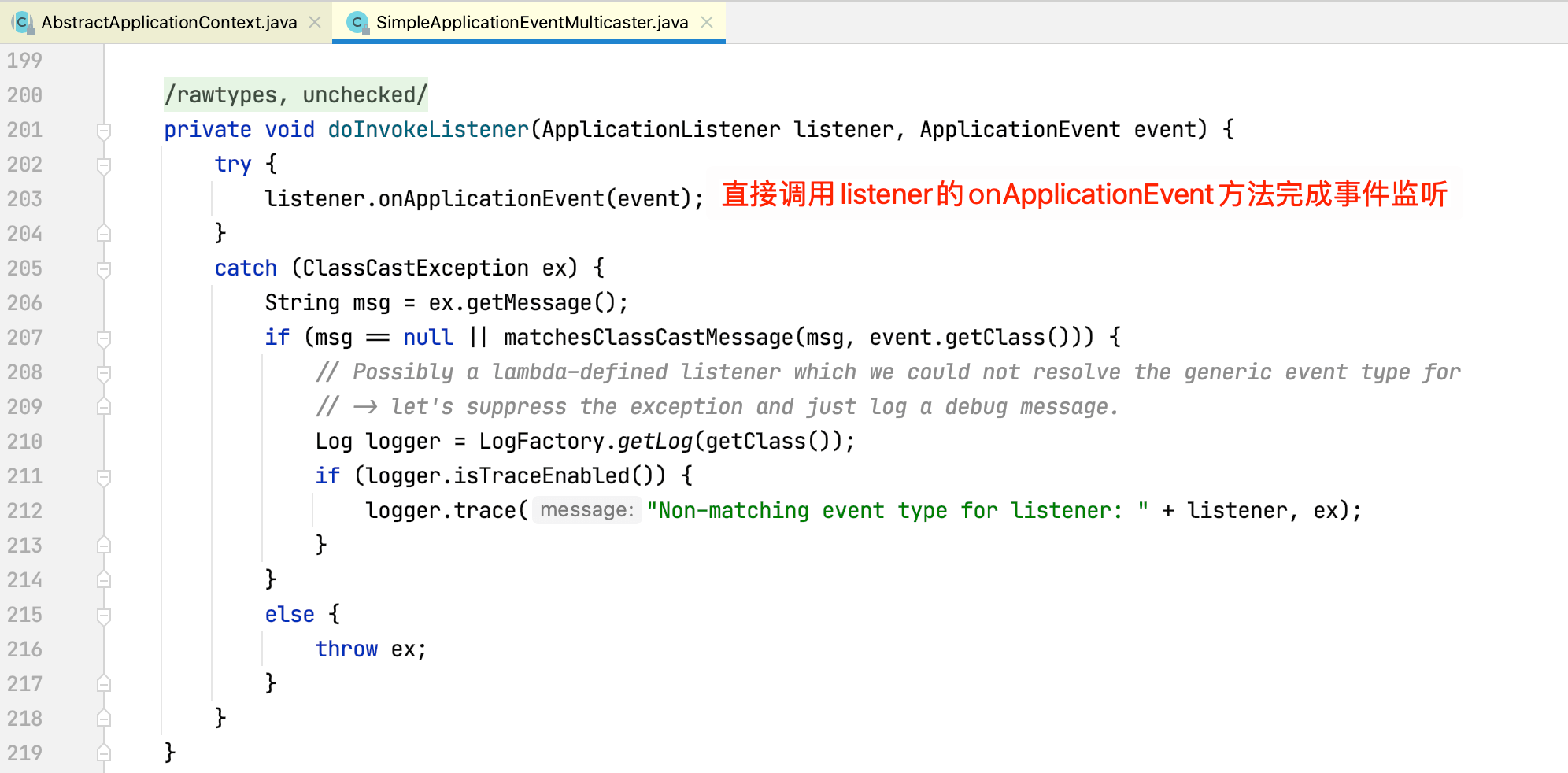
上述过程就是整个事件发布与监听的过程。
为了弄清楚AbstractApplicationContext的applicationEventMulticaster属性是何时赋值的(即事件多播器是何时创建的),我们在AbstractApplicationContext的applicationEventMulticaster属性上打个断点:
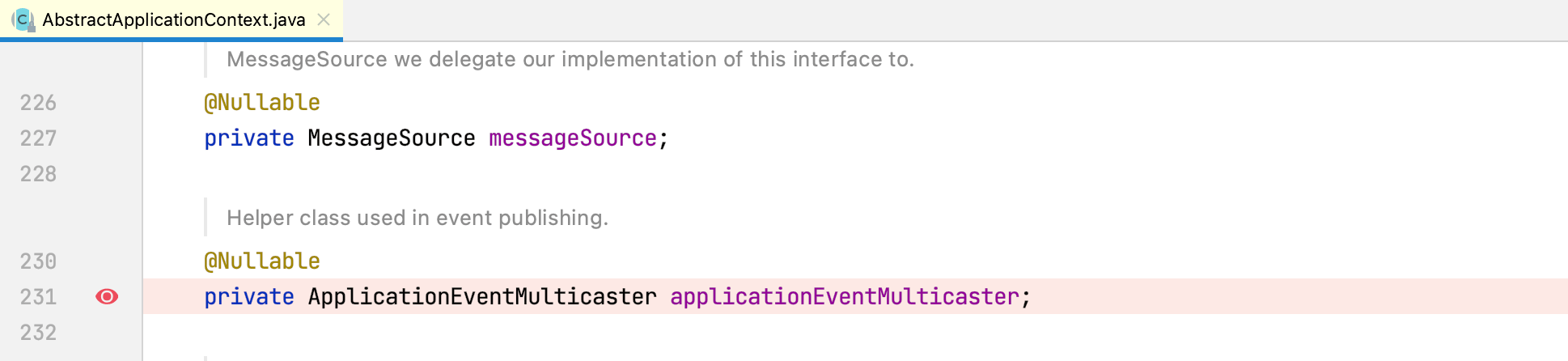
以debug的方式启动程序,程序跳转到了AbstractApplicationContext的initApplicationEventMulticaster方法中:
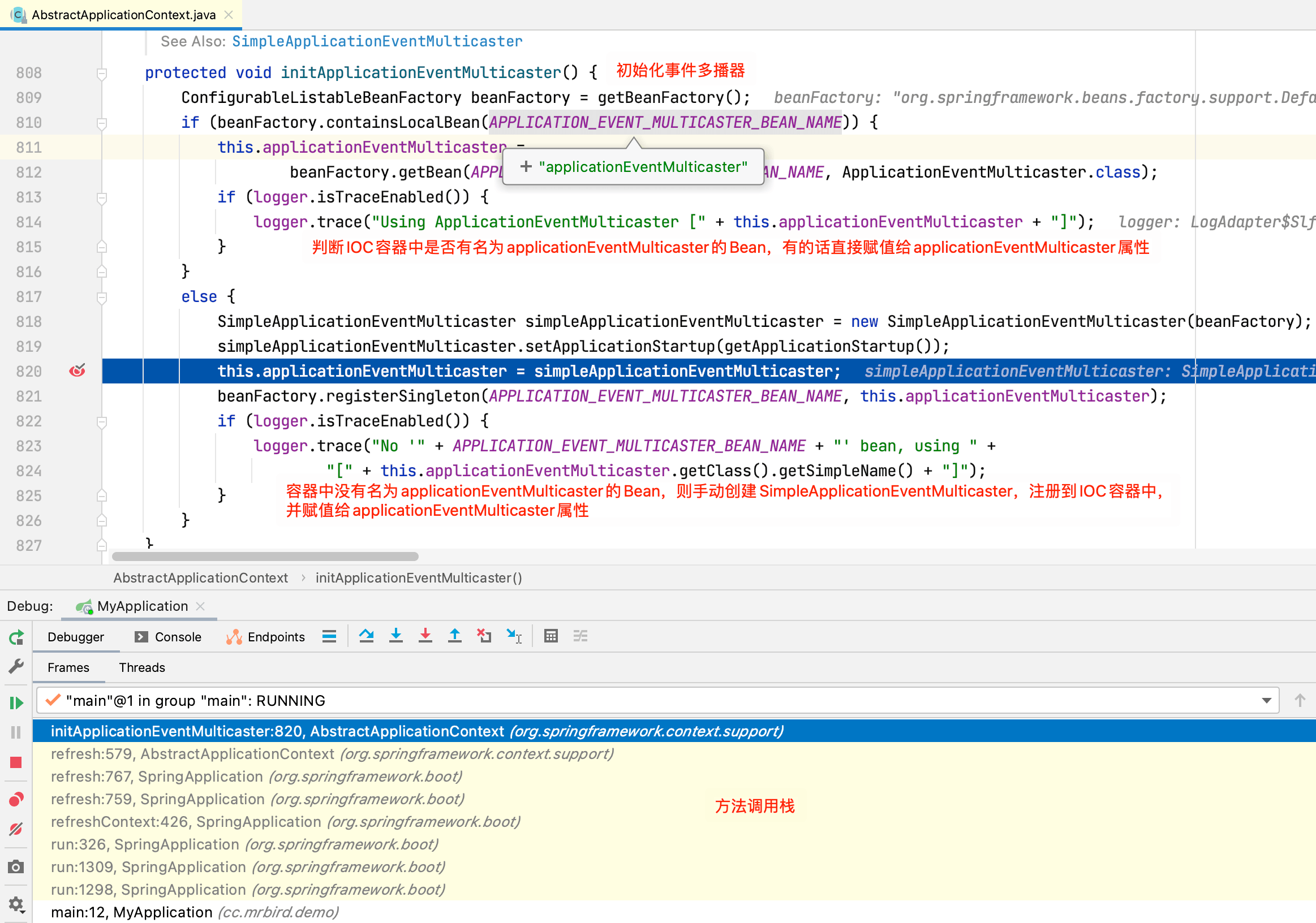
通过跟踪方法调用栈,我们可以总结出程序执行到上述截图的过程:
SpringBoot入口类的main方法执行SpringApplication.run(MyApplication.class, args)启动应用:

run方法内部包含refreshContext方法(刷新上下文):
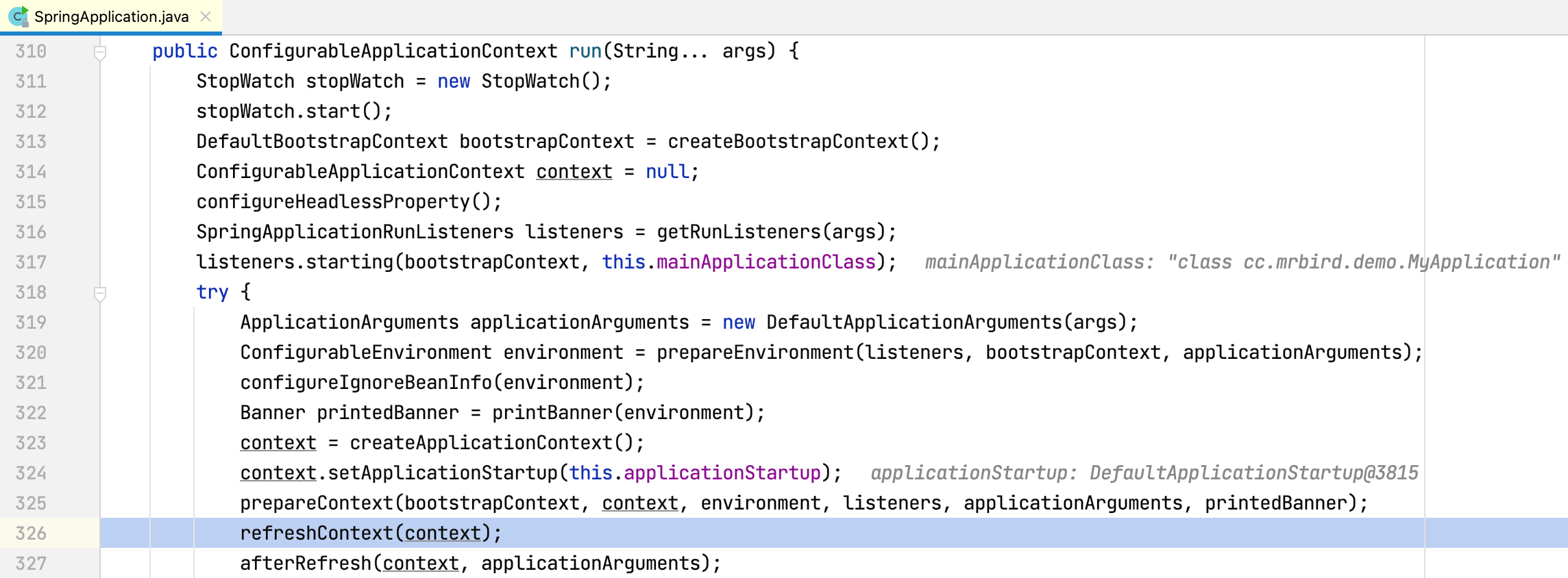
refresh方法内部包含initApplicationEventMulticaster方法:
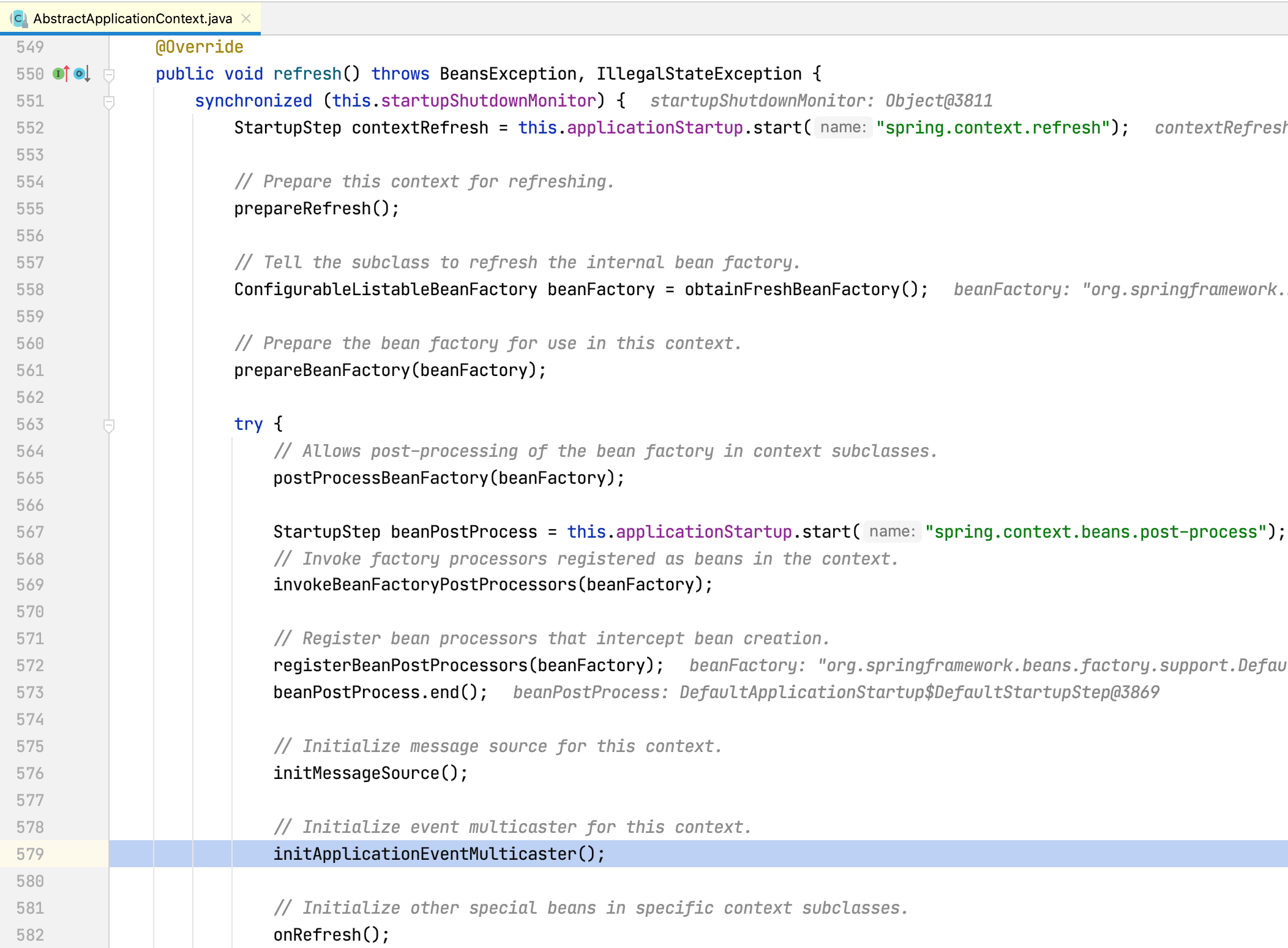
initApplicationEventMulticaster方法创建多播器。
在追踪事件发布与监听的过程中,我们知道事件对应的监听器是通过getApplicationListeners方法获取的:
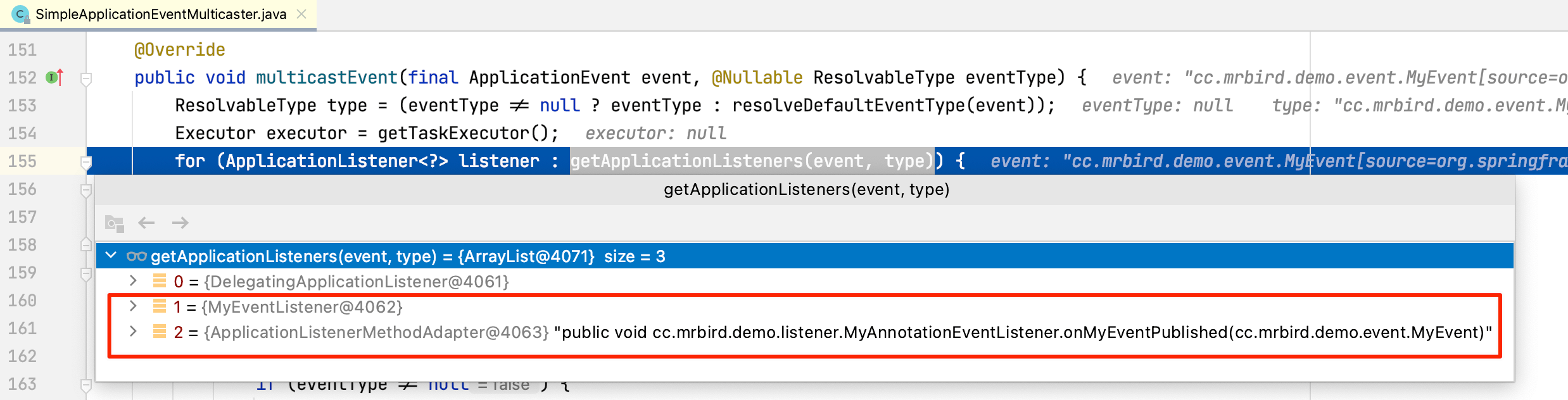
方法返回三个MyEvent事件对应的监听器,索引为0的监听器为DelegatingApplicationListener,它没有实质性的处理某事件,忽略;索引为1的监听器为通过实现ApplicationEventListener接口的监听器;索引为2的监听器为通过@EventListener实现的监听器。
查看getApplicationListeners源码:
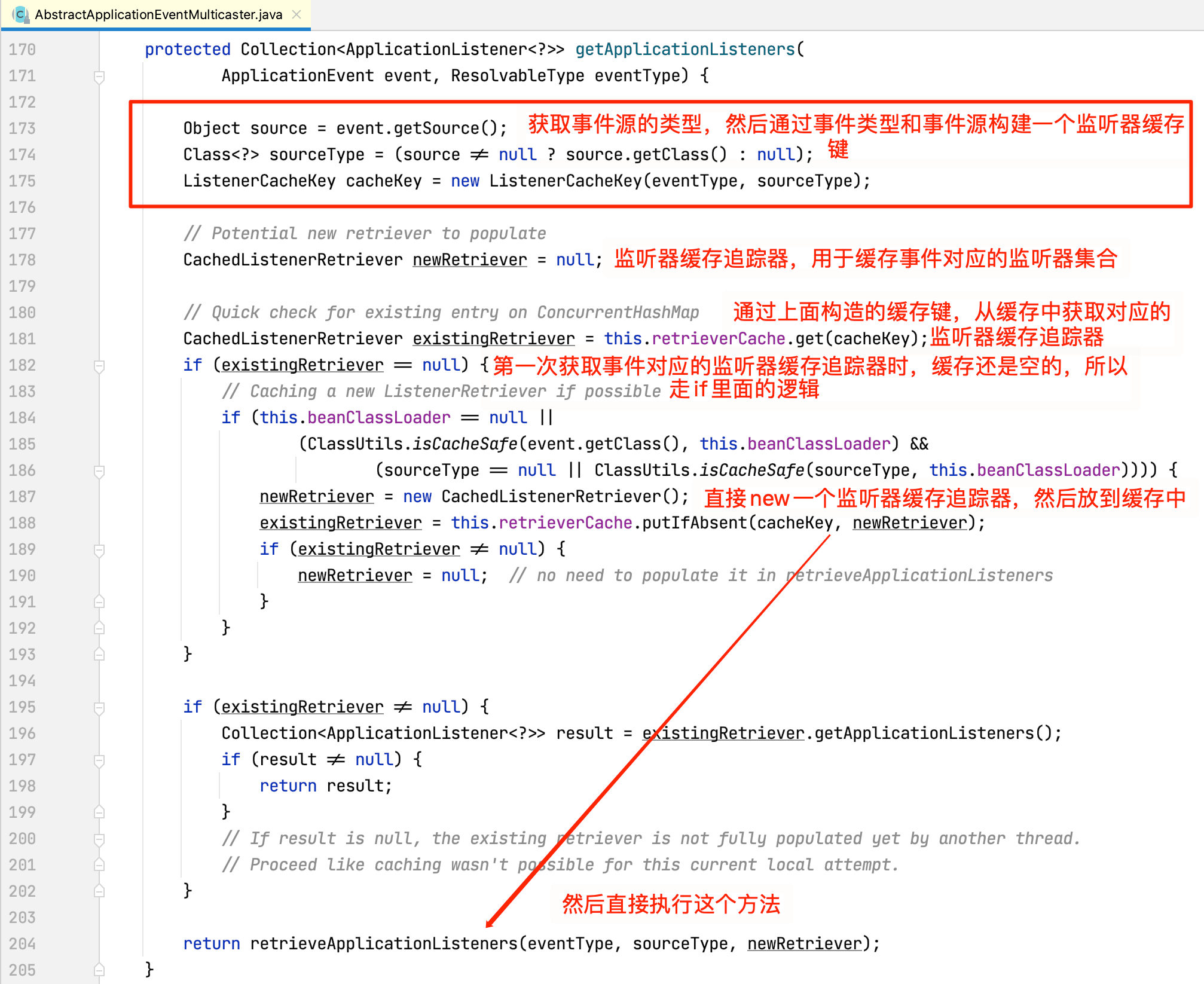
其中retrieverCache的定义为final Map<ListenerCacheKey, CachedListenerRetriever> retrieverCache = new ConcurrentHashMap<>(64)。
接着查看retrieveApplicationListeners方法(方法见名知意,程序第一次获取事件对应的监听器时,缓存中是空的,所以继续检索获取事件对应的监听器):
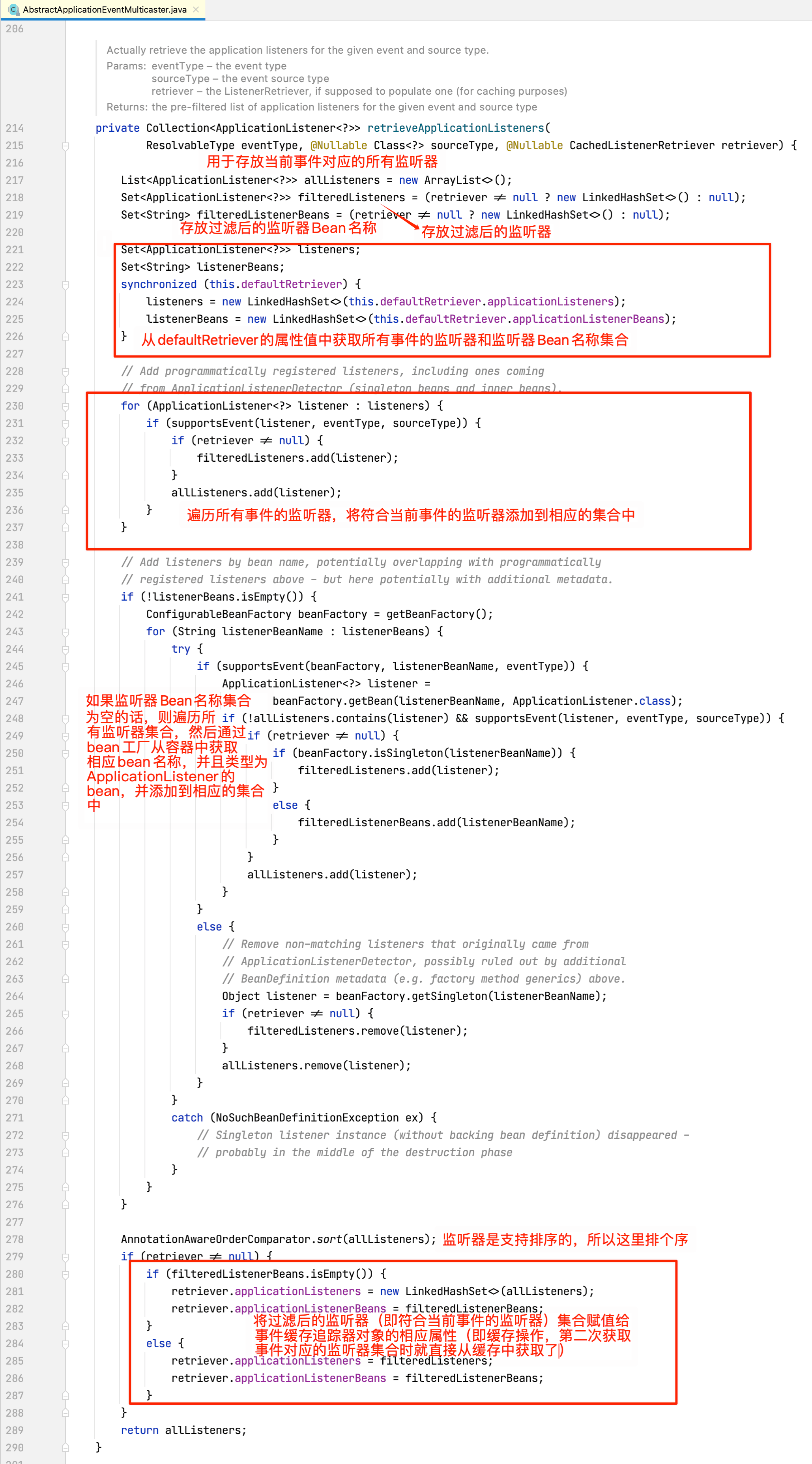
从上面这段代码我们知道,用于遍历的监听器集合对象listeners和listenerBeans的值是从this.defaultRetriever的applicationListeners和applicationListenerBeans属性获取的,所以我们需要关注这些属性是何时被赋值的。defaultRetriever的类型为DefaultListenerRetriever:
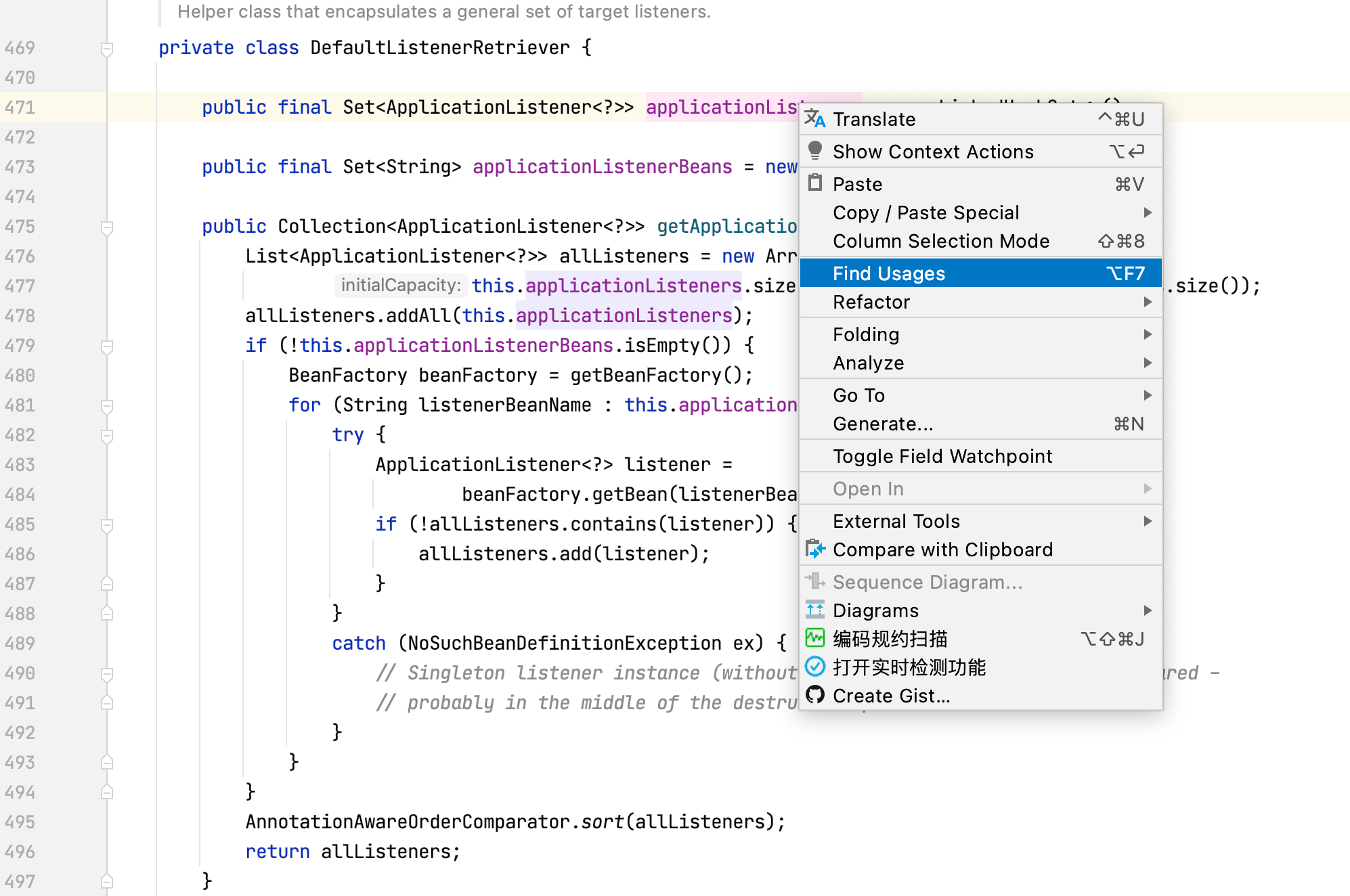
我们在applicationListeners属性上右键选择Find Usages查看赋值相关操作:
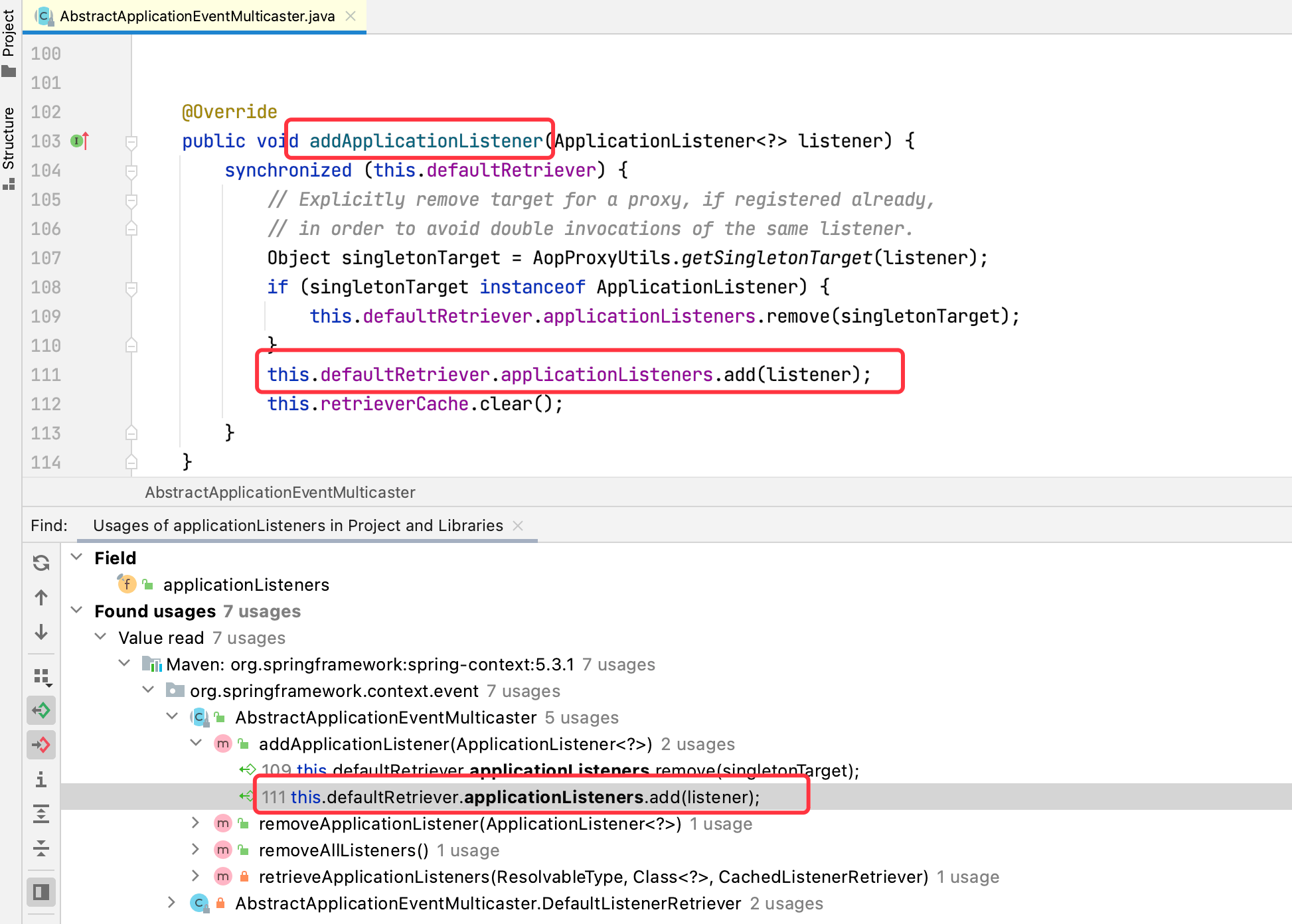
可以看到,赋值操作发生在AbstractApplicationEventMulticaster的addApplicationListener方法中,
继续在addApplicationListener方法上右键选择Find Usages查看调用源:
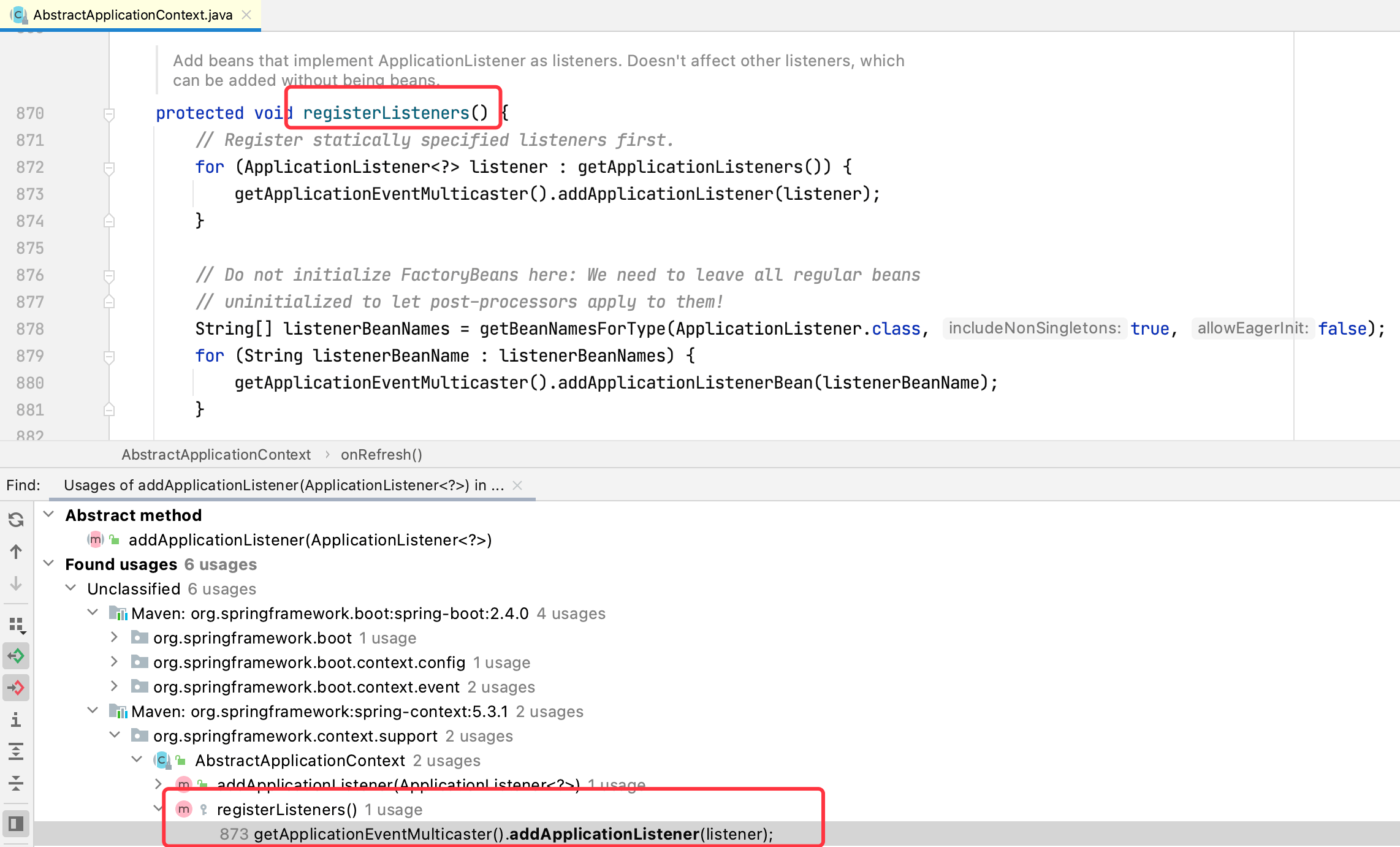
我们在registerListeners方法上打个断点,重新启动程序,查看方法调用栈:
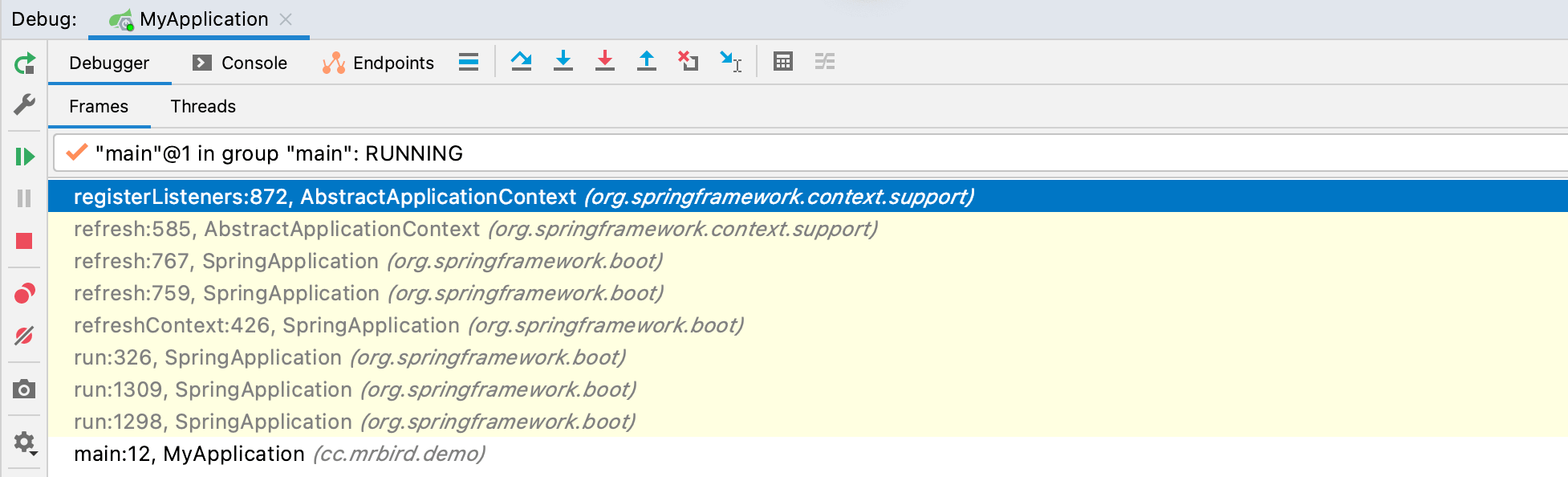
从方法调用栈我们可以总结出this.defaultRetriever的applicationListeners和applicationListenerBeans属性值赋值的过程:
SpringApplication.run(MyApplication.class, args)启动Boot程序;
run方法内部调用refreshContext刷新容器方法:
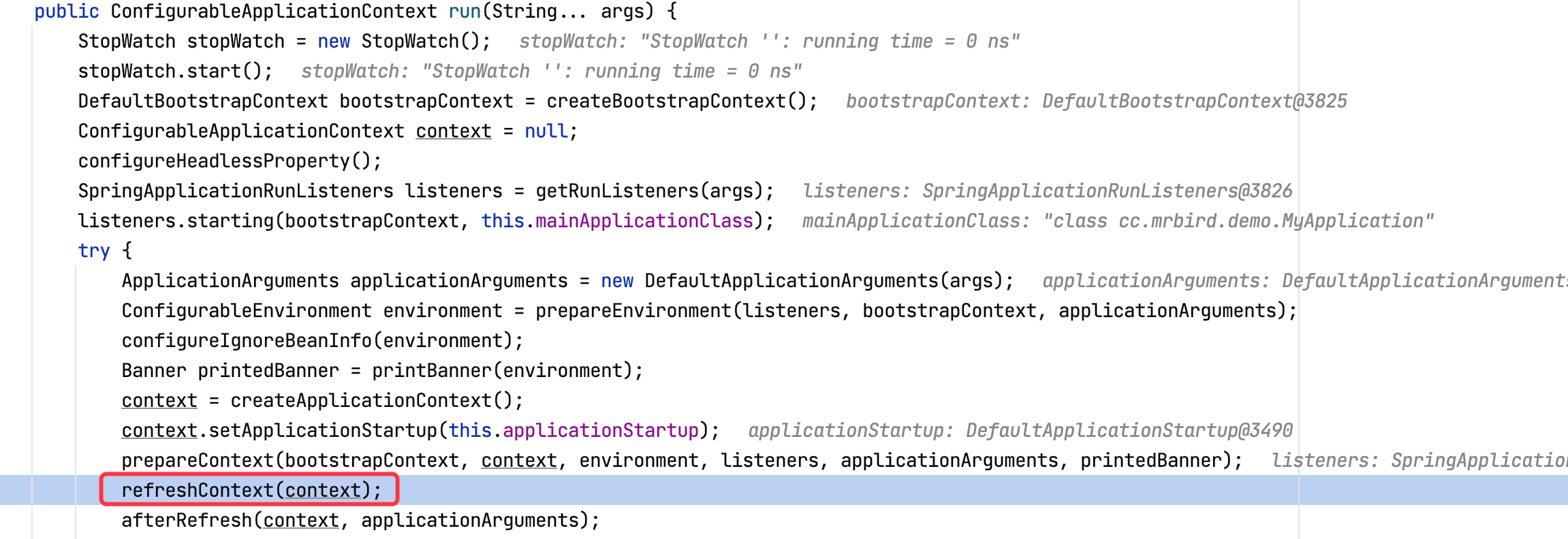
refresh方法内部调用了registerListener方法注册监听器:
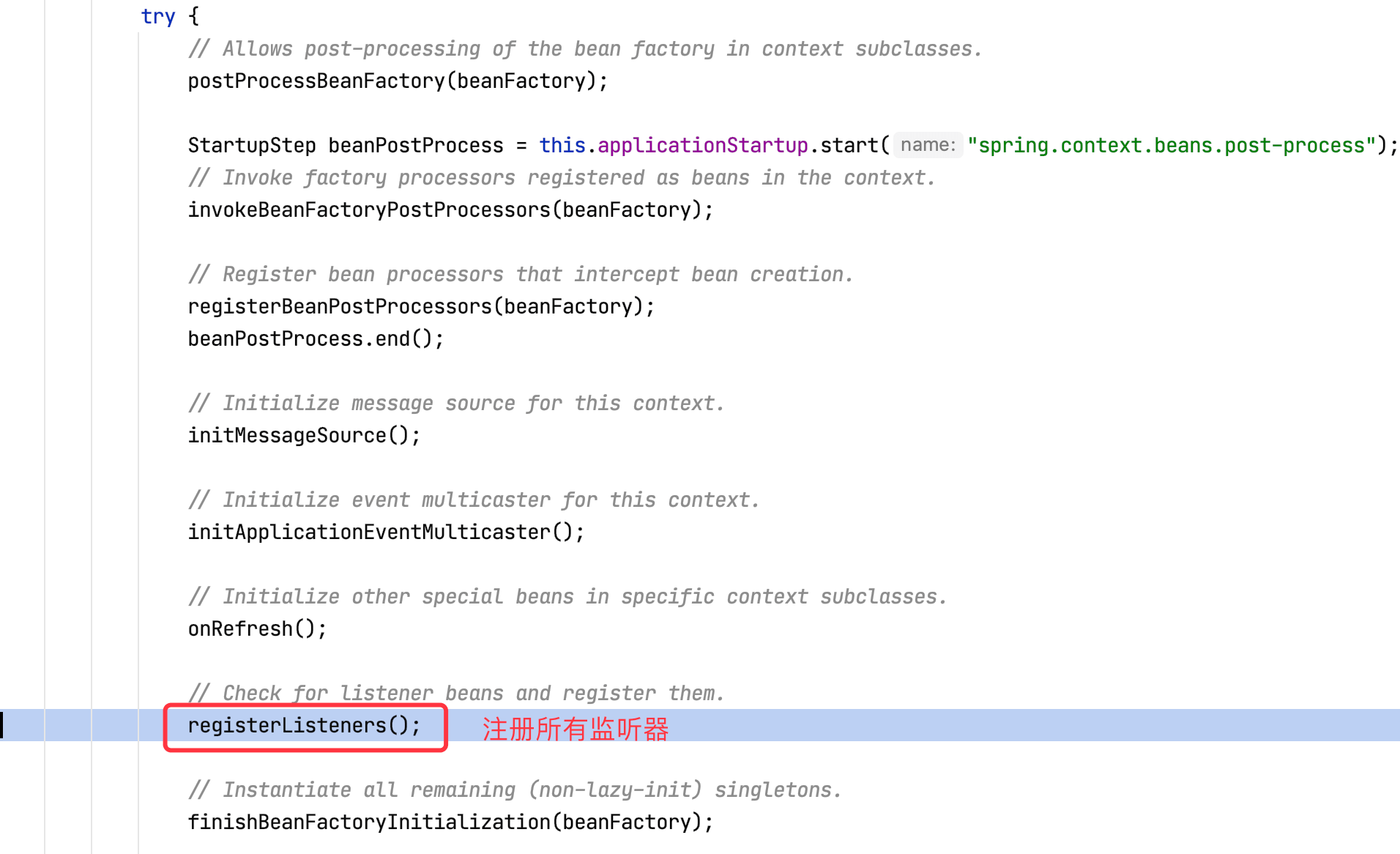
registerListeners方法内部从IOC容器获取所有ApplicationListener类型Bean,然后赋值给this.defaultRetriever的applicationListeners和applicationListenerBeans属性。
查看@EventListener注解源码:

查看EventListenerMethodProcessor源码:

其实现了SmartInitializingSingleton接口,该接口包含afterSingletonsInstantiated方法:

通过注释可以看到这个方法的调用时机为:单实例Bean实例化后被调用,此时Bean已经被创建出来。
我们查看EventListenerMethodProcessor是如何实现该方法的:

继续查看processBean方法源码:
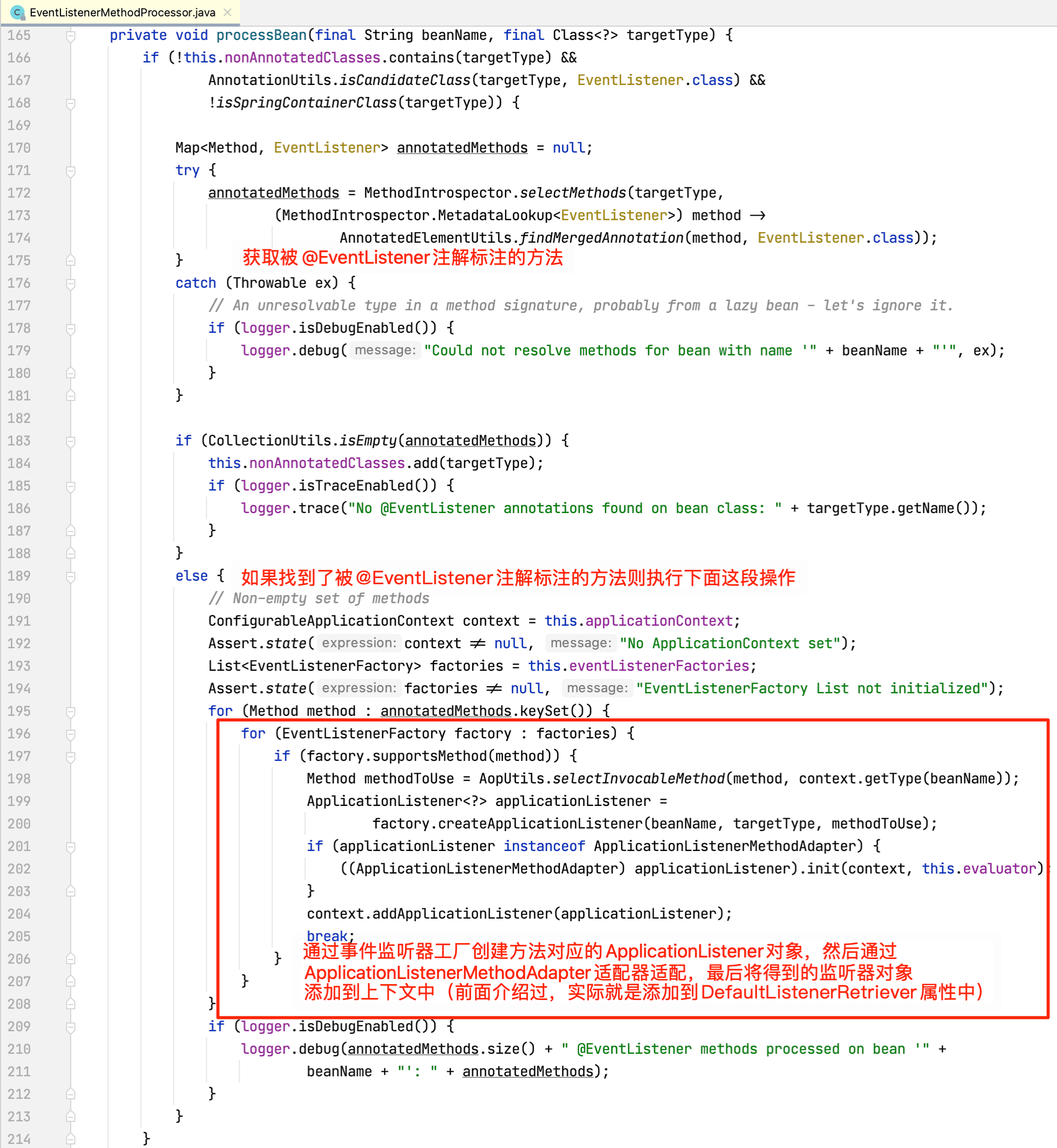
至此,两种方式注册监听器的原理都搞清楚了。
通过前面的分析,我们知道事件广播和监听是一个线程完成的同步操作,有时候为了让广播更有效率,我们可以考虑将事件监听过程异步化。
先来看看如何实现单个监听器异步。
首先需要在springboot入口类上通过@EnableAsync注解开启异步,然后在需要异步执行的监听器方法上使用@Async注解标注,以MyAnnotationEventListener为例:
1 |
|
启动程序,输出如下:

通过日志可以看出来,该监听器方法已经异步化,执行线程为task-1。
通过前面源码分析,我们知道多播器在广播事件时,会先判断是否有指定executor,有的话通过executor执行监听器逻辑。所以我们可以通过指定executor的方式来让所有的监听方法都异步执行:

新建一个配置类:
1 |
|
在配置类中,我们注册了一个名称为AbstractApplicationContext.APPLICATION_EVENT_MULTICASTER_BEAN_NAME(即applicationEventMulticaster)的Bean,用于覆盖默认的事件多播器,然后指定了TaskExecutor,SimpleAsyncTaskExecutor为Spring提供的异步任务executor。
在启动项目前,先把之前在springboot入口类添加的@EnableAsync注解去掉,然后启动项目,输出如下:

可以看到,监听器事件都异步化了。
事件监听器除了可以监听单个事件外,也可以监听多个事件(仅@EventListener支持),修改MyAnnotationEventListener:
1 |
|
该监听器将同时监听MyEvent、ContextRefreshedEvent和ContextClosedEvent三种类型事件:

单个类型事件也可以有多个监听器同时监听,这时候可以通过实现Ordered接口实现排序(或者@Order注解标注)。
修改MyEventListener:
1 |
|
修改MyAnnotationEventListener:
1 |
|
启动程序输出如下:

@EventListener注解还包含一个condition属性,可以配合SpEL表达式来条件化触发监听方法。修改MyEvent,添加一个boolean类型属性:
1 | public class MyEvent extends ApplicationEvent { |
在发布事件的时候,将该属性设置为false:
1 |
|
在MyAnnotationEventListener的@EventListener注解上演示如何使用SpEL:
1 |
|
condition = "#event.flag"的含义为,当前event事件(这里为MyEvent)的flag属性为true的时候执行。
启动程序,输出如下:

因为我们发布的MyEvent的flag属性值为false,所以上面这个监听器没有被触发。
Spring 4.2开始提供了一个@TransactionalEventListener注解用于监听数据库事务的各个阶段:
例子:
1 | (phase = TransactionPhase.AFTER_COMMIT) |
在Spring-事务管理一节中,我们了解了在Spring中如何方便的管理数据库事务,并了解了一些和事务相关的专业术语。本节将通过一个简单的例子回顾Spring声明式事务的使用,并通过源码解读内部实现原理,最后通过列举一些常见事务不生效的场景来加深对Spring事务原理的理解。
新建SpringBoot项目,Boot版本2.4.0,然后引入如下依赖:
1 | <dependencies> |
引入了JDBC、MySQL驱动和mybatis等依赖。
然后在Spring入口类上加上@EnableTransactionManagement注解,以开启事务:
1 |
|
接着新建名称为test的MySQL数据库,并创建USER表:
1 | CREATE TABLE `USER` ( |
其中USER_ID字段非空。
在application.properties配置中添加数据库相关配置:
1 | spring.datasource.driver-class-name=com.mysql.cj.jdbc.Driver |
创建USER表对应实体类User:
1 | public class User implements Serializable { |
创建UserMapper:
1 |
|
包含一个新增用户的方法save。
创建Service接口UserService:
1 | public interface UserService { |
其实现类UserServiceImpl:
1 |
|
在SpringBoot的入口类中测试一波:
1 |
|
如果事务生效的话,这条数据将不会被插入到数据库中,运行程序后,查看库表:

可以看到数据并没有被插入,说明事务控制成功。
我们注释掉UserServiceImpl的saveUser方法上的@Transactional注解,重新运行程序,查看库表:

可以看到数据被插入到数据库中了,事务控制失效。
上面例子中,我们通过模块驱动注解@EnableTransactionManagement开启了事务管理功能,查看其源码:
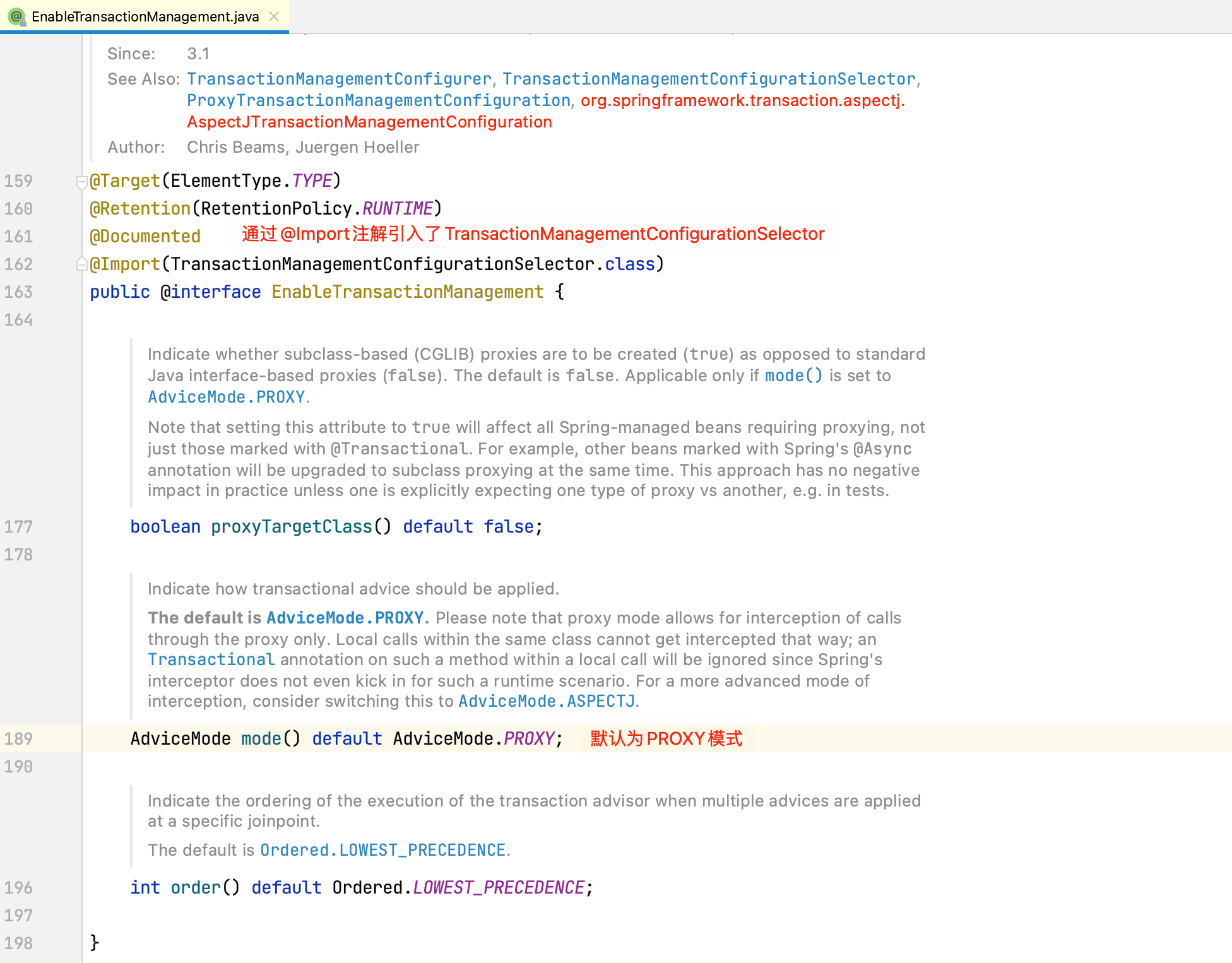
接着查看TransactionManagementConfigurationSelector的源码:

所以接下来我们重点关注AutoProxyRegistrar和ProxyTransactionManagementConfiguration的逻辑即可。
查看AutoProxyRegistrar的源码:

查看AopConfigUtils.registerAutoProxyCreatorIfNecessary(registry)源码:
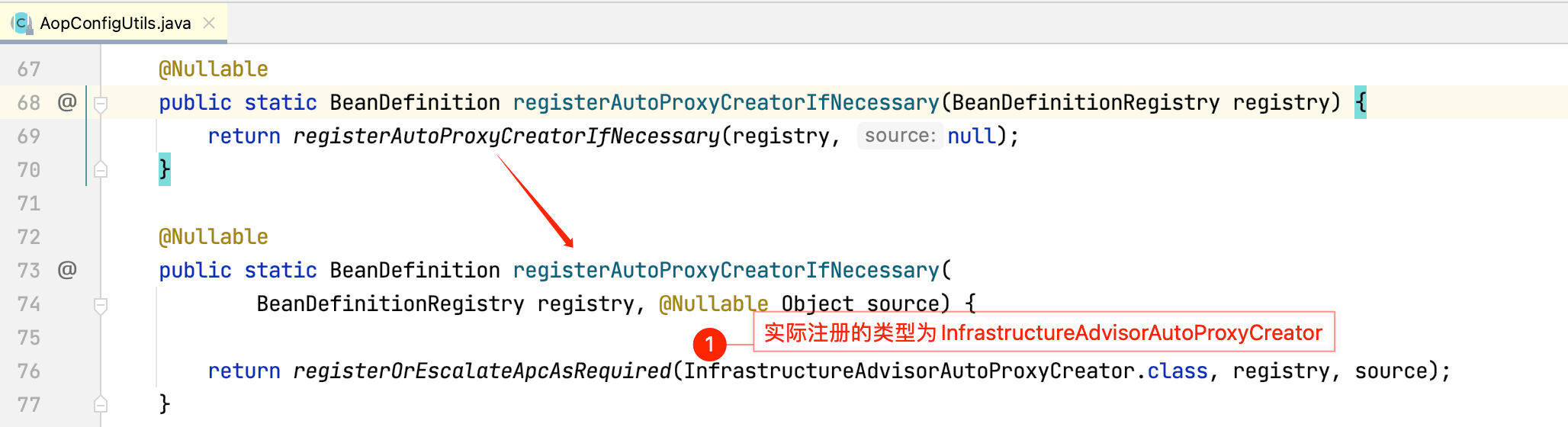
查看InfrastructureAdvisorAutoProxyCreator的层级关系图:
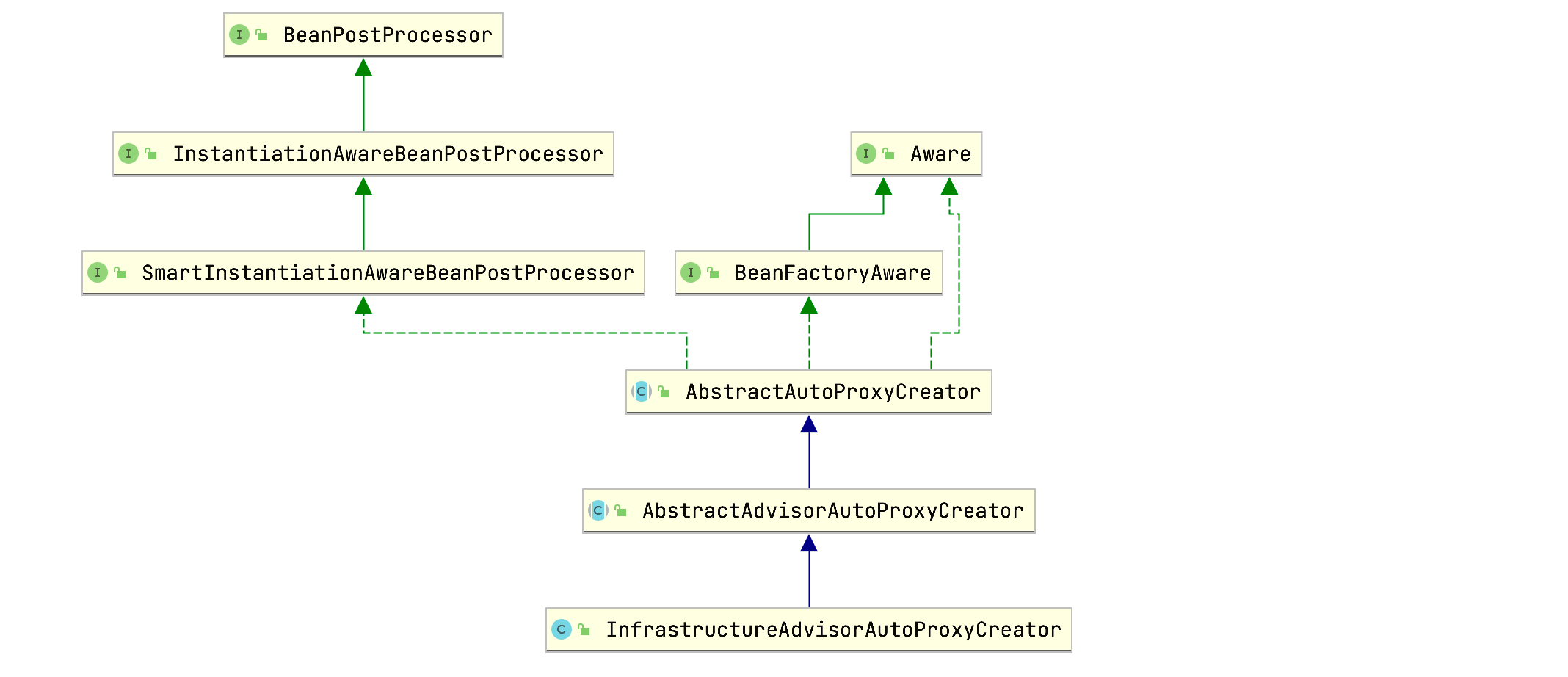
这和深入理解Spring-AOP原理一文中的AnnotationAwareAspectJAutoProxyCreator的层级关系图一致,所以我们可以推断出InfrastructureAdvisorAutoProxyCreator的作用为:为目标Service创建代理对象,增强目标Service方法,用于事务控制。
查看ProxyTransactionManagementConfiguration源码:
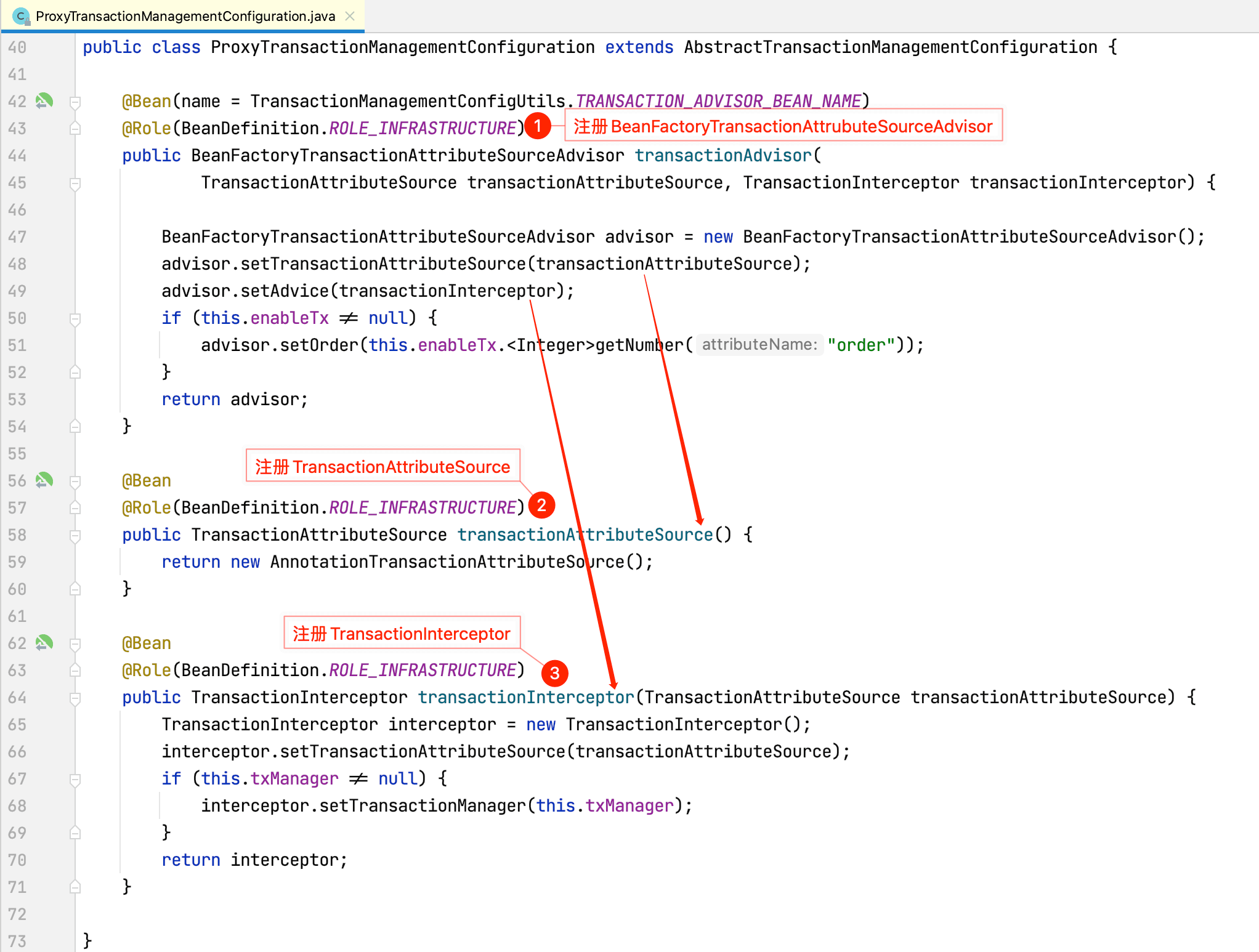
注册BeanFactoryTransactionAttributeSourceAdvisor增强器,该增强器需要如下两个Bean:
注册TransactionAttributeSource:

方法体内部创建了一个类型为AnnotationTransactionAttributeSource的Bean,查看其源码:
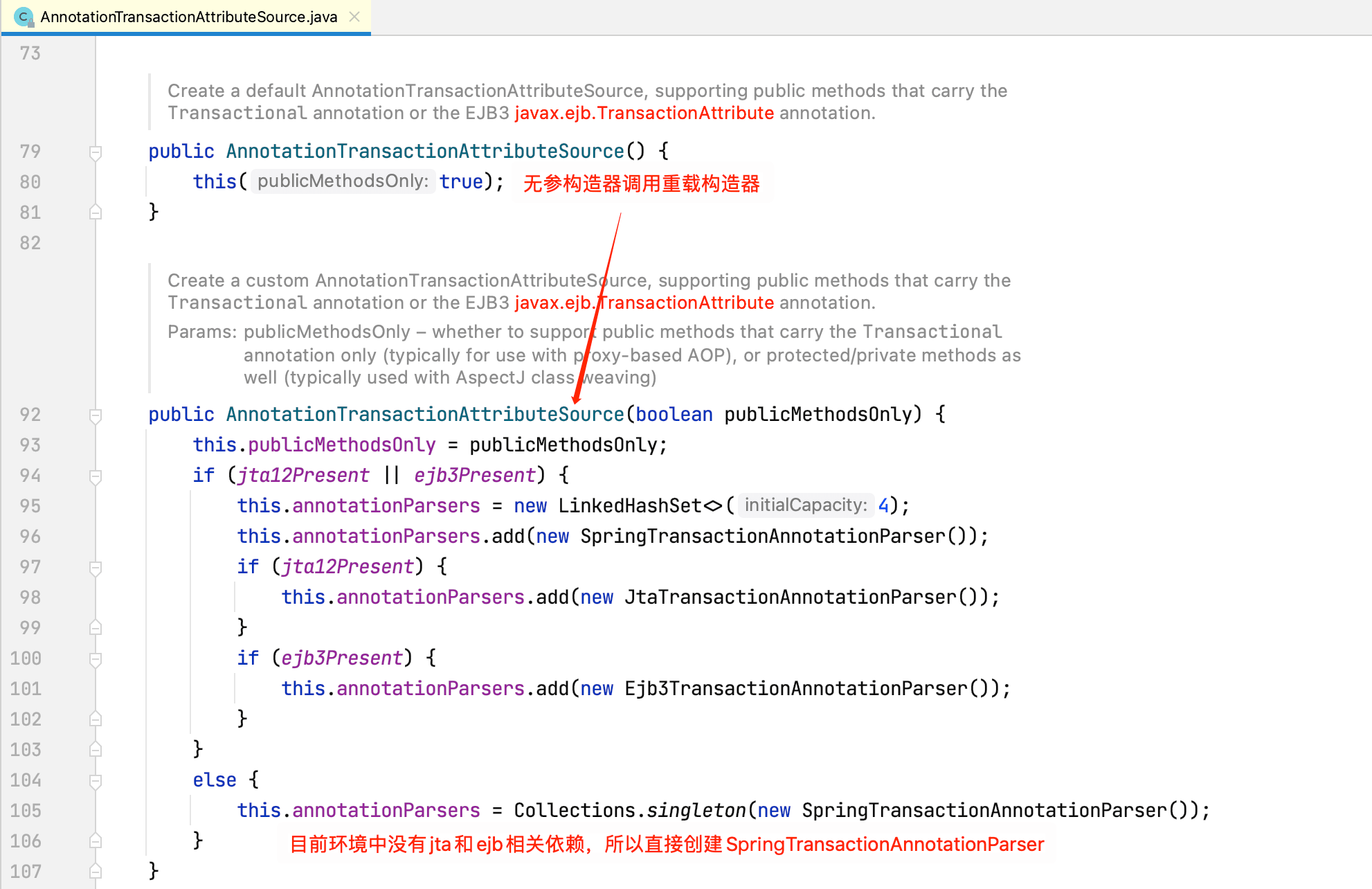
查看SpringTransactionAnnotationParser源码:

注册TransactionInterceptor事务拦截器:

查看TransactionInterceptor源码,其实现了MethodInterceptor方法拦截器接口,在深入理解Spring-AOP原理一文中曾介绍过,MethodBeforeAdviceInterceptor、AspectJAfterAdvice、AfterReturningAdviceInterceptor和AspectJAfterThrowingAdvice等增强器都是MethodInterceptor的实现类,目标方法执行的时候,对应拦截器的invoke方法会被执行,所以重点关注TransactionInterceptor实现的invoke方法:
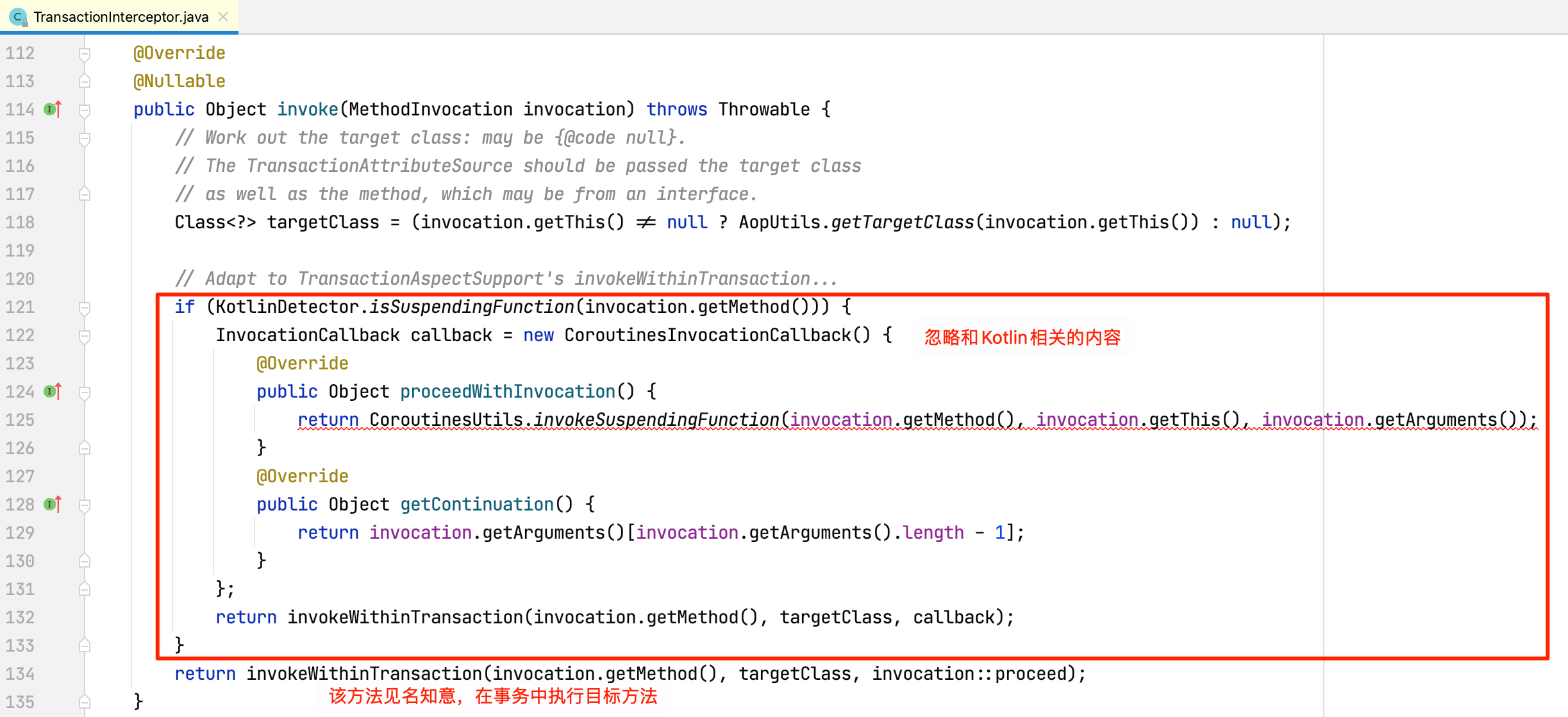
查看invokeWithinTransaction方法源码:

completeTransactionAfterThrowing源码如下:

这里,假如没有在@Transactional注解上指定回滚的异常类型的话,默认只对RunTimeExcetion和Error类型异常进行回滚:

commitTransactionAfterReturning源码如下:

重新打开UserServiceImpl的saveUser方法上的@Transactional注解,然后在如下所示位置打个断点:
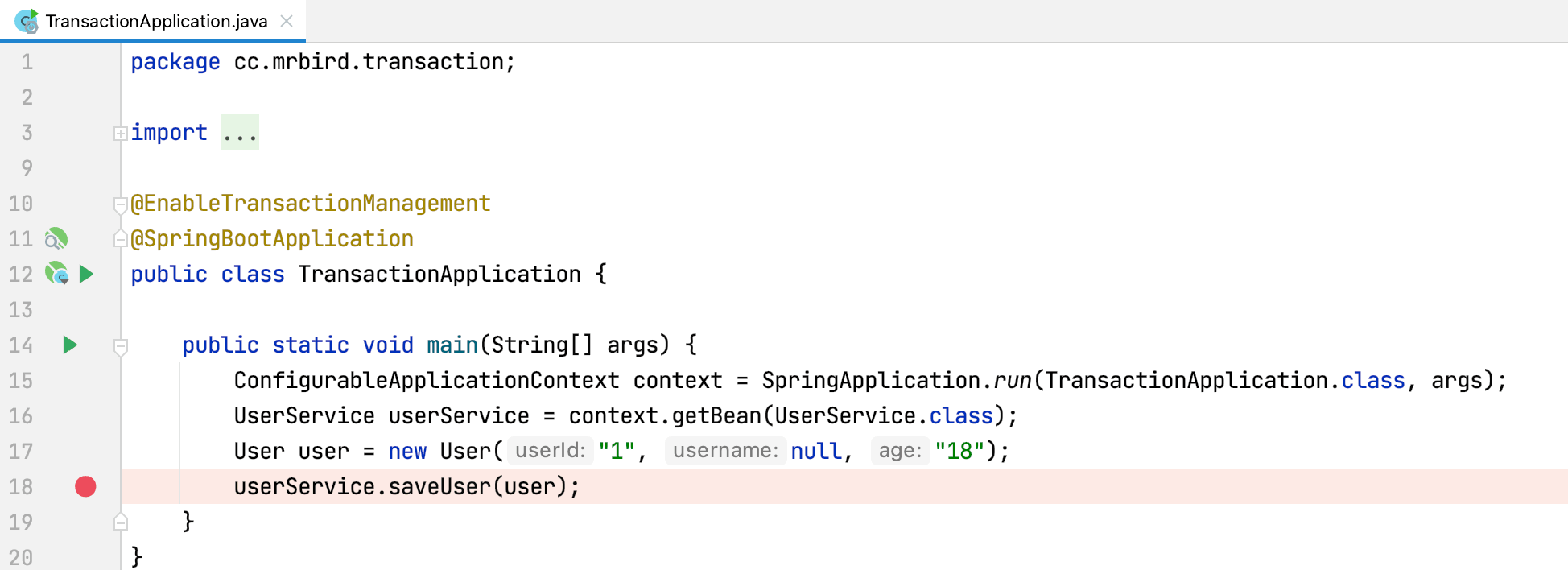
以debug的方式启动程序:
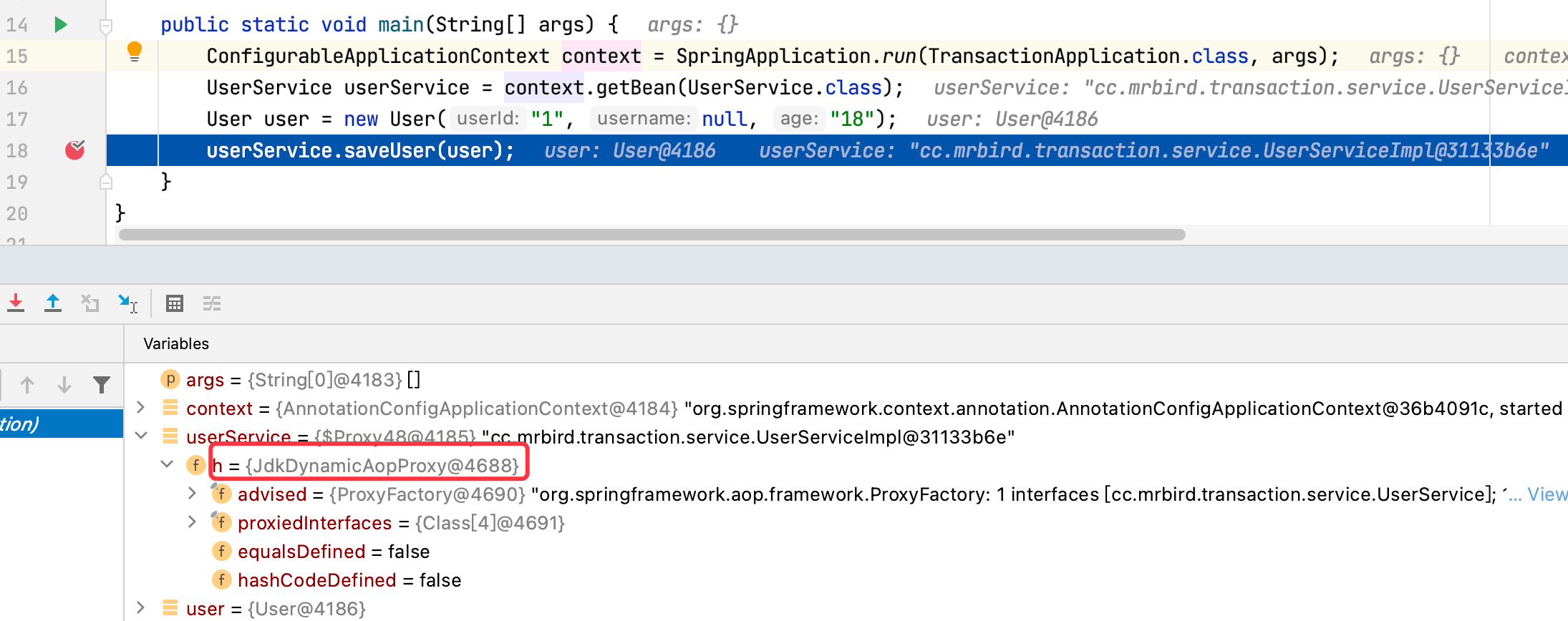
可以看到目标对象已经被JDK代理(目标对象实现了接口,默认走JDK动态代理。可以通过spring.aop.proxy-target-class=true配置来强制使用cglib代理,需要额外引入AOP自动装配依赖)。
在断点处执行Step Into,程序跳转到JdkDynamicAopProxy的invoke方法:
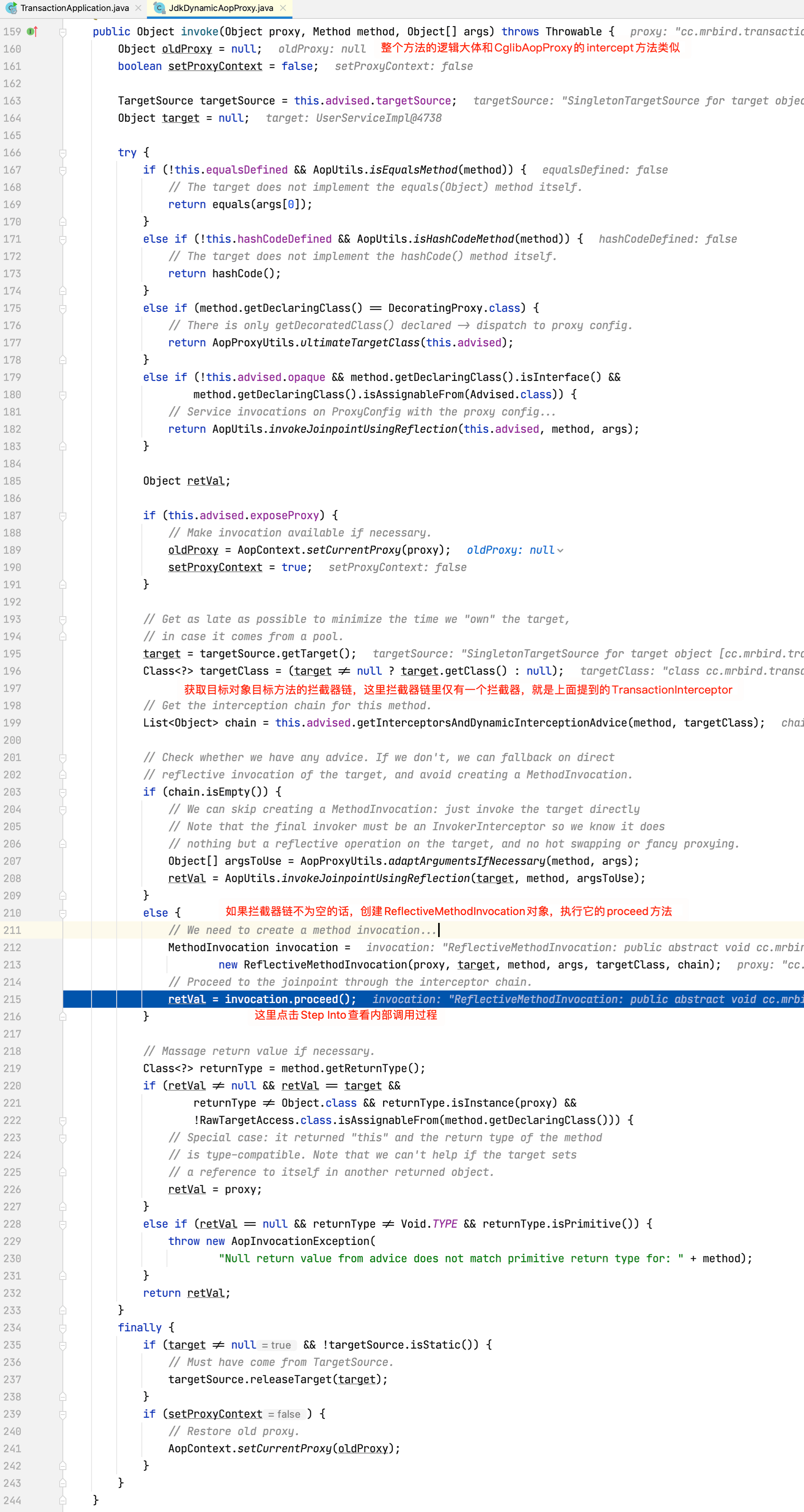
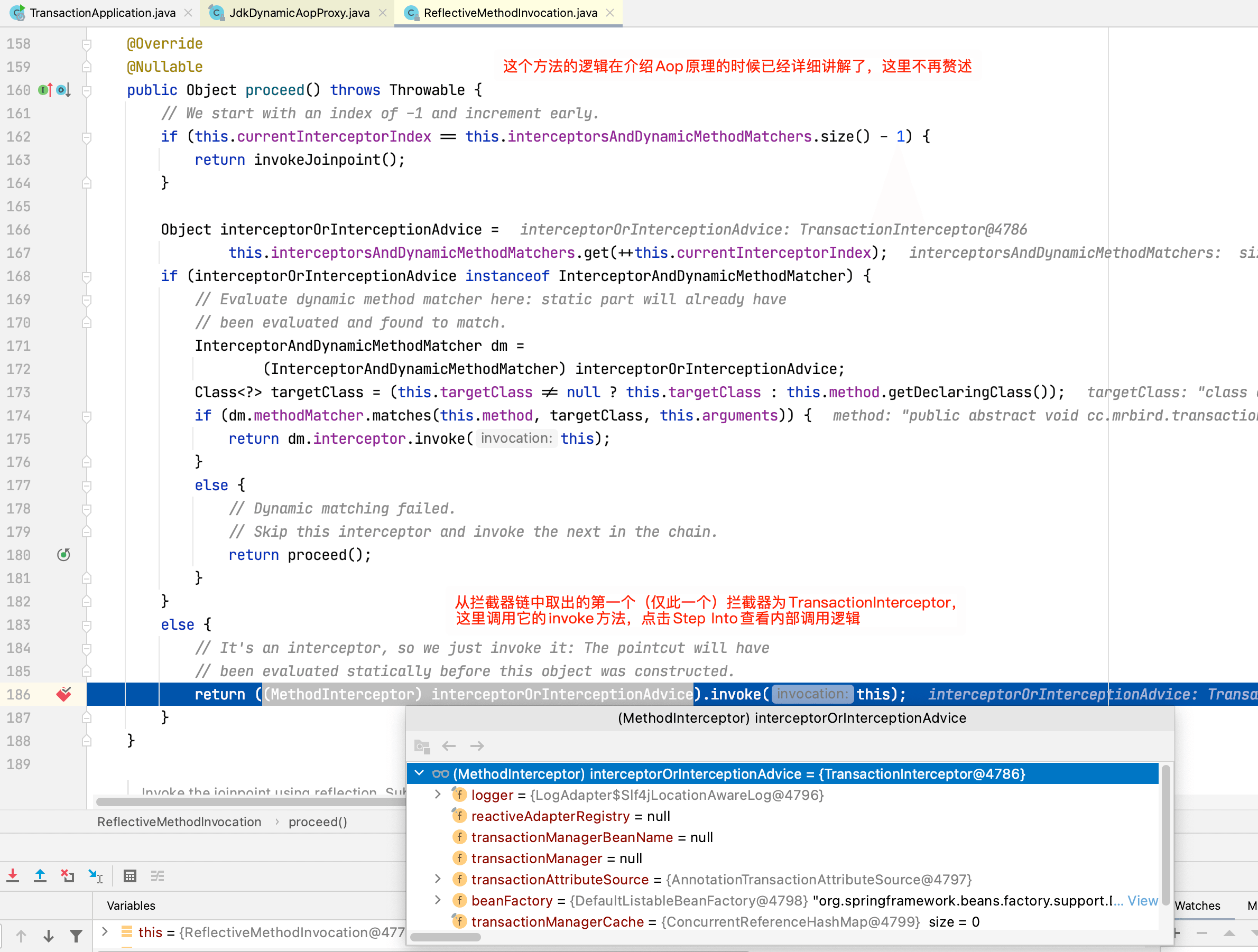
程序跳转到TransactionInterceptor的invoke方法:
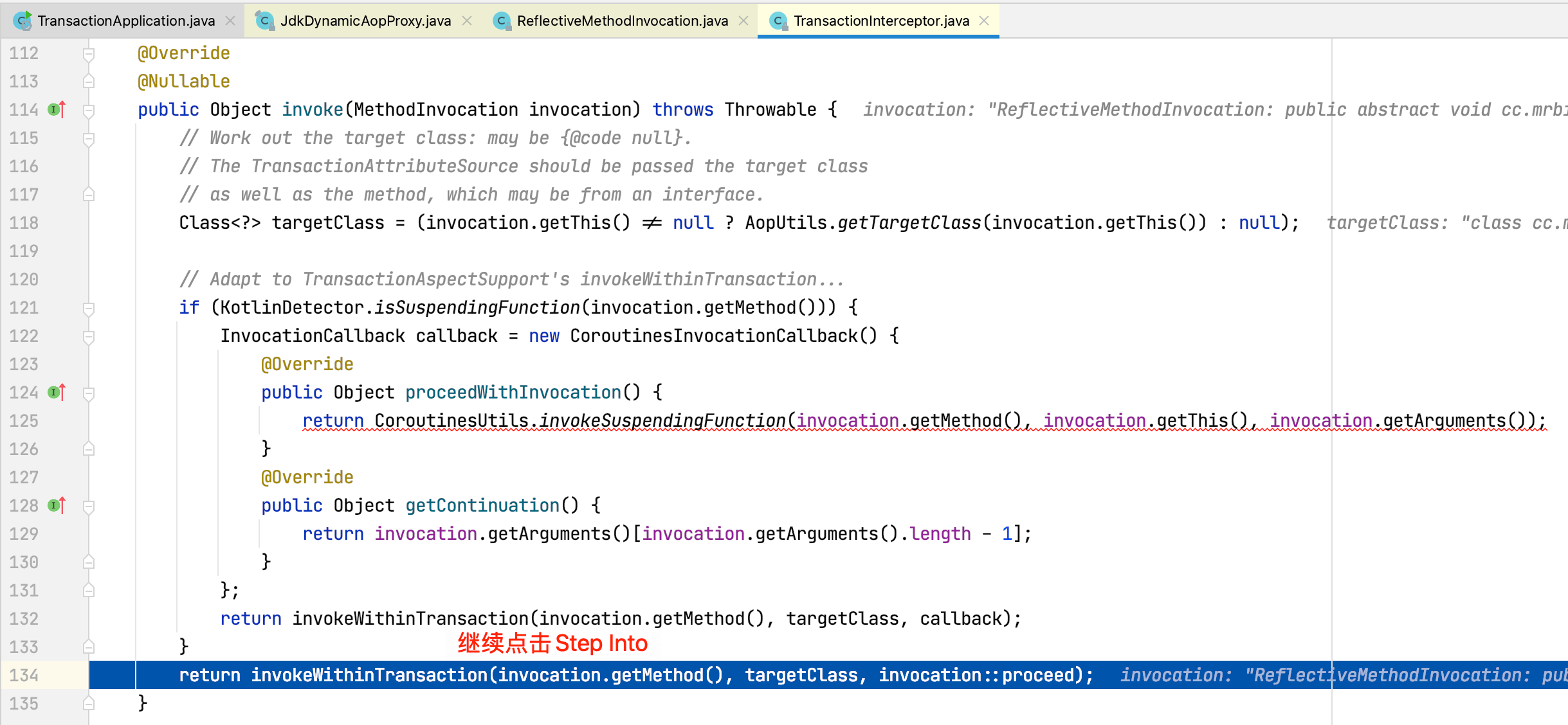
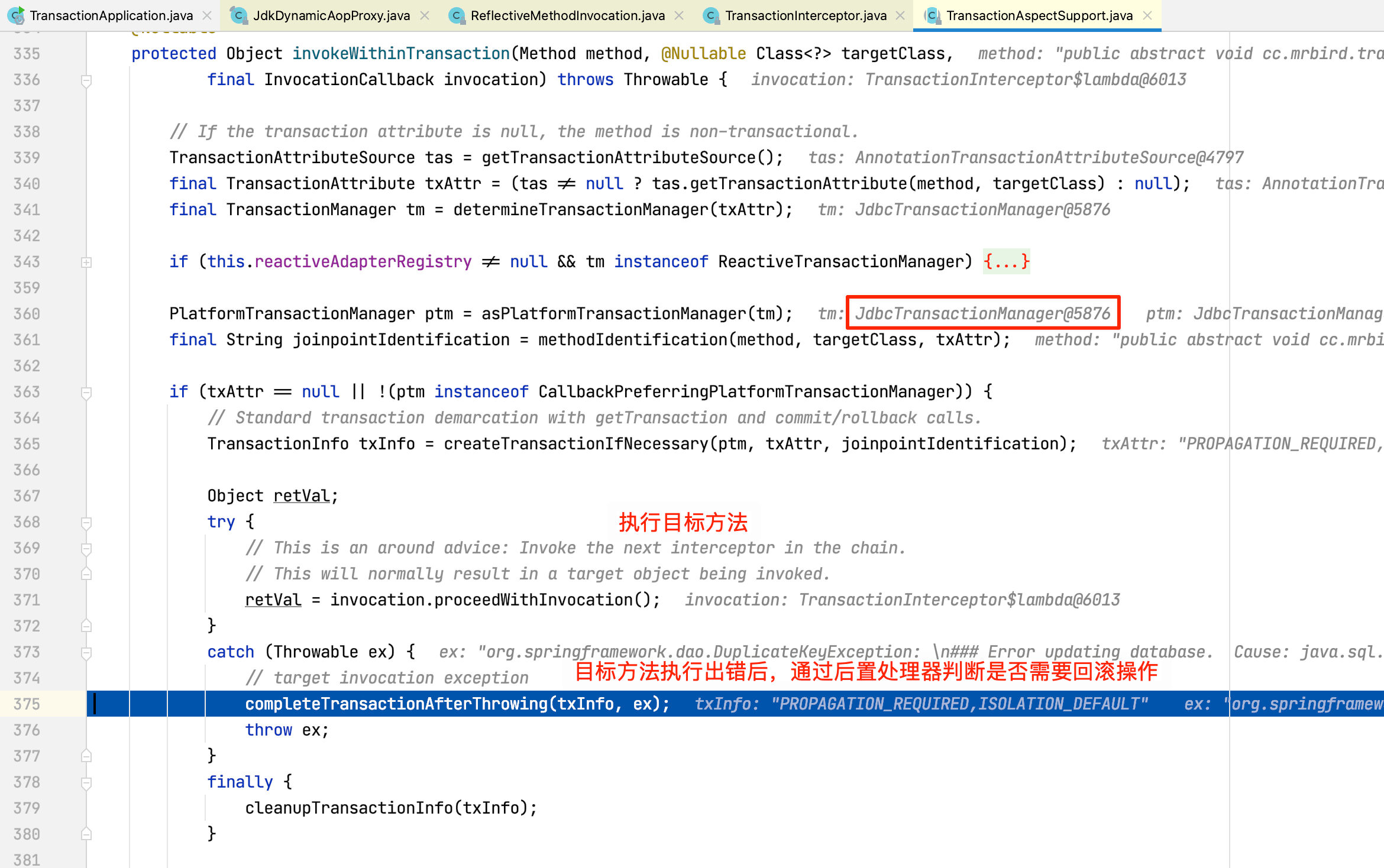
可以看到整个过程和深入理解Spring-AOP原理一文介绍的一致。
对Spring事务机制不熟悉的coder经常会遇到事务不生效的场景,这里列举两个最为常见的场景,并给出对应的解决方案。
Service方法抛出的异常不是RuntimeException或者Error类型,并且@Transactional注解上没有指定回滚异常类型。
对应的代码例子为:
1 |
|
这冲情况下,Spring并不会进行事务回滚操作。
正如@Transactional注解源码注释所述的那样:
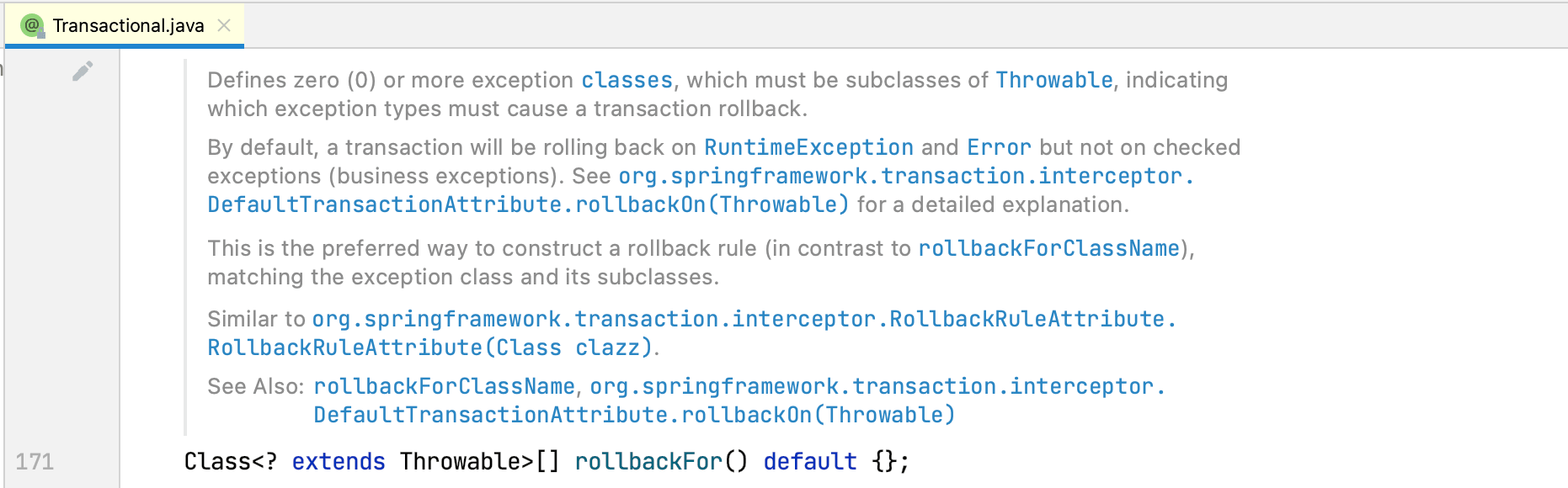
默认情况下,Spring事务只对RuntimeException或者Error类型异常(错误)进行回滚,检查异常(通常为业务类异常)不会导致事务回滚。。
所以要解决上面这个事务不生效的问题,我们主要有以下两种方式:
手动在@Transactional注解上声明回滚的异常类型(方法抛出该异常及其所有子类型异常都能触发事务回滚):
1 |
|
方法内手动抛出的检查异常类型改为RuntimeException子类型:
定义一个自定义异常类型ParamInvalidException:
1 | public class ParamInvalidException extends RuntimeException{ |
修改UserServiceImpl的saveUser方法:
1 |
|
这两种方式都能让事务按照我们的预期生效。
非事务方法直接通过this调用本类事务方法。这种情况也是比较常见的,举个例子,修改UserServiceImpl:
1 |
|
在UserServiceImpl中,我们新增了saveUserTest方法,该方法没有使用@Transactional注解标注,为非事务方法,内部直接调用了saveUser事务方法。
在入口类里测试该方法的调用:
1 |
|
启动程序,观察数据库数据:

可以看到,事务并没有回滚,数据已经被插入到了数据库中。
这种情况下事务失效的原因为:Spring事务控制使用AOP代理实现,通过对目标对象的代理来增强目标方法。而上面例子直接通过this调用本类的方法的时候,this的指向并非代理类,而是该类本身。
使用debug来验证this是否为代理对象:
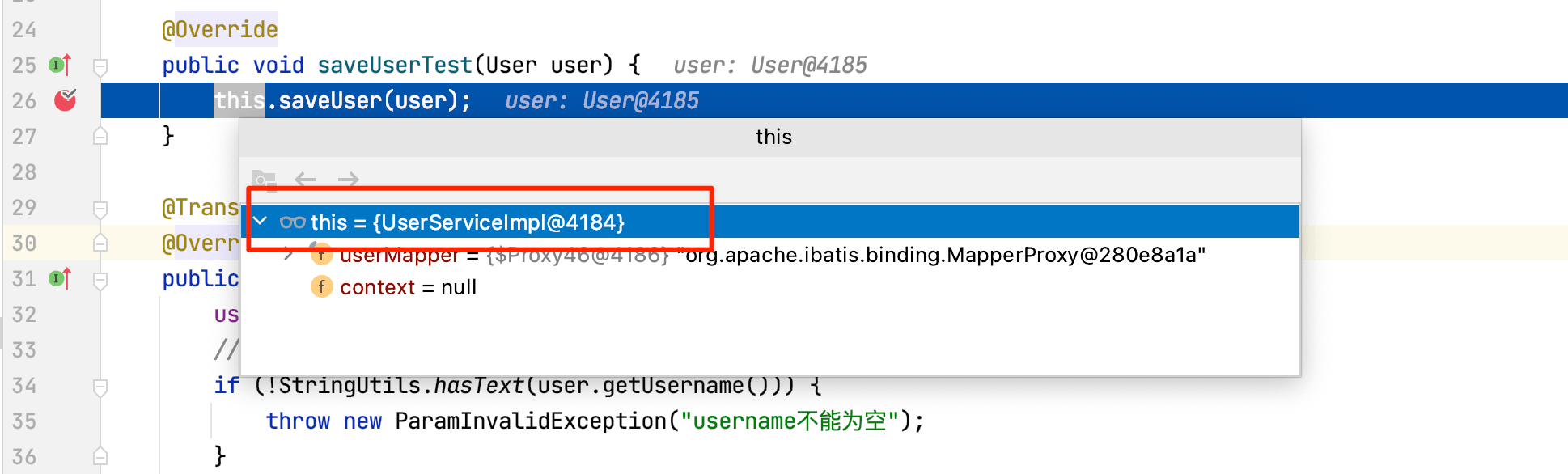
这种情况下要让事务生效主要有如下两种解决方式(原理都是使用代理对象来替代this):
1 |
|
上面代码我们通过实现ApplicationContextAware接口注入了应用上下文ApplicationContext,然后从中取出UserService Bean来代替this。
从AOP上下文中取出当前代理对象:
这种情况首先需要引入AOP Starter:
1 | <dependency> |
然后在SpringBoot入口类中通过注解@EnableAspectJAutoProxy(exposeProxy = true)将当前代理对象暴露到AOP上下文中(通过AopContext的ThreadLocal实现)。
最后在UserServcieImpl的saveUserTest方法中通过AopContext获取UserServce的代理对象:
1 |
|
AOP底层为动态代理,AOP指的是:在程序运行期间动态地将某段代码切入到指定方法指定位置进行运行的编程方式,相关设计模式为代理模式。本节将通过一个简单的例子回顾Spring AOP的使用,并且通过debug源码深入理解内部原理。hints:本节图片较多,加载较慢。
新建一个SpringBoot项目,SpringBoot版本为2.4.0,引入如下两个依赖:
1 | <dependencies> |
然后创建一个目标类TatgetClass,包含待会需要被AOP代理增强的方法test:
1 |
|
编写切面类MyAspect:
1 |
|
该切面包含了4个通知方法:
这几个通知的顺序在不同的Spring版本中有所不同:
Spring4.x
Spring5.x
具体可以参考这篇博客:https://www.cnblogs.com/orzjiangxiaoyu/p/13869747.html。通知顺序并不影响本文对SpringAOP源码的理解。
在SpringBoot入口类测试AOP结果:
1 |
|
主要逻辑为从IOC容器中获取TargetClass Bean,然后调用其test方法,程序运行结果如下:
1 | onBefore:test方法开始执行,参数:[aop] |
test方法参数为空时,程序运行结果如下:
1 | onBefore:test方法开始执行,参数:[] |
可以看到,我们成功通过Spring AOP将各个通知方法织入到了目标方法的各个执行阶段,下面我们就来深入探究Spring AOP的实现原理。
前面我们引入了Spring AOP开箱即用的starterspring-boot-starter-aop,@Enable模块驱动注解EnableAspectJAutoProxy用于开启AspectJ自动代理,源码如下所示:
1 | ({ElementType.TYPE}) |
该注解类上通过@Import导入了AspectJAutoProxyRegistrarAspectJ自动代理注册器(对@Import不了解的读者可以参考深入学习Spring组件注册),查看AspectJAutoProxyRegistrar的源码:

通过注释我们大体可以知道,该注册器的作用是往IOC容器里注册了一个类型为AnnotationAwareAspectJAutoProxyCreator(注解驱动的AspectJ自动代理创建器)的Bean。该类的registerBeanDefinitions方法主要关注:
1 | AopConfigUtils.registerAspectJAnnotationAutoProxyCreatorIfNecessary(registry); |
查看其源码:

可以看到,核心逻辑为通过RootBeanDefinition往IOC注册了名称为AUTO_PROXY_CREATOR_BEAN_NAME(常量,值为org.springframework.aop.config.internalAutoProxyCreator),类型为AnnotationAwareAspectJAutoProxyCreator的Bean(对这种通过ImportBeanDefinitionRegistrar往IOC注册Bean方式不了解的读者可以参考深入学习Spring组件注册)。
@EnableAspectJAutoProxy模块驱动注解往IOC容器中注册了类型为AnnotationAwareAspectJAutoProxyCreator的Bean,Bean名称为org.springframework.aop.config.internalAutoProxyCreator。通过前面的分析,我们的目光聚焦在AnnotationAwareAspectJAutoProxyCreator类上,为了搞清楚这个类的作用,我们先捋清类的层级关系:
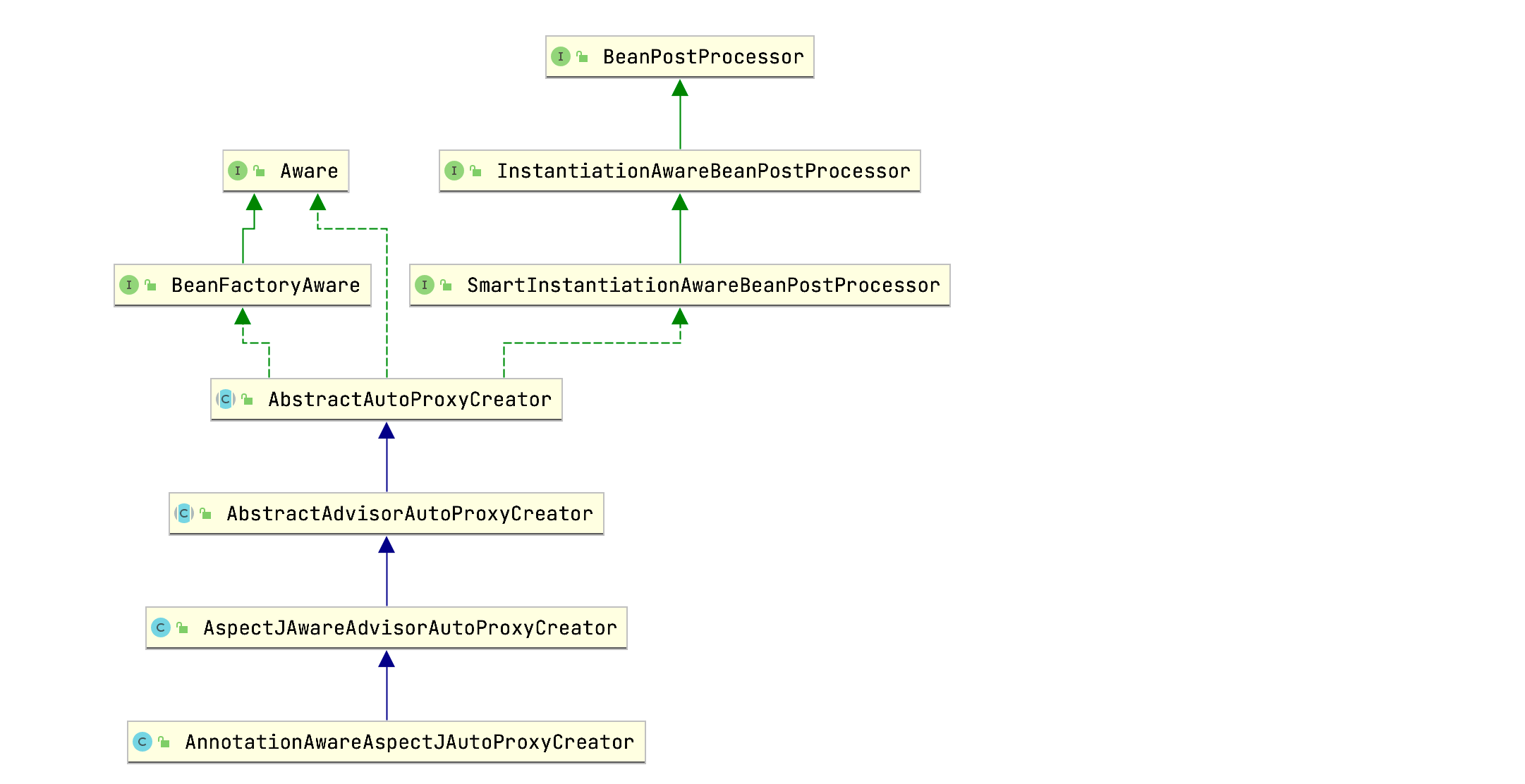
可以看到AnnotationAwareAspectJAutoProxyCreator的父类AbstractAutoProxyCreator实现了SmartInstantiationAwareBeanPostProcessor和BeanFactoryAware接口。实现BeanFactoryAware用于在Bean初始化时注入BeanFactory,而SmartInstantiationAwareBeanPostProcessor接口的父类为InstantiationAwareBeanPostProcessor接口,该接口继承自BeanPostProcessor接口。
通过深入理解Spring BeanPostProcessor & InstantiationAwareBeanPostProcessor一节的学习,我们知道BeanPostProcessor接口和InstantiationAwareBeanPostProcessor接口包含一些用于Bean实例化初始化前后进行自定义操作的方法,所以我们大体可以猜测出目标Bean的代理是在这些接口方法里实现的。
通过查看AnnotationAwareAspectJAutoProxyCreator及其各个层级父类源码可以发现,AbstractAutoProxyCreator类实现了InstantiationAwareBeanPostProcessor接口的postProcessBeforeInstantiation方法(自定义Bean实例化前操作逻辑),实现了BeanPostProcessor的postProcessAfterInitialization方法(自定义Bean初始化后操作逻辑),所以我们在这两个方法上打个端点,用于后续debug:
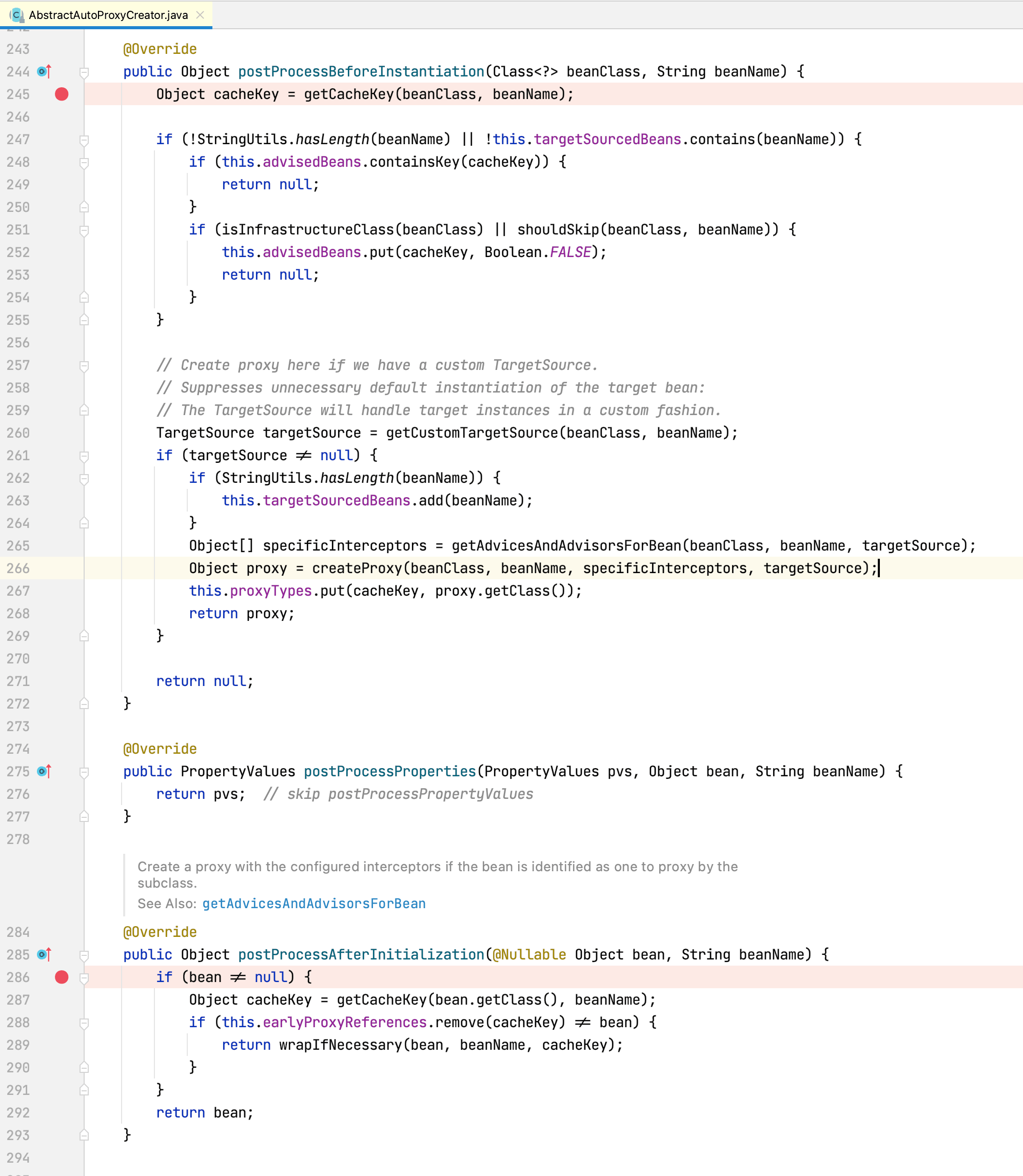
我们以debug的方式启动前面的AOP例子,因为后置处理器对所有Bean都生效,所以每个Bean创建时都会进入我们刚刚打断点的那两个方法中。但我们只关心Spring AOP是怎样增强我们定义的目标类TargetClass的,所以如果Bean类型不是TargetClass,我们都直接点击Resume Program按钮跳过,直到Bean类型是TargetClass:

postProcessBeforeInstantiation方法主要包含以下几个核心步骤:

通过Bean名称和Bean类型获取该Bean的唯一缓存键名,getCacheKey方法源码如下所示:

在这里,cacheKey的值为targetClass。
判断当前Bean(TargetClass)是否包含在advisedBeans集合中(AbstractAutoProxyCreator的成员变量private final Map<Object, Boolean> advisedBeans = new ConcurrentHashMap<>(256),用于存放所有Bean是否需要增强标识,键为每个Bean的cacheKey,值为布尔类型,true表示需要增强,false表示不需要增强),此时TargetClass还未实例化,所以自然不在该集合中。
判断当前Bean(TargetClass)是否是基础类,查看isInfrastructureClass方法源码:
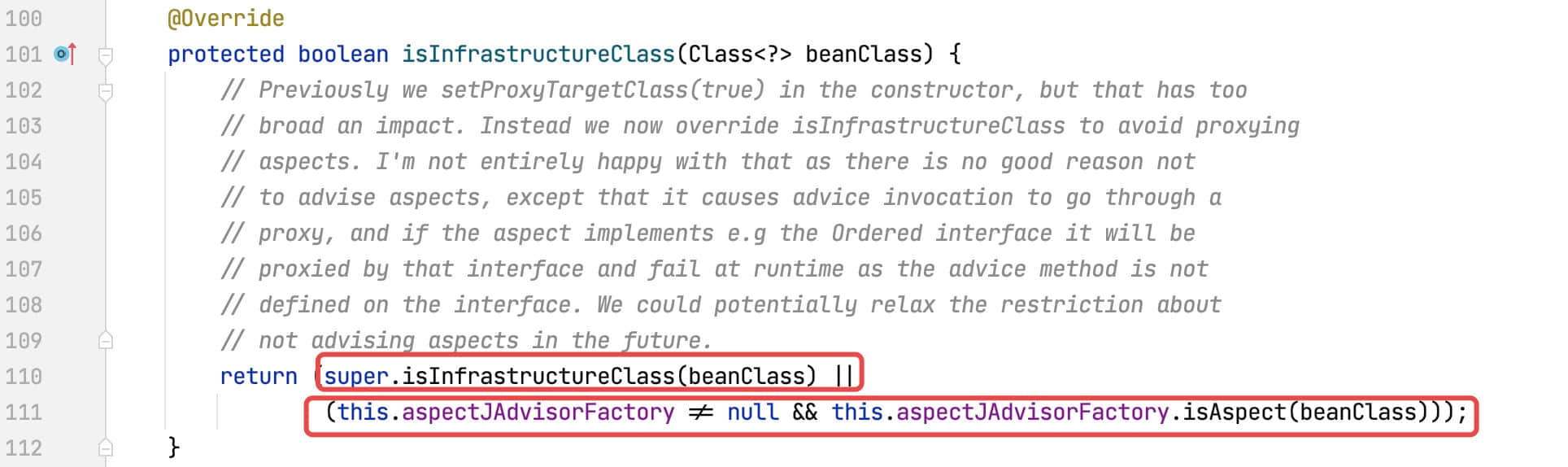
方法调用了父类的isInfrastructureClass方法:

this.aspectJAdvisorFactory.isAspect方法源码如下所示:

所以这一步逻辑为:判断当前Bean(TargetClass)是否是Advice,Pointcut,Advisor,AopInfrastructureBean的子类或者是否为切面类(@Aspect注解标注)。
判断是否需要跳过:
shouldSkip源码如下所示:

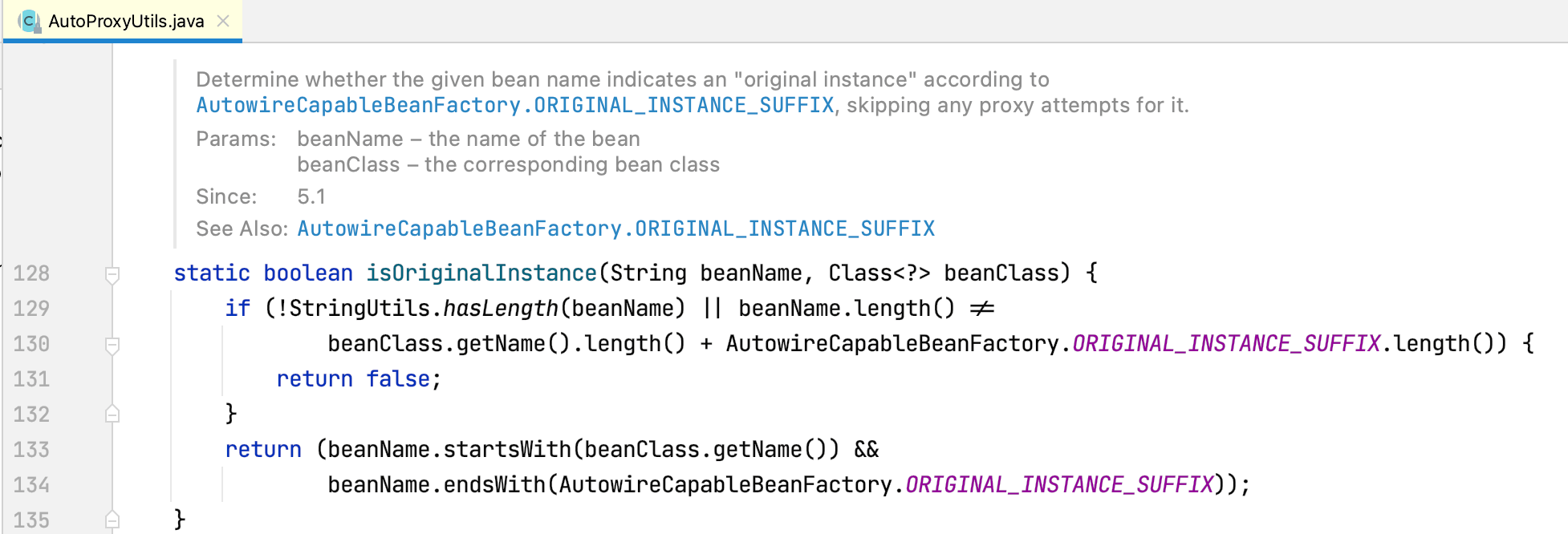
通过Bean名称判断是否以AutowireCapableBeanFactory.ORIGINAL_INSTANCE_SUFFIX(.ORIGINAL)结尾,是的话返回true表示跳过代理。
很明显我们的TargetClass不符合3和4,所以继续走第5步。
如果我们自定义了TargetSource,则在此处创建Bean代理,以取代目标Bean的后续默认实例化方式。我们并没有自定义TargetSource,所以直接跳过。
经过以上这些步骤,就TargetClass这个Bean而言,postProcessBeforeInstantiation方法最终返回null。Bean实例化前置处理到此完毕,点击Resume Program,继续Bean的后续生命周期处理逻辑,程序跳转到Bean初始化后置处理方法postProcessAfterInitialization:

该方法重点关注wrapIfNecessary方法,查看wrapIfNecessary方法源码:
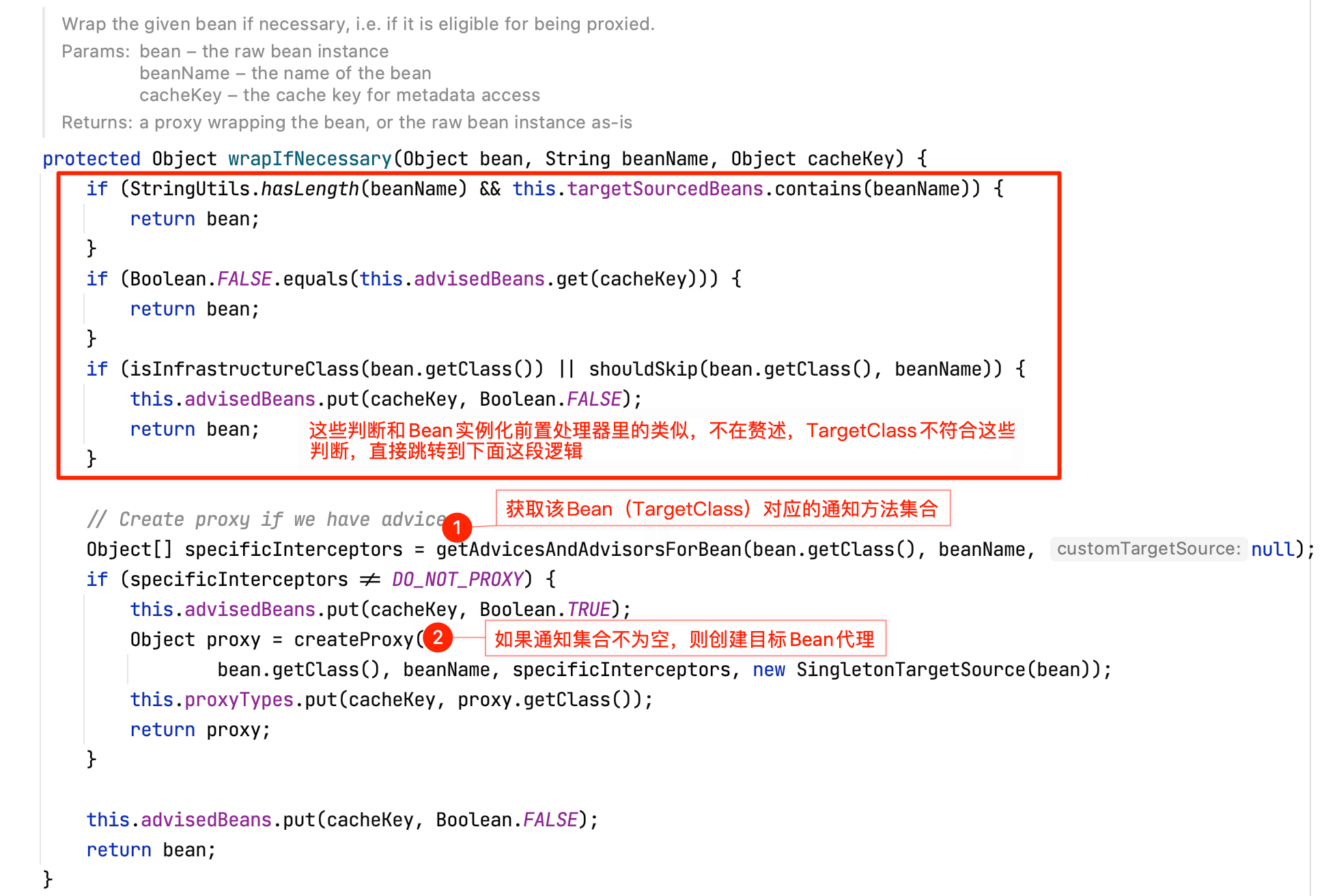
getAdvicesAndAdvisorsForBean方法内部主要包含以下这些逻辑(有兴趣自己debug查看具体判断逻辑实现,这里不再贴图,只做总结):
在前面的AOP例子中,切面MyAspect里的通知方法就是为了增强TargetClass所设的(根据切点表达式),所以getAdvicesAndAdvisorsForBean方法返回值如下所示:
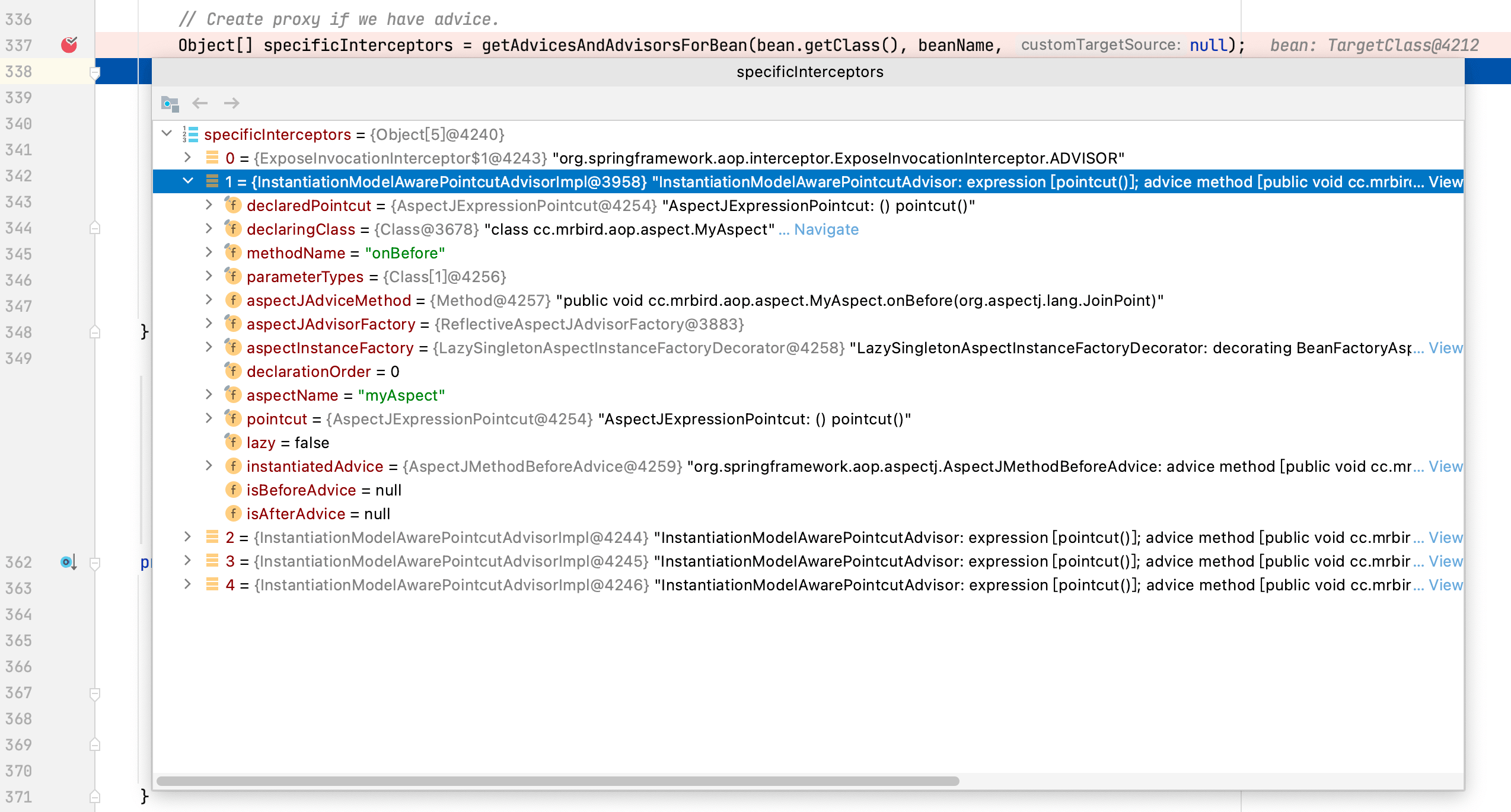
这些通知方法就是我们在MyAspect切面里定义的通知方法:

如果该Bean的通知方法集合不为空的话,则创建该Bean的代理对象,具体查看createProxy方法源码:

继续跟踪proxyFactory.getProxy(getProxyClassLoader())源码:



Spring会判断当前使用哪种代理对象(一般来说当Bean有实现接口时,使用JDK动态代理,当Bean没有实现接口时,使用cglib代理,在Boot中,我们可以通过spring.aop.proxy-target-class=true配置来强制使用cglib代理)。
通过Bean初始化后置代理方法postProcessBeforeInstantiation处理后,TargetClass被包装为了cglib代理的增强Bean,注册到IOC容器中:
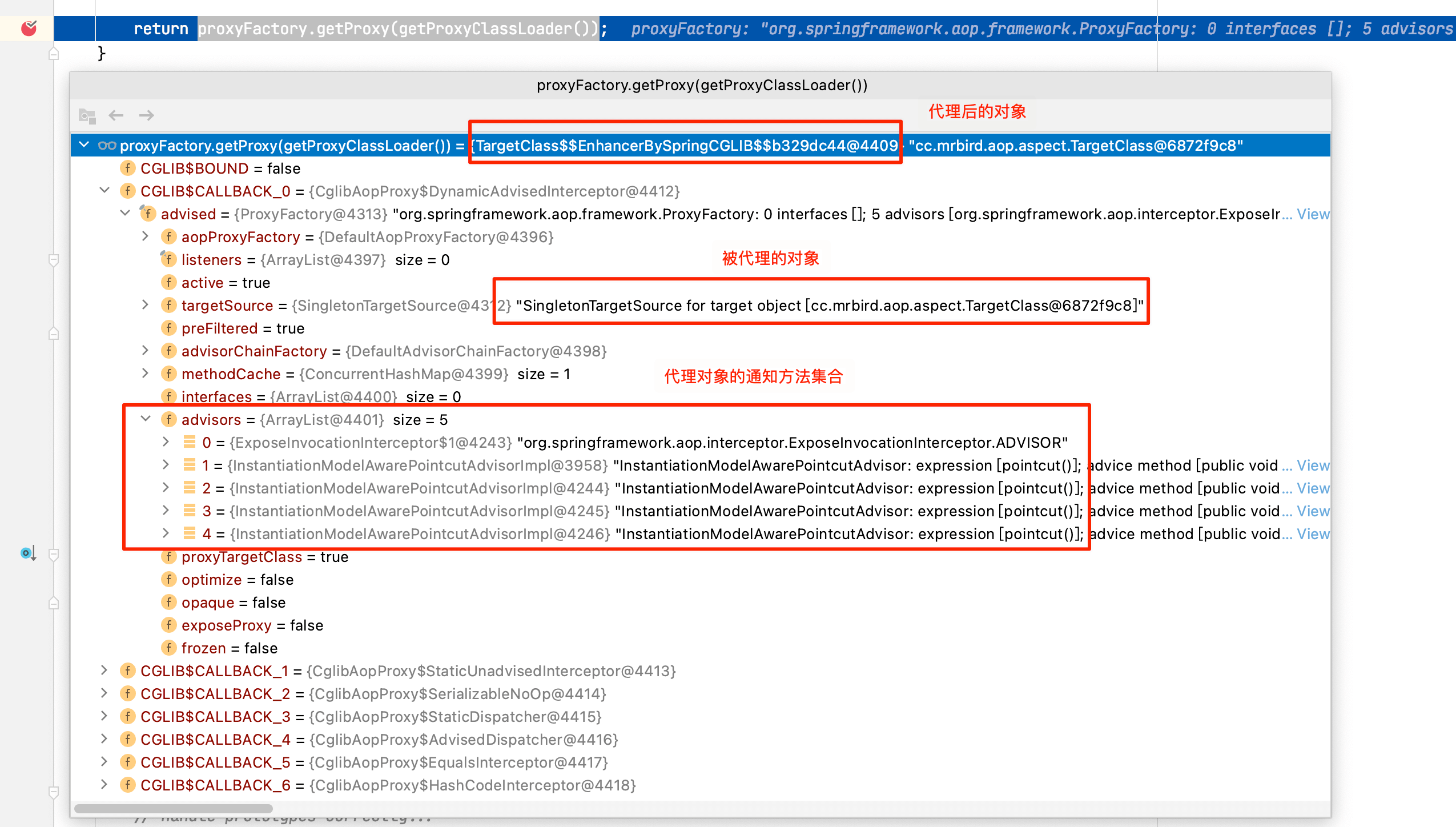
后续从IOC容器中获得的TargetClass就是被代理后的对象,执行代理对象的目标方法的时候,代理对象会执行相应的通知方法链,下面接着分析。
AOP代理对象生成后,我们接着关注代理对象的目标方法执行时,通知方法是怎么被执行的。
先将前面打的断点都去掉,然后在SpringBoot的入口类AopApplication的如下位置打个断点:

以debug方式启动程序:
可以看到获取到的TargetClass Bean就是前面cglib代理后的Bean(TargetClass$$EnhanceBySpringCGLIB):
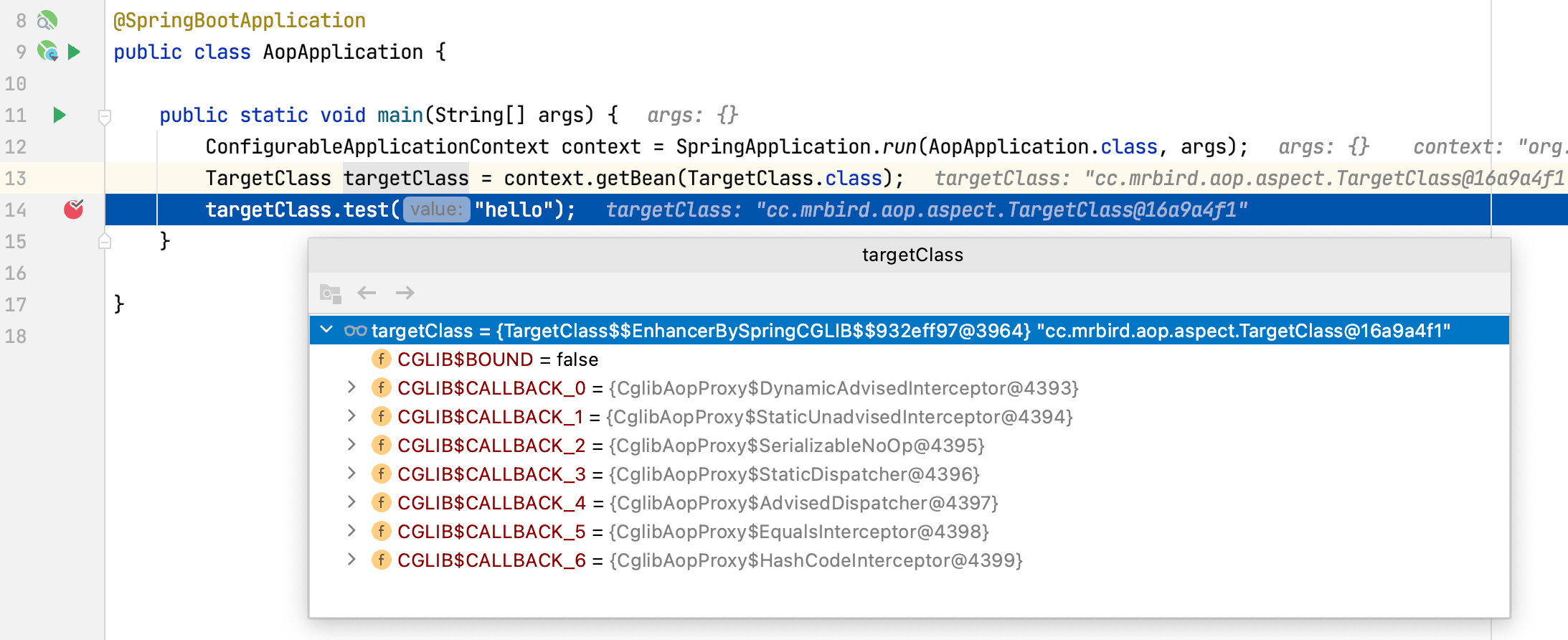
点击Step Into进入test方法内部调用逻辑,会发现程序跳转到了CglibAopProxy的intercept方法中,也就是说我们的目标对象的目标方法被CglibAopProxy的intercept方法拦截了,该拦截方法主要逻辑如下:
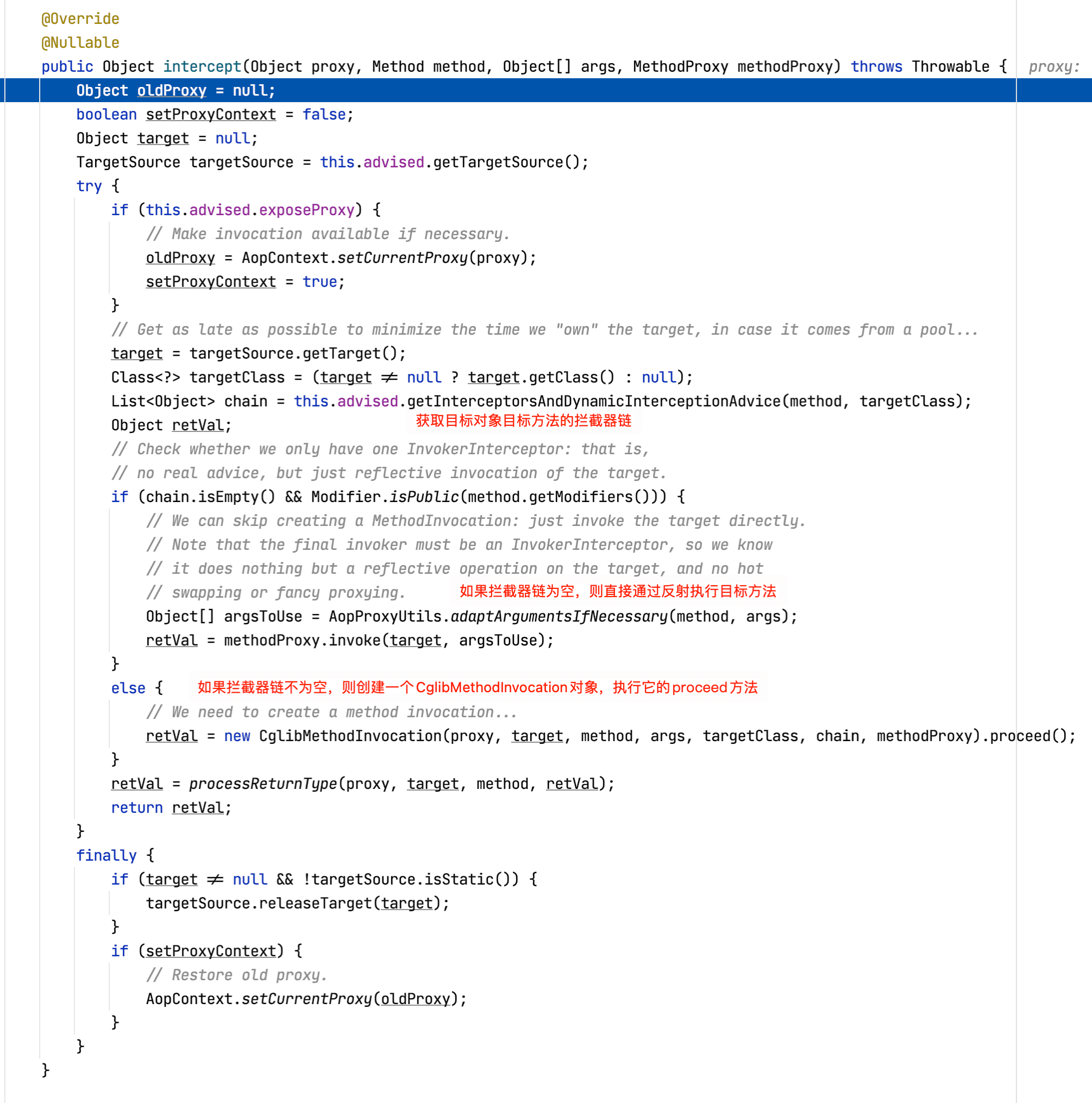
这里先重点关注下getInterceptorsAndDynamicInterceptionAdvice方法,其源码如下所示:

图中错别字纠正:提供->提高,懒得再次截图注释了😢
继续查看this.advisorChainFactory.getInterceptorsAndDynamicInterceptionAdvice源码:

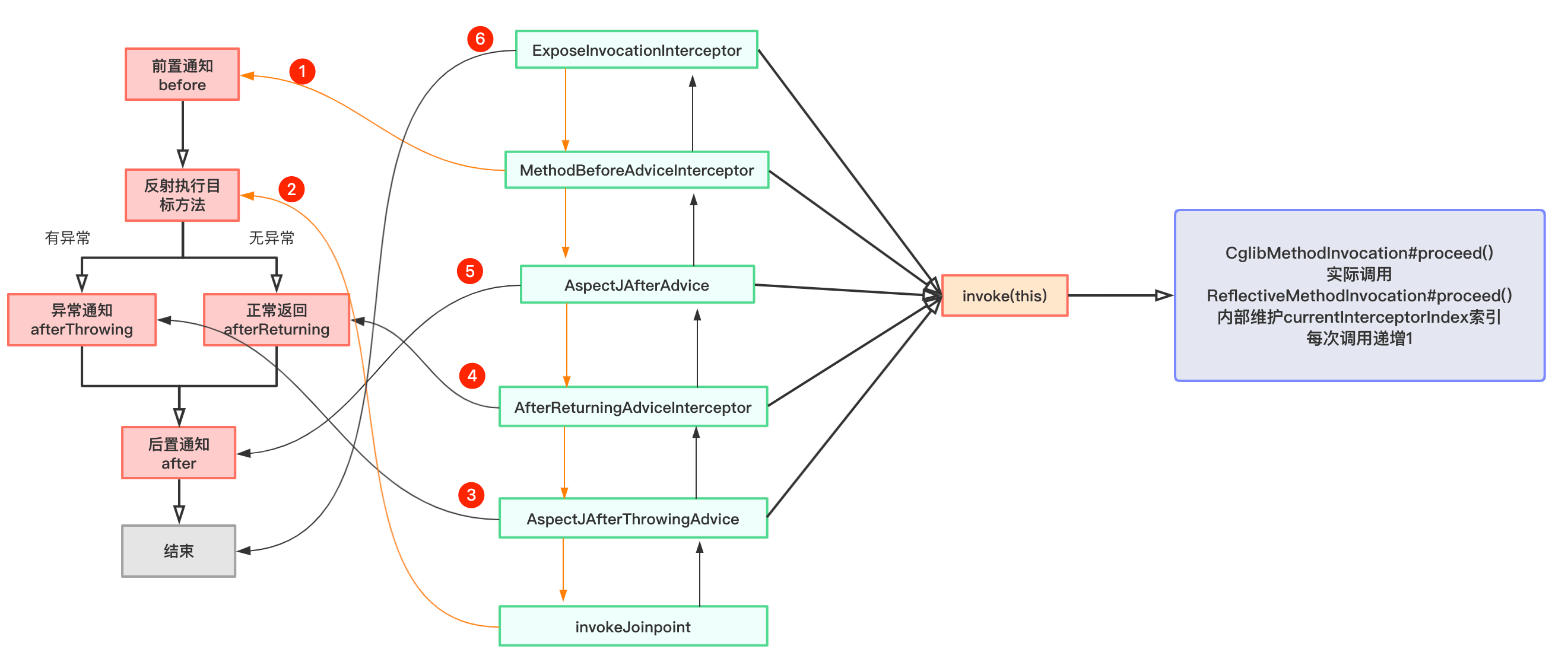
通过debug我们可以看到,当前代理对象的test方法的拦截器链不为空,并且元素个数为5:
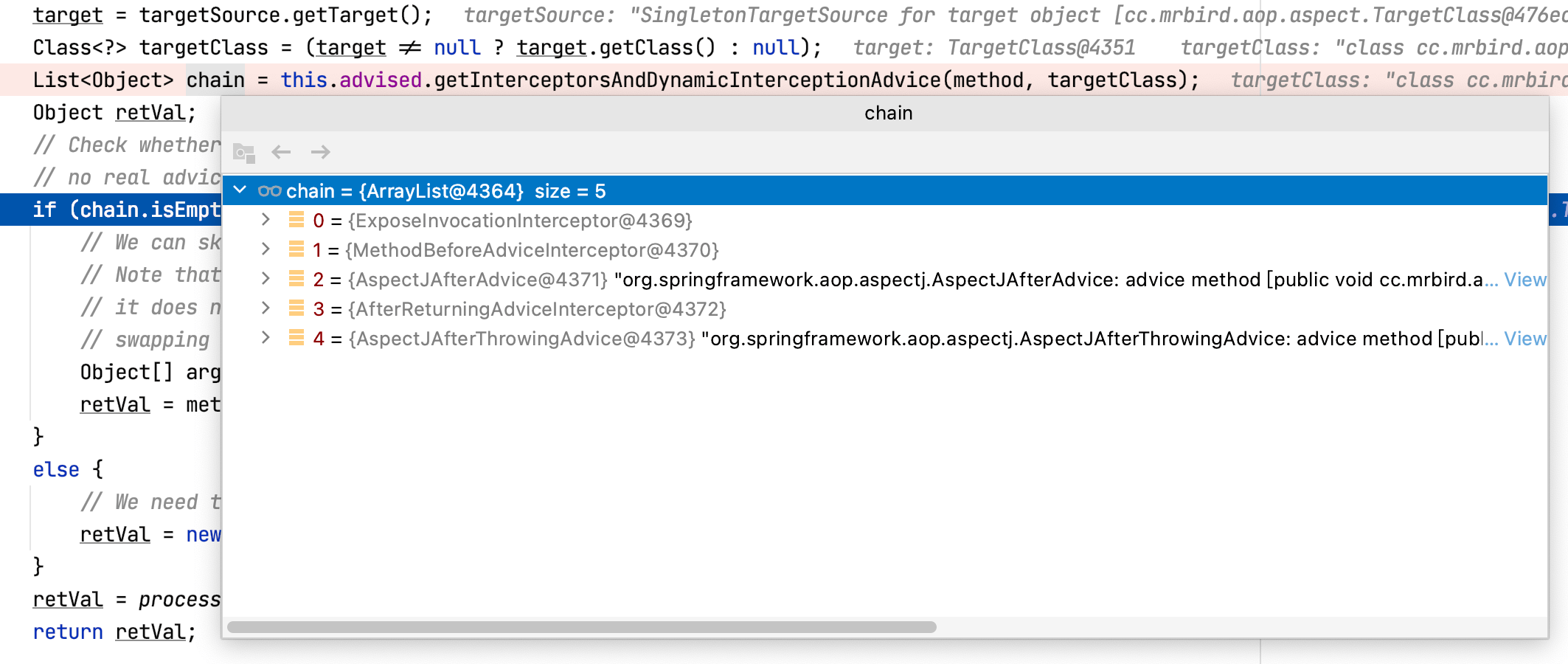
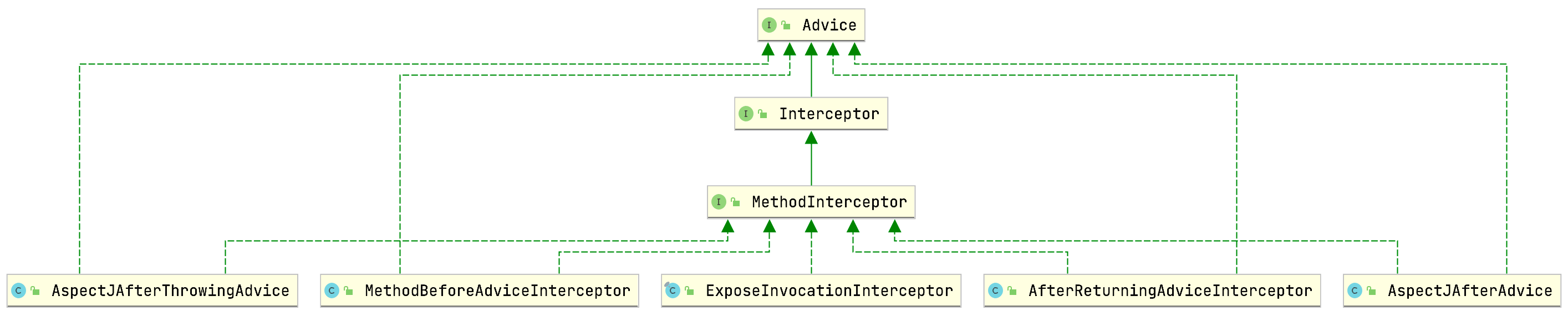
拦截器链第一个元素类型为ExposeInvocationInterceptor,是默认的拦截器,后面会介绍到它的作用。剩下四个依次为:MethodBeforeAdviceInterceptor、AspectJAfterAdvice、AfterReturningAdviceInterceptor和AspectJAfterThrowingAdvice,它们都是MethodInterceptor的实现类:
获取到了代理对象目标方法的拦截器链后,我们最后来关注这些拦截器是如何链式调用通知方法的。获取拦截器链并且拦截器链不为空时,CglibAopProxy的intercept方法创建CglibMethodInvocation对象,并调用它的proceed方法:
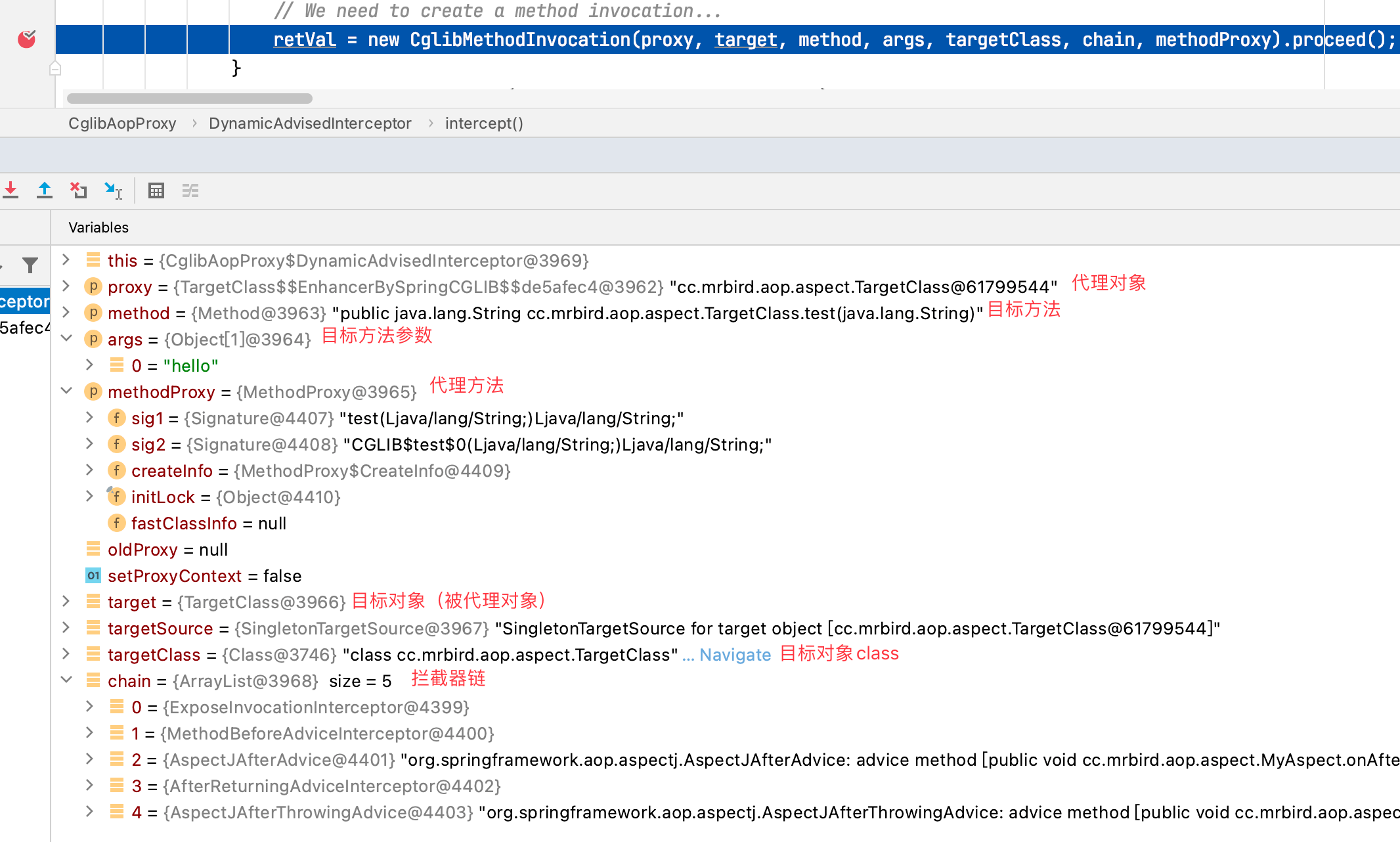
查看CglibMethodInvocation源码:

查看CglibMethodInvocation父类ReflectiveMethodInvocation proceed方法源码:

清除掉之前打的断点,在该方法上第一行打个端点,重新以debug方式启动Boot应用:

程序第一次进该方法时currentInterceptorIndex值为-1,this.interceptorsAndDynamicMethodMatchers.get(++this.currentInterceptorIndex)取出拦截器链第一个拦截器ExposeInvocationInterceptor,方法最后调用该拦截器的invoke方法,Step Into进入该方法:

mi就是我们传入的ReflectiveMethodInvocation对象,程序执行到mi.proceed方法时,Step Into进入该方法:

可以看到,此时程序第二次执行ReflectiveMethodInvocation的poceed方法,currentInterceptorIndex值为0,this.interceptorsAndDynamicMethodMatchers.get(++this.currentInterceptorIndex)取出拦截器链第二个拦截器MethodBeforeAdviceInterceptor,方法最后调用该拦截器的invoke方法,Step Into进入该方法:
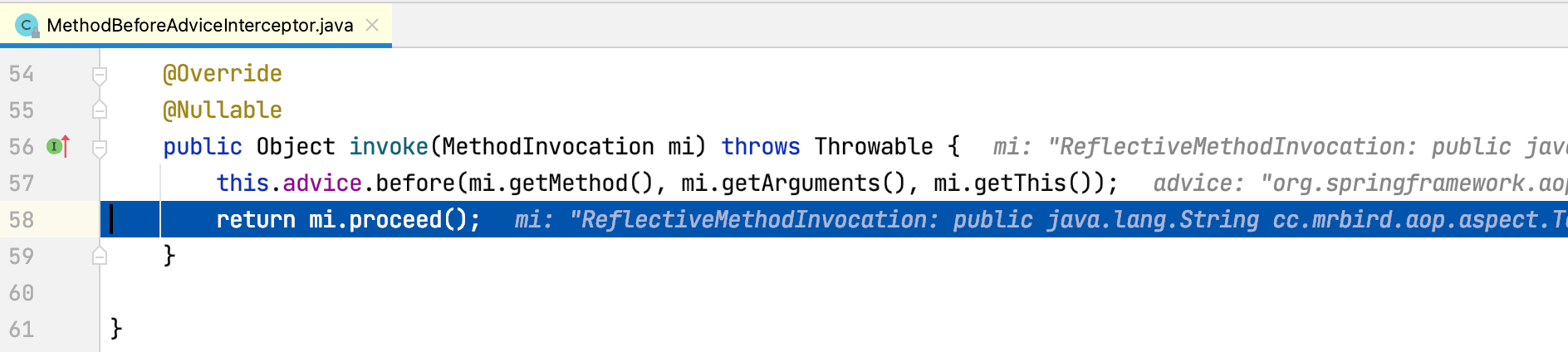
可以看到MethodBeforeAdviceInterceptor的invoke方法第一行调用了通知方法before,此时控制台打印内容为:
1 | onBefore:test方法开始执行,参数:[hello] |
接着又通过mi.proceed再次调用ReflectiveMethodInvocation的poceed方法,Step Into进入该方法:
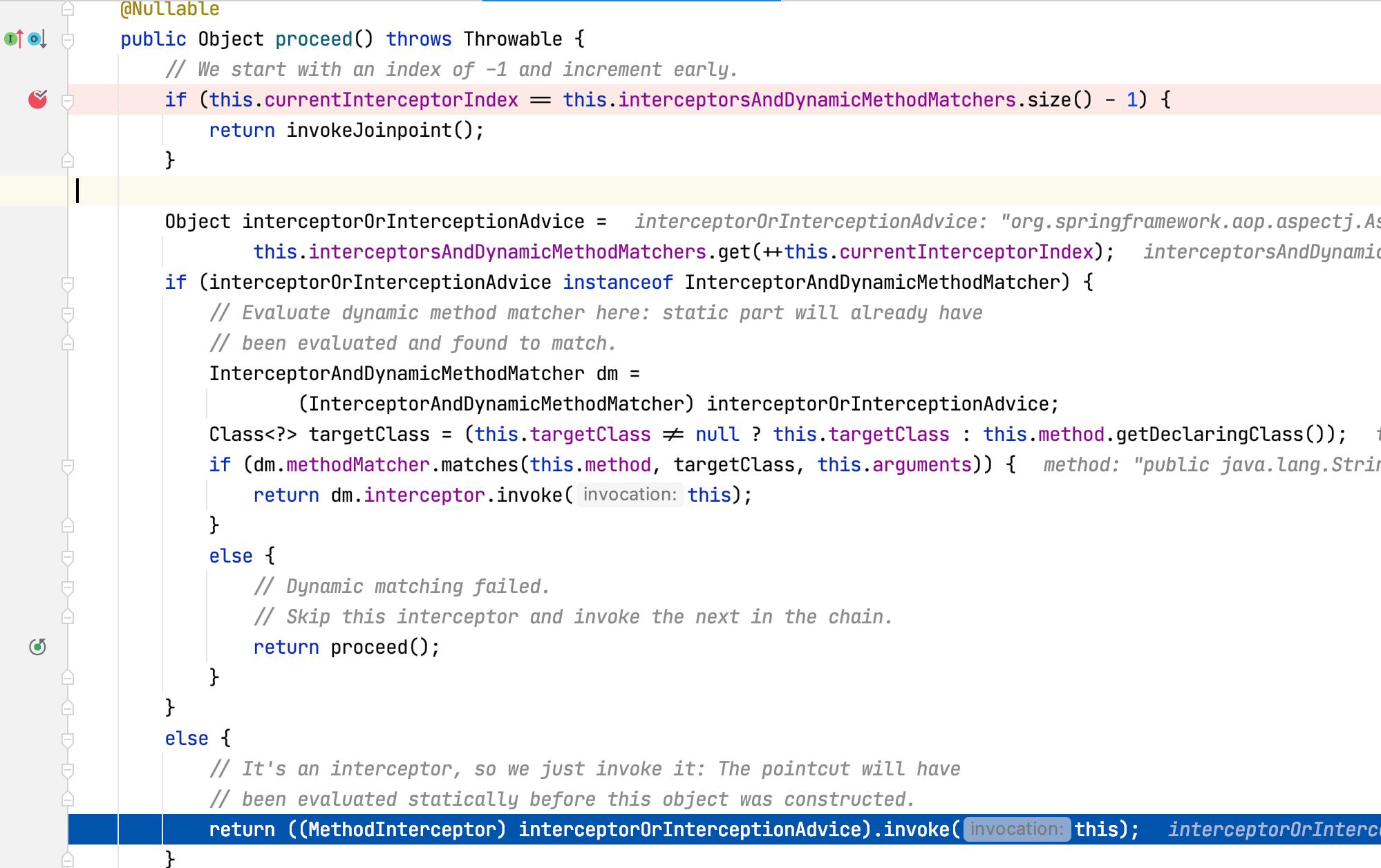
此时程序第三次执行ReflectiveMethodInvocation的poceed方法,currentInterceptorIndex值为1,this.interceptorsAndDynamicMethodMatchers.get(++this.currentInterceptorIndex)取出拦截器链第三个拦截器AspectJAfterAdvice,方法最后调用该拦截器的invoke方法,Step Into进入该方法:
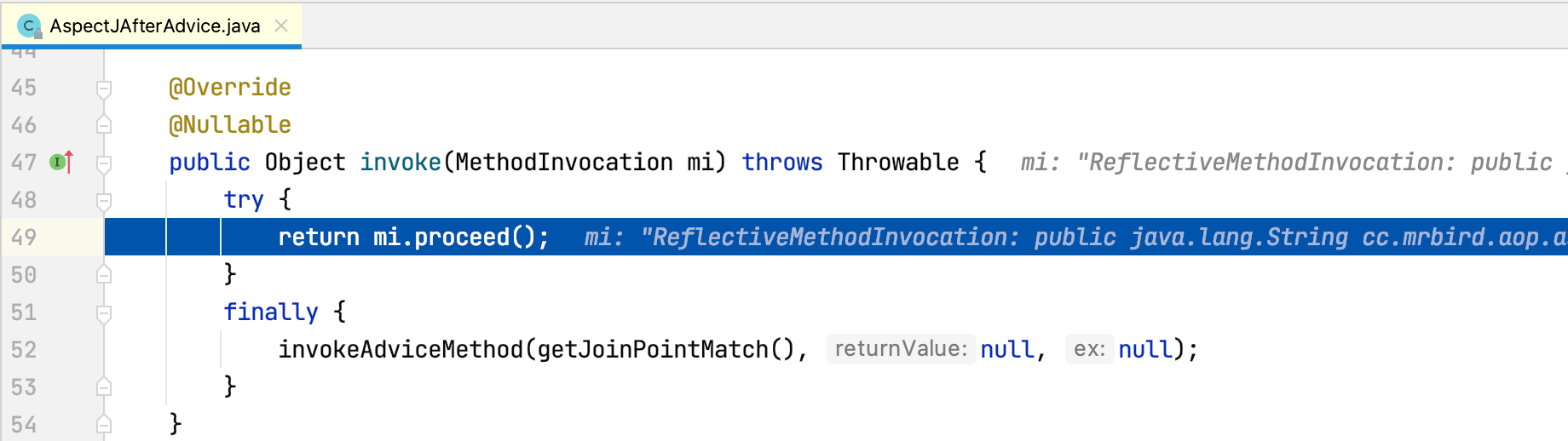
可以看到AspectJAfterAdvice的invoke方法内通过mi.proceed再次调用ReflectiveMethodInvocation的poceed方法,Step Into进入该方法:
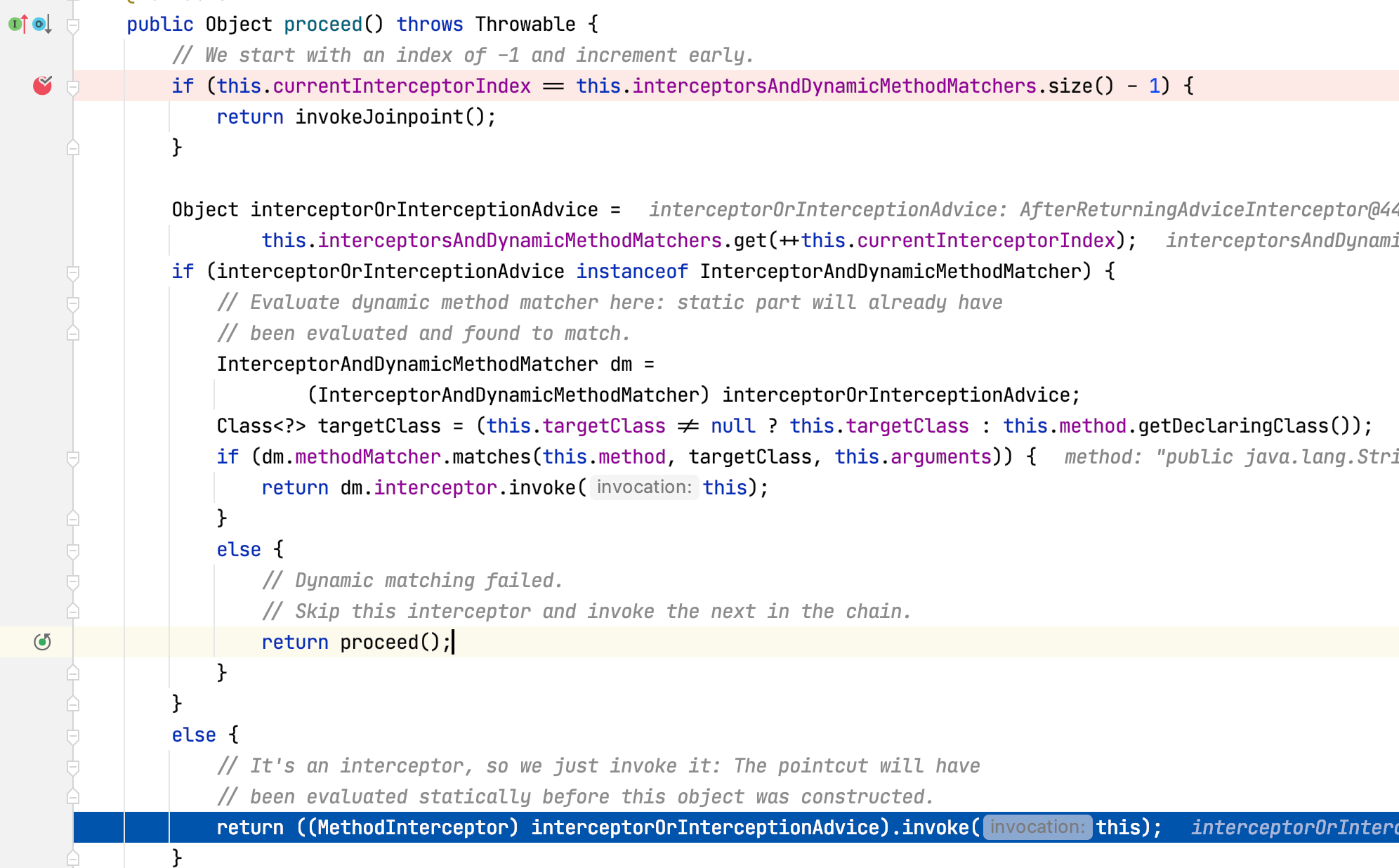
此时程序第四次执行ReflectiveMethodInvocation的poceed方法,currentInterceptorIndex值为2,this.interceptorsAndDynamicMethodMatchers.get(++this.currentInterceptorIndex)取出拦截器链第四个拦截器AfterReturningAdviceInterceptor,方法最后调用该拦截器的invoke方法,Step Into进入该方法:
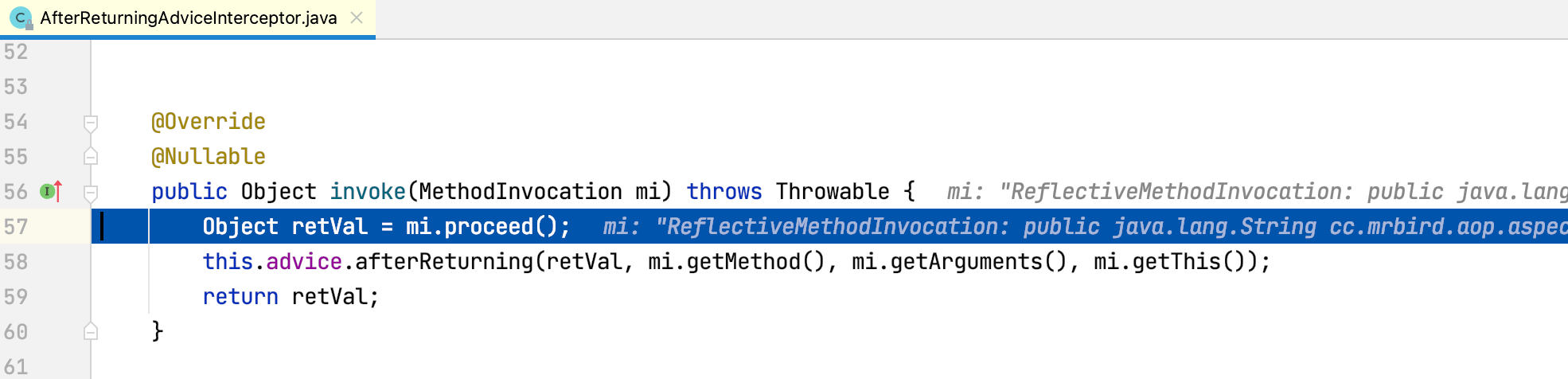
可以看到AfterReturningAdviceInterceptor的invoke方法内通过mi.proceed再次调用ReflectiveMethodInvocation的poceed方法,Step Into进入该方法:

此时程序第五次执行ReflectiveMethodInvocation的poceed方法,currentInterceptorIndex值为3,this.interceptorsAndDynamicMethodMatchers.get(++this.currentInterceptorIndex)取出拦截器链第五个拦截器AspectJAfterThrowingAdvice,方法最后调用该拦截器的invoke方法,Step Into进入该方法:
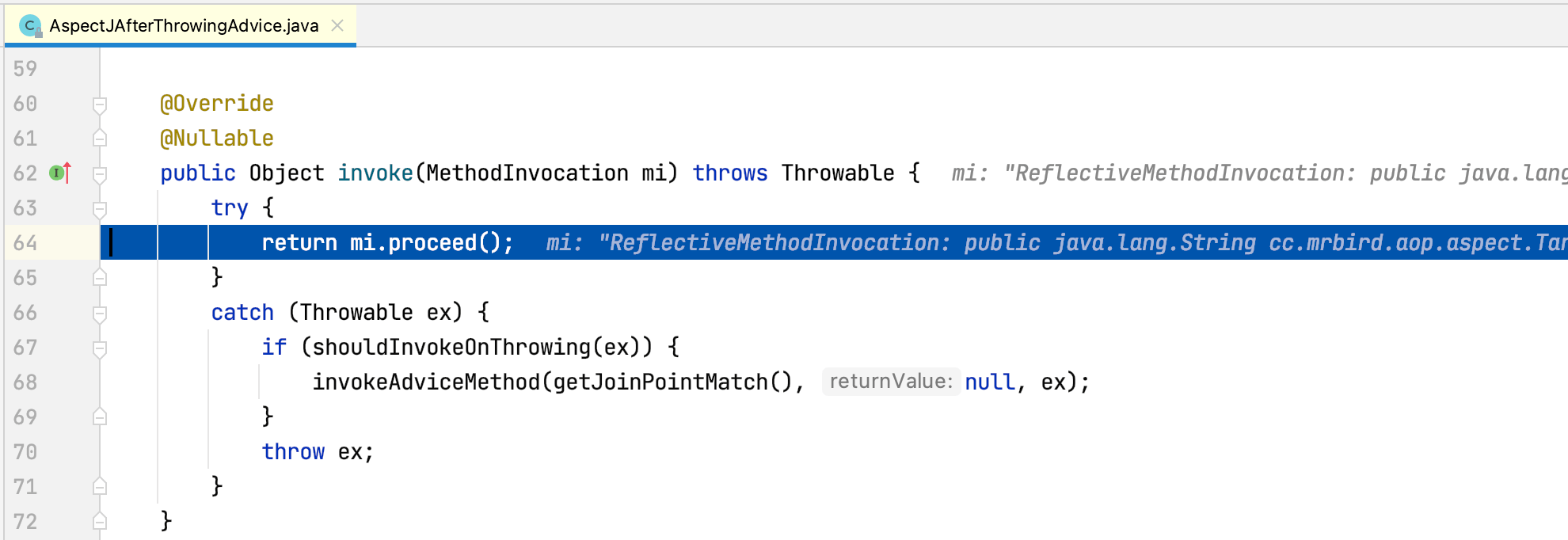
可以看到AspectJAfterThrowingAdvice的invoke方法内通过mi.proceed再次调用ReflectiveMethodInvocation的poceed方法,Step Into进入该方法:

此时程序第六次执行ReflectiveMethodInvocation的poceed方法,currentInterceptorIndex值为4,而拦截器链的长度为5,4==5-1成立,所以执行invokeJoinpoint()方法,该方法内部通过反射调用了目标方法(这里为TargetClass的test方法),执行后,控制台打印内容如下:
1 | onBefore:test方法开始执行,参数:[hello] |
随着invokeJoinpoint()方法执行结束返回出栈,程序回到AspectJAfterThrowingAdvice的invoke方法:
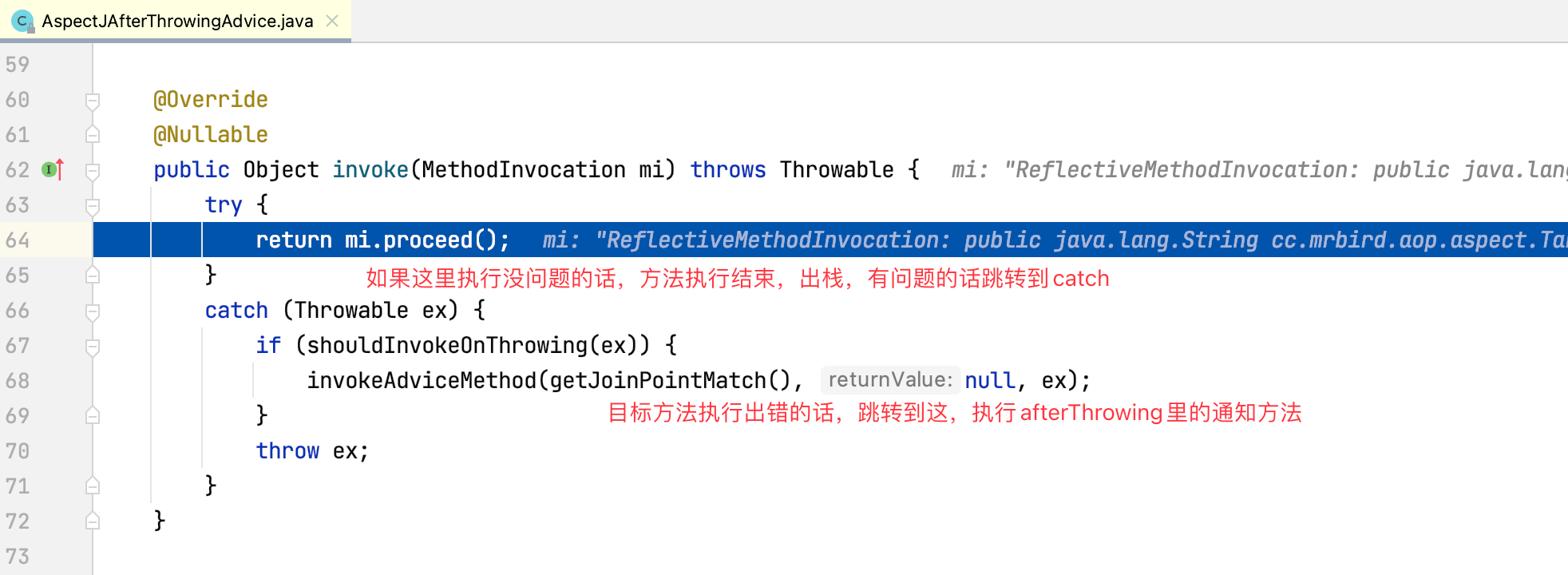
就这个例子来说,目标方法test并没有抛出异常,所以AspectJAfterThrowingAdvice的invoke方法执行结束出栈,程序回到AfterReturningAdviceInteceptor的invoke方法:
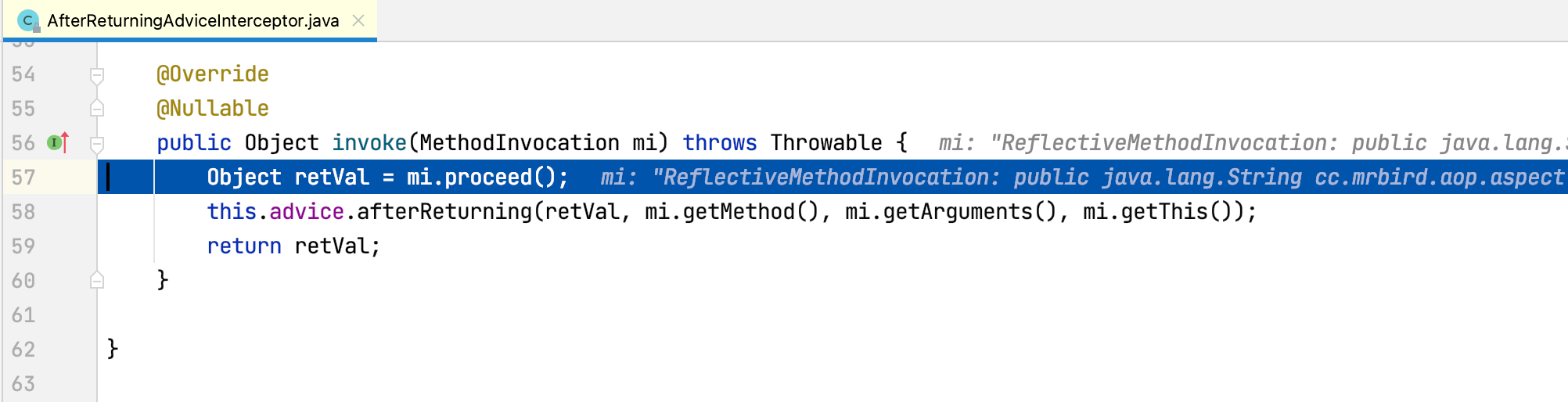
this.advice.afterReturning执行afterReturning通知方法,控制台打印内容如下:
1 | onBefore:test方法开始执行,参数:[hello] |
AfterReturningAdviceInteceptor的invoke方法执行结束出栈,程序回到AspectJAfterAdvice的invoke方法:
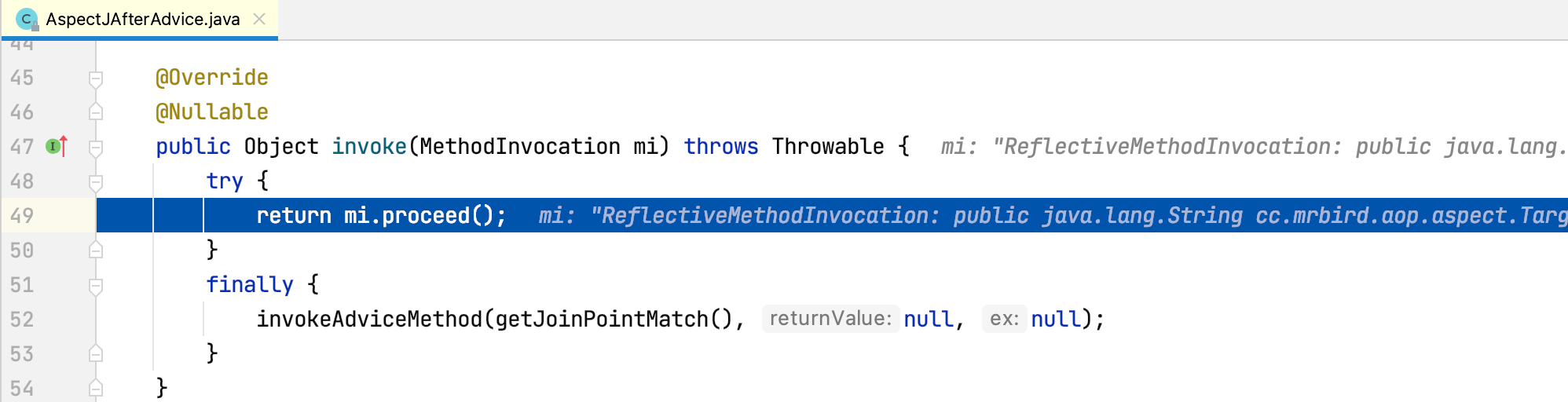
AspectJAfterAdvice的invoke方法最终执行finally after逻辑,控制台打印内容如下:
1 | onBefore:test方法开始执行,参数:[hello] |
AspectJAfterAdvice的invoke方法执行结束出栈,程序回到MethodBeforeAdviceInterceptor的invoke方法:
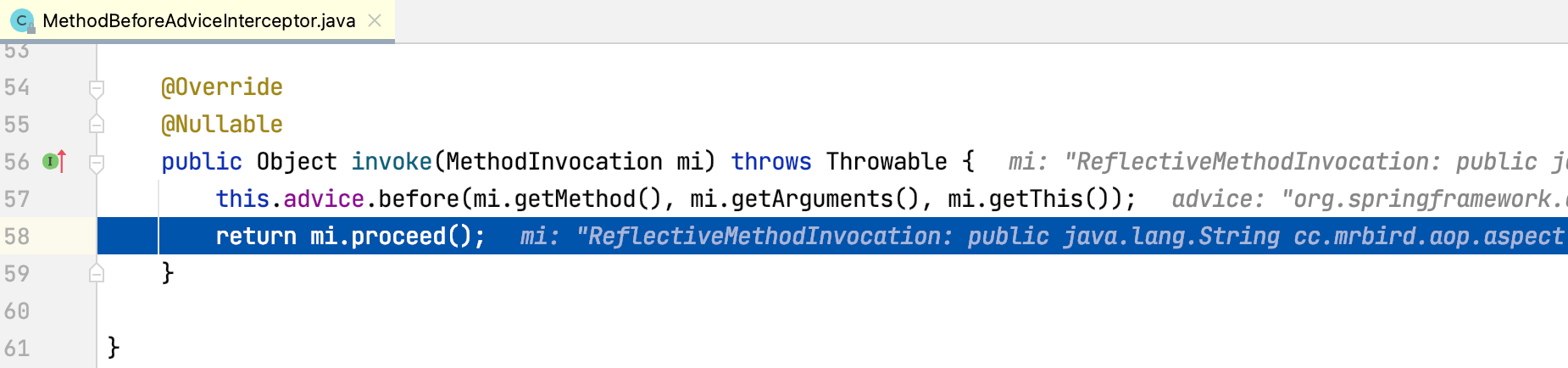
MethodBeforeAdviceInterceptor的invoke方法正常执行结束,出栈,程序回到ExposeInvocationInterceptor的invoke方法:
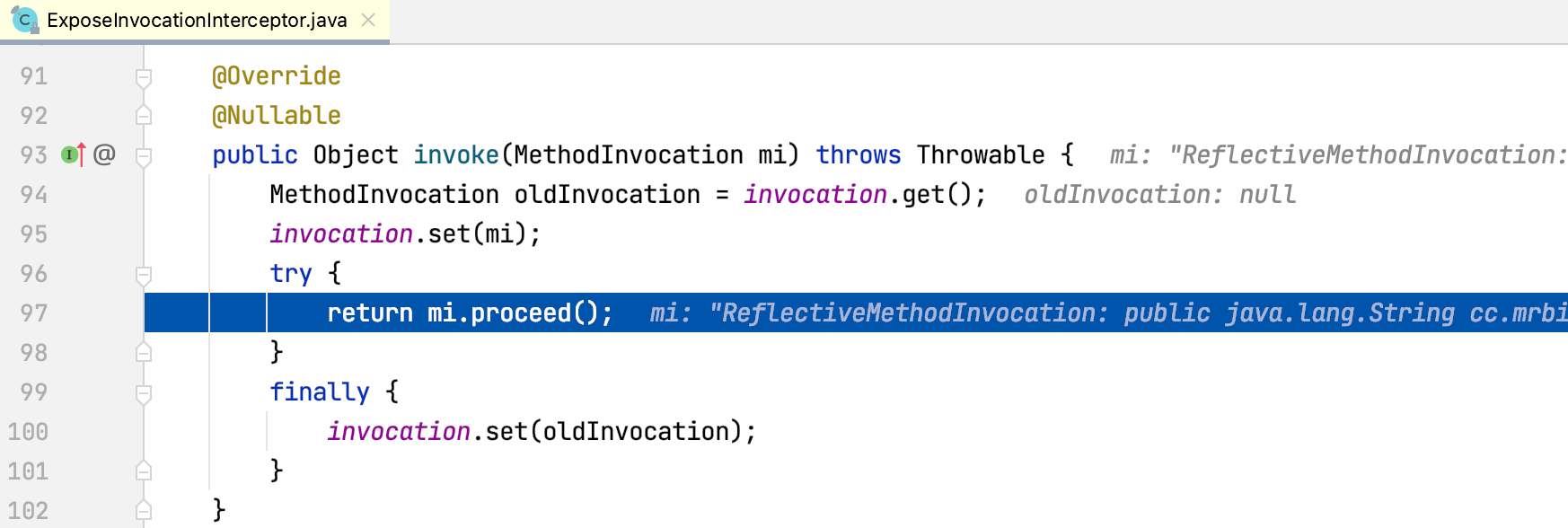
ExposeInvocationInterceptor的invoke方法执行结束出栈,程序回到CglibAopProxy的intercept方法:

CglibAopProxy的intercept方法执行结束出栈后,整个AOP的拦截器链调用也随之结束了:

我们已经成功在目标方法的各个执行时期织入了通知方法。上述过程伴随着不断的入栈出栈操作,不懂您看懂没🤨。
下面用一张图总结拦截器链调用过程:
]]>尚硅谷AOP源码解析学习笔记
本节主要记录BeanFactoryPostProcessor和BeanDefinitionRegistryPostProcessor的方法执行时机以及简单原理分析。
查看BeanFactoryPostProcessor源码:

根据注释我们了解到postProcessBeanFactory方法的执行时机为:BeanFactory标准初始化之后,所有的Bean定义已经被加载,但Bean的实例还没被创建(不包括BeanFactoryPostProcessor类型)。该方法通常用于修改bean的定义,Bean的属性值等,甚至可以在此快速初始化Bean。
下面测试一波。
新建SpringBoot项目,Boot版本2.4.0,依赖如下:
1 | <dependency> |
然后新建MyBeanFactoryPostProcessor,实现BeanFactoryPostProcessor接口:
1 |
|
在postProcessBeanFactory方法内,我们打印了当前已加载Bean定义的个数,并且在MyBeanFactoryPostProcessor类中,注册了TestBean。MyBeanFactoryPostProcessor和TestBean的构造函数输出的日志用于观察Bean实例化时机。
启动程序,输出如下:

上面的日志证实了方法的执行时机的确是在BeanFactory标准初始化之后,所有的Bean定义已经被加载,但Bean的实例还没被创建(此时TestBean还未被实例化,日志还没有输出”实例化TestBean”,但这不包括BeanFactoryPostProcessor类型Bean,该方法执行之前,日志就已经输出了”实例化MyBeanFactoryPostProcessor Bean”)。
我们在postProcessBeanFactory方法上打个断点:

以debug方式启动程序:
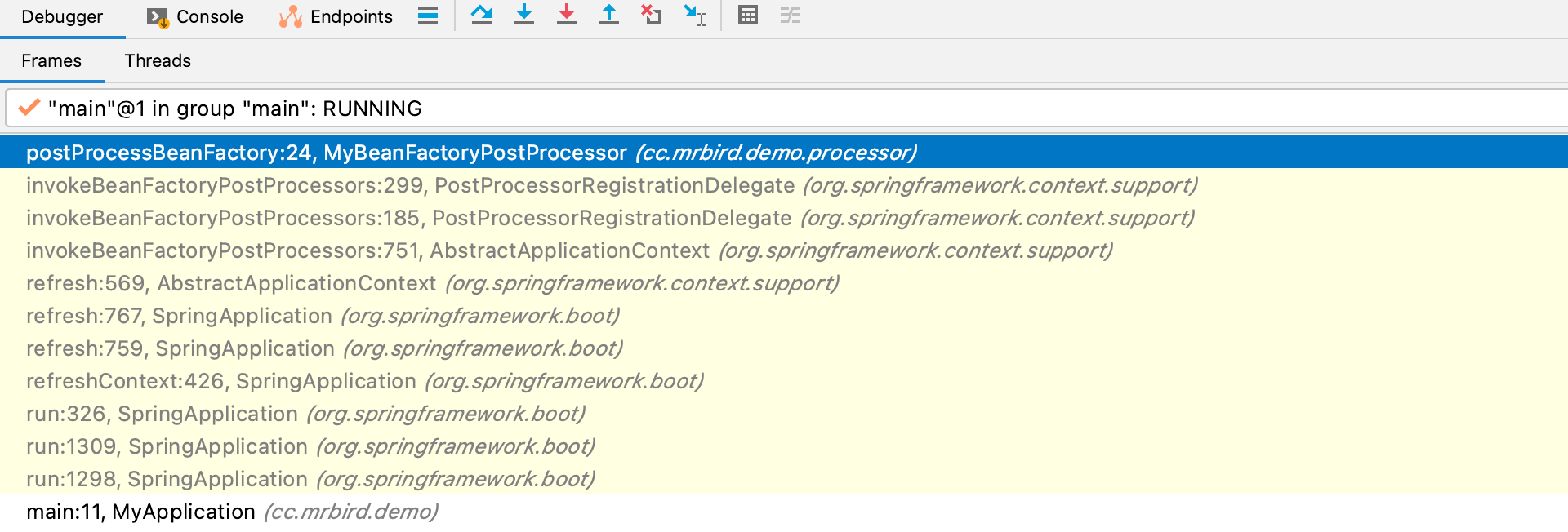
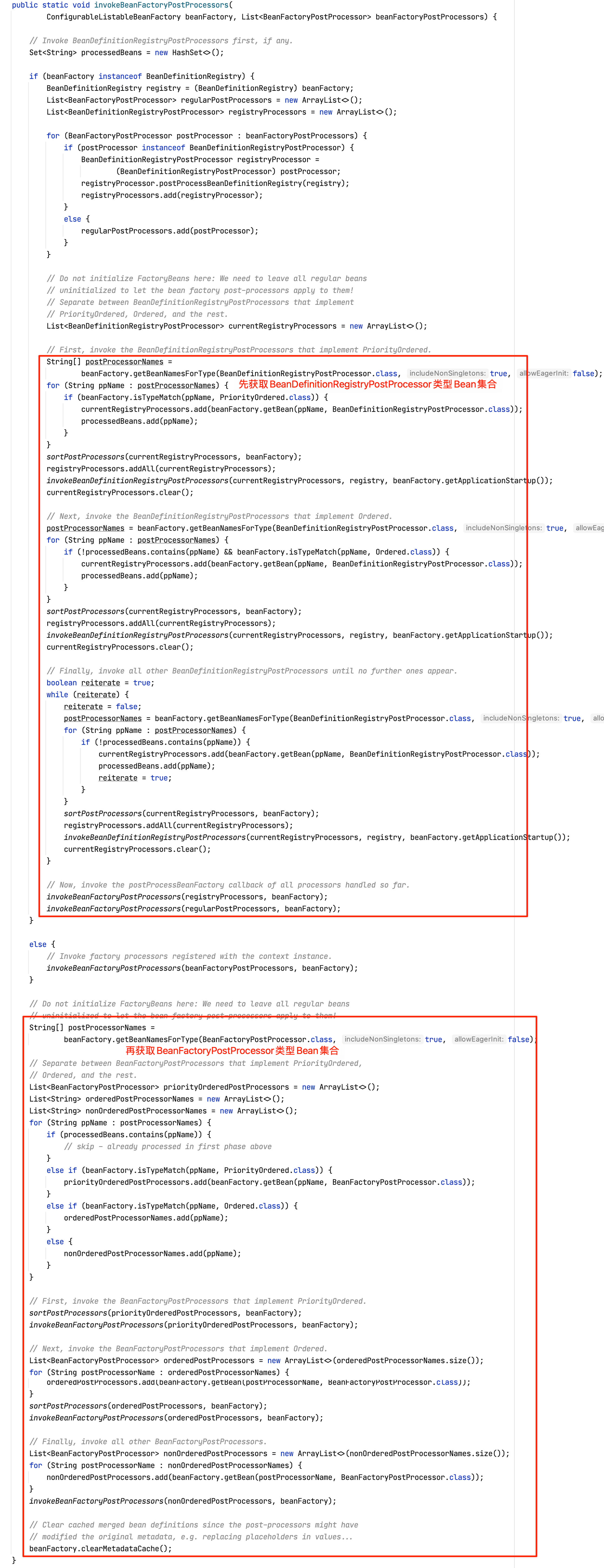
通过追踪方法调用栈,我们可以总结出BeanFactoryPostProcessor的postProcessBeanFactory方法执行时机和原理:
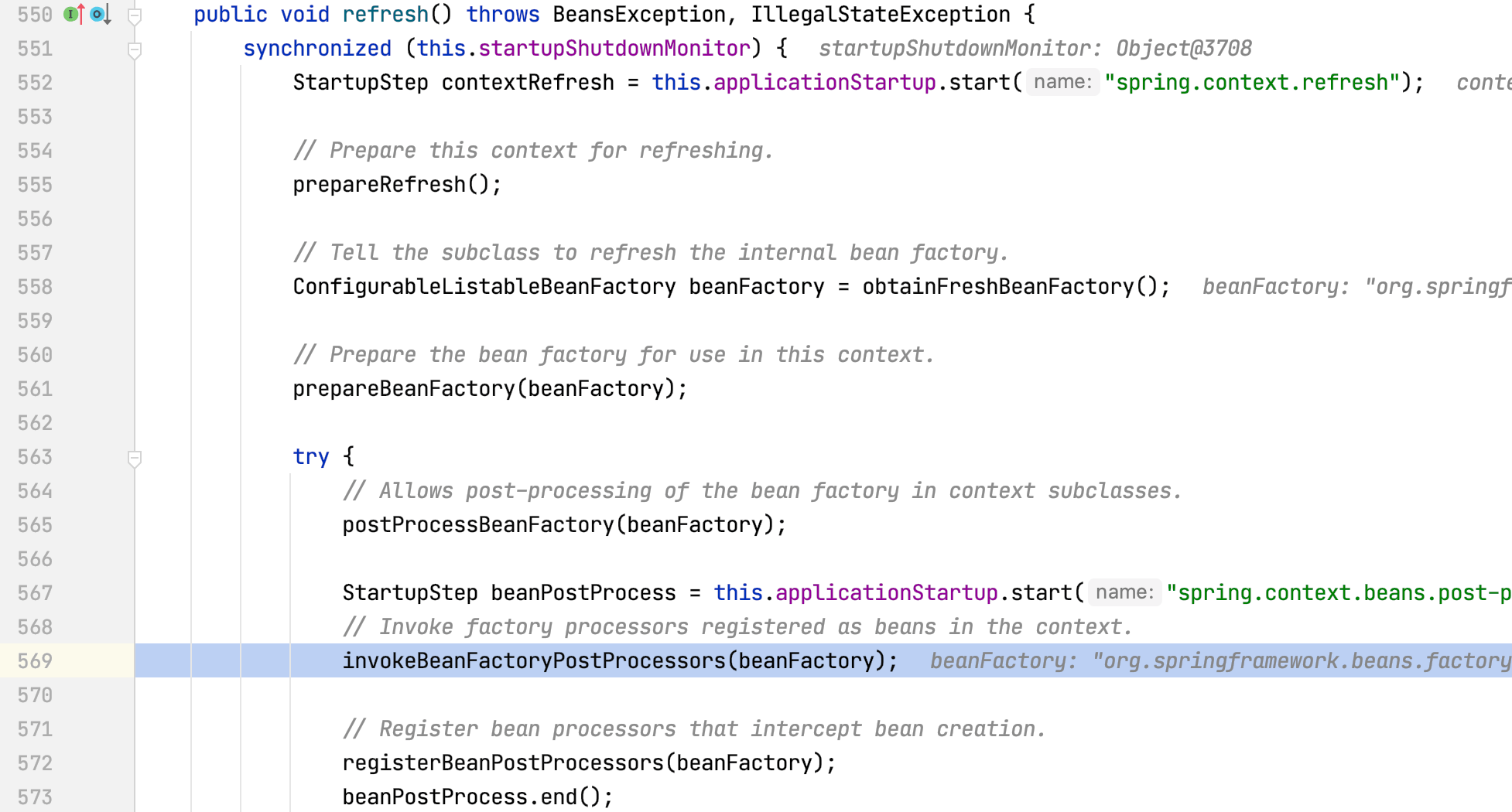
SpringApplication.run(MyApplication.class, args)启动Boot程序:

run方法内部调用refreshContext方法刷新上下文:

refresh方法内部调用invokeBeanFactoryPostProcessors方法:
PostProcessorRegistrationDelegate的invokeBeanFactoryPostProcessors方法内部:


BeanDefinitionRegistryPostProcessor继承自BeanFactoryPostProcessor,新增了一个postProcessBeanDefinitionRegistry方法:
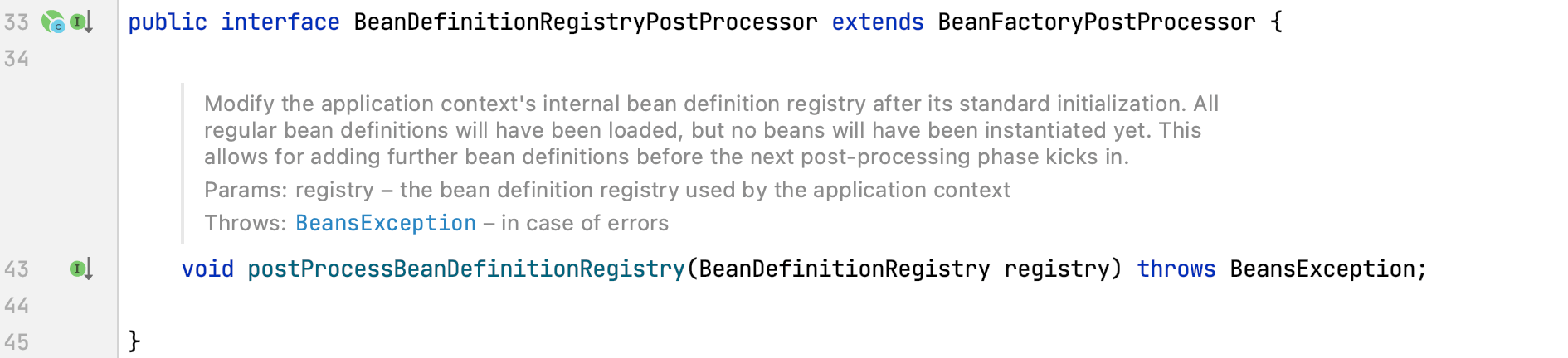
通过注释我们了解到postProcessBeanDefinitionRegistry方法的执行时机为:所有的Bean定义即将被加载,但Bean的实例还没被创建时。也就是说,BeanDefinitionRegistryPostProcessor的postProcessBeanDefinitionRegistry方法执行时机先于BeanFactoryPostProcessor的postProcessBeanFactory方法。这个方法通常用于给IOC容器添加额外的组件。
举个例子测试一波。
新建BeanDefinitionRegistryPostProcessor的实现类MyBeanDefinitionRegistryPostProcessor:
1 |
|
启动程序,输出如下:

可以看到,BeanDefinitionRegistryPostProcessor的postProcessBeanDefinitionRegistry方法执行时机的确先于BeanFactoryPostProcessor的postProcessBeanFactory方法。
通过查看PostProcessorRegistrationDelegate的invokeBeanFactoryPostProcessors方法源码也可以证实这一点:
在深入学习Spring Bean生命周期一节中,我们学习了Bean后置处理器BeanPostProcessor,用于在Bean初始化前后插入我们自己的逻辑(Bean增强,Bean代理等)。今天偶然接触到BeanPostProcessor的子类InstantiationAwareBeanPostProcessor,用于Bean实例化前后处理。本节记录两者的区别以及简单原理分析。
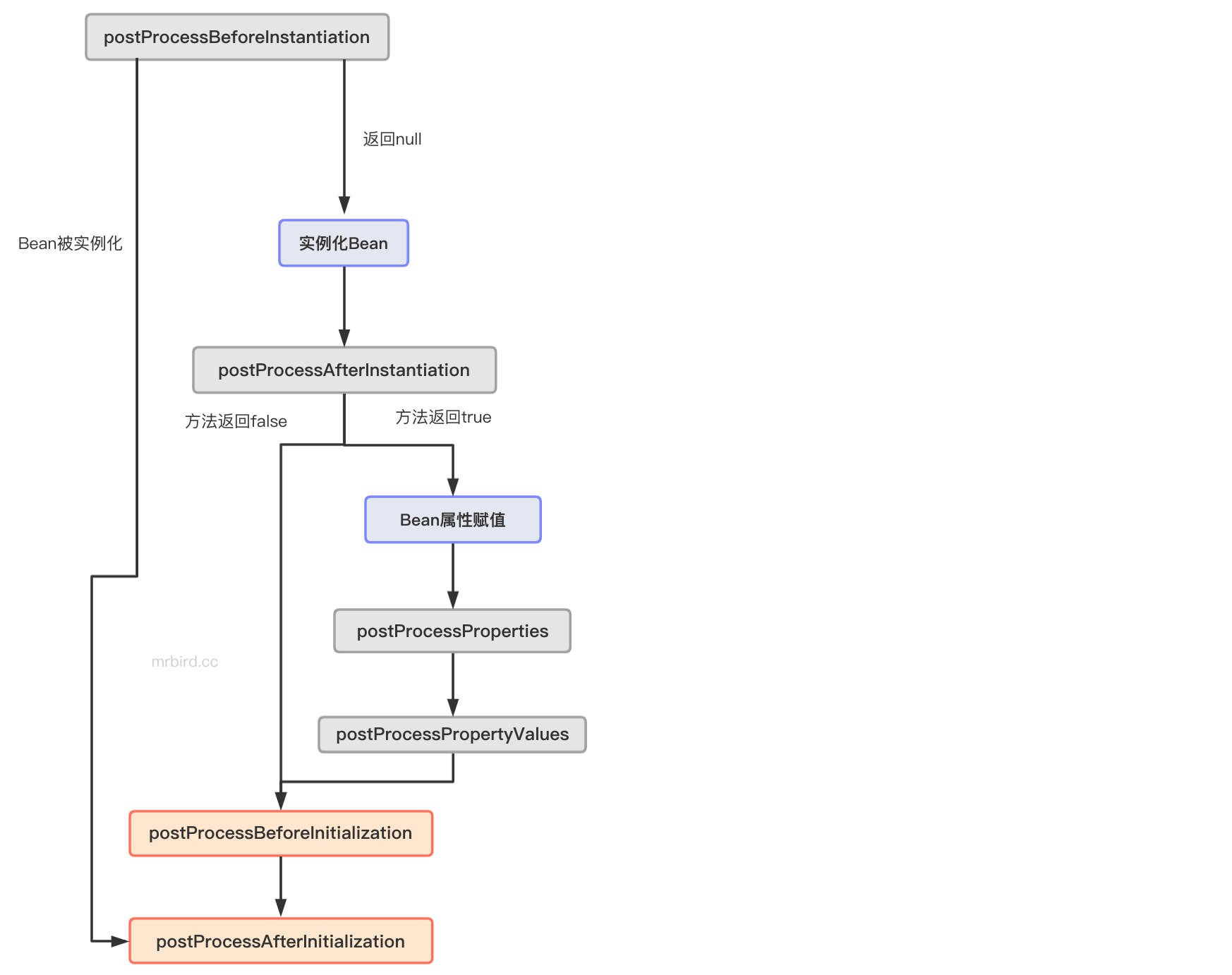
Initialization为初始化的意思,Instantiation为实例化的意思。在Spring Bean生命周期中,实例化指的是创建Bean的过程,初始化指的是Bean创建后,对其属性进行赋值(populate bean)、后置处理等操作的过程,所以Instantiation执行时机先于Initialization。
先来看看BeanPostProcessor的类结构:

InstantiationAwareBeanPostProcessor为BeanPostProcessor的子类,新增了三个额外的方法:


BeanPostProcessor
postProcessBeforeInitialization(Object bean, String beanName):bean:Bean实例;beanName:Bean名称。方法将在Bean实例的afterPropertiesSet方法或者自定义的init方法被调用前调用,此时Bean属性已经被赋值。方法返回原始Bean实例或者包装后的Bean实例,如果返回null,则后续的后置处理方法不再被调用。postProcessAfterInitialization(Object bean, String beanName):bean:Bean实例;beanName:Bean名称。方法将在Bean实例的afterPropertiesSet方法或者自定义的init方法被调用后调用,此时Bean属性已经被赋值。方法返回原始Bean实例或者包装后的Bean实例,如果返回null,则后续的后置处理方法不再被调用。InstantiationAwareBeanPostProcessor
postProcessBeforeInstantiation(Class<?> beanClass, String beanName):beanClass:待实例化的Bean类型;beanName:待实例化的Bean名称。方法作用为:在Bean实例化前调用该方法,返回值可以为代理后的Bean,以此代替Bean默认的实例化过程。返回值不为null时,后续只会调用BeanPostProcessor的 postProcessAfterInitialization方法,而不会调用别的后续后置处理方法(如postProcessAfterInitialization、postProcessBeforeInstantiation等方法);返回值也可以为null,这时候Bean将按默认方式初始化。postProcessAfterInstantiation(Object bean, String beanName):bean:实例化后的Bean,此时属性还没有被赋值;beanName:Bean名称。方法作用为:当Bean通过构造器或者工厂方法被实例化后,当属性还未被赋值前,该方法会被调用,一般用于自定义属性赋值。方法返回值为布尔类型,返回true时,表示Bean属性需要被赋值;返回false表示跳过Bean属性赋值,并且InstantiationAwareBeanPostProcessor的postProcessProperties方法不会被调用。为了验证实例化和初始化的先后顺序,我们新建一个SpringBoot项目,版本2.4.0,依赖如下所示:
1 | <dependencies> |
Spring入口类名称为DemoApplication。新建MyBeanPostProcessor实现BeanPostProcessor接口:
1 |
|
因为对所有的Bean生效,所以为了方便观察输出,这里仅当Bean名称为demoApplication时才打印输出。
接着新建MyBeanInstantiationPostProcessor实现InstantiationAwareBeanPostProcessor接口:
1 |
|
启动程序,输出如下所示:
1 | post process before demoApplication instantiation |
如果将MyBeanInstantiationPostProcessor的postProcessAfterInstantiation方法返回值改为false,程序输出如下:
1 | post process before demoApplication instantiation |
postProcessAfterInitialization和InstantiationAwareBeanPostProcessor的方法都和Bean生命周期有关,要分析它们的实现原理自然要从Bean的创建过程入手。Bean创建的入口为AbstractAutowireCapableBeanFactory的createBean方法,查看其源码:
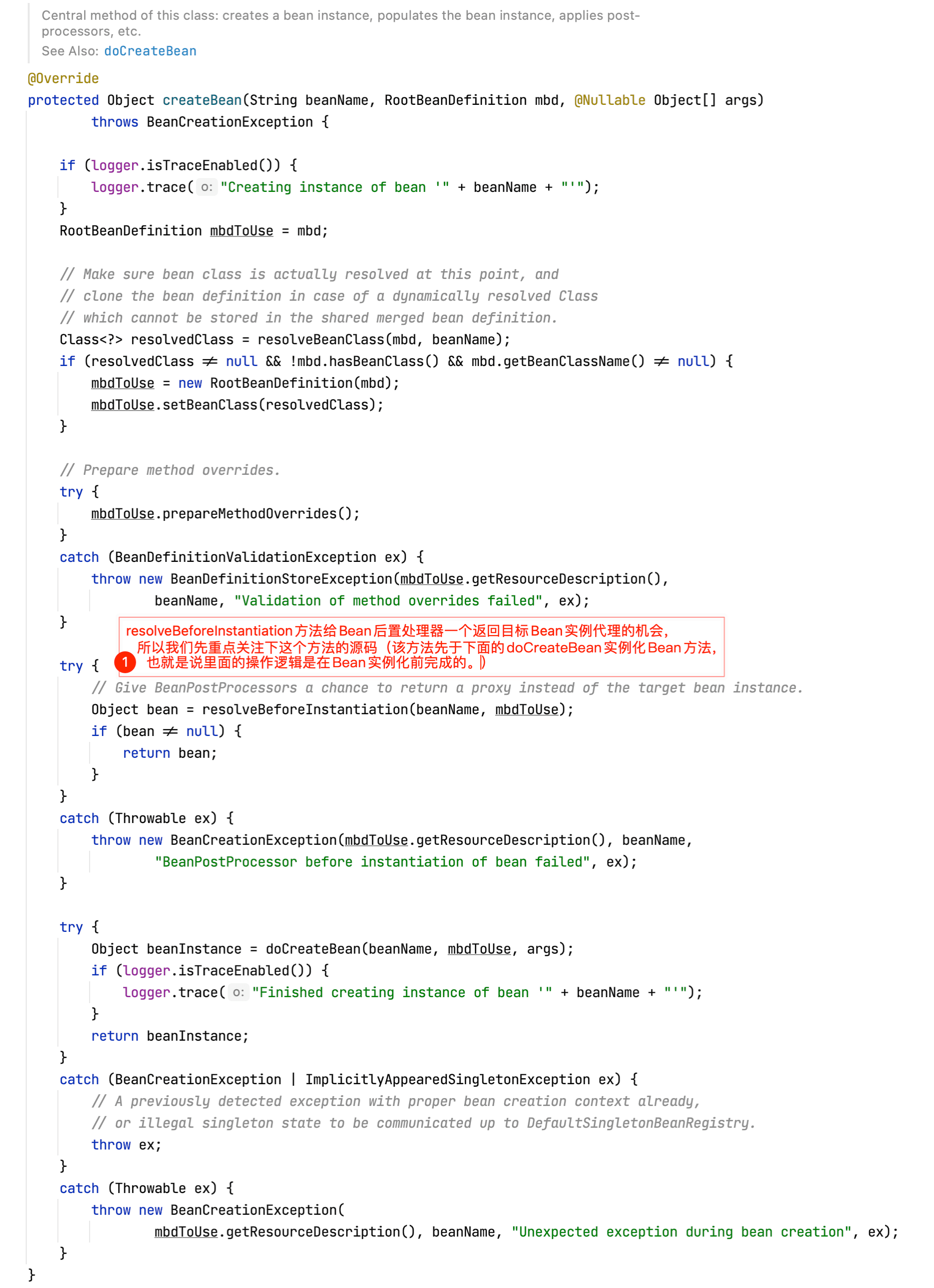
resolveBeforeInstantiation方法源码如下所示:

上面方法返回的bean如果为空的话,AbstractAutowireCapableBeanFactory的createBean方法将继续往下执行doCreateBean方法:
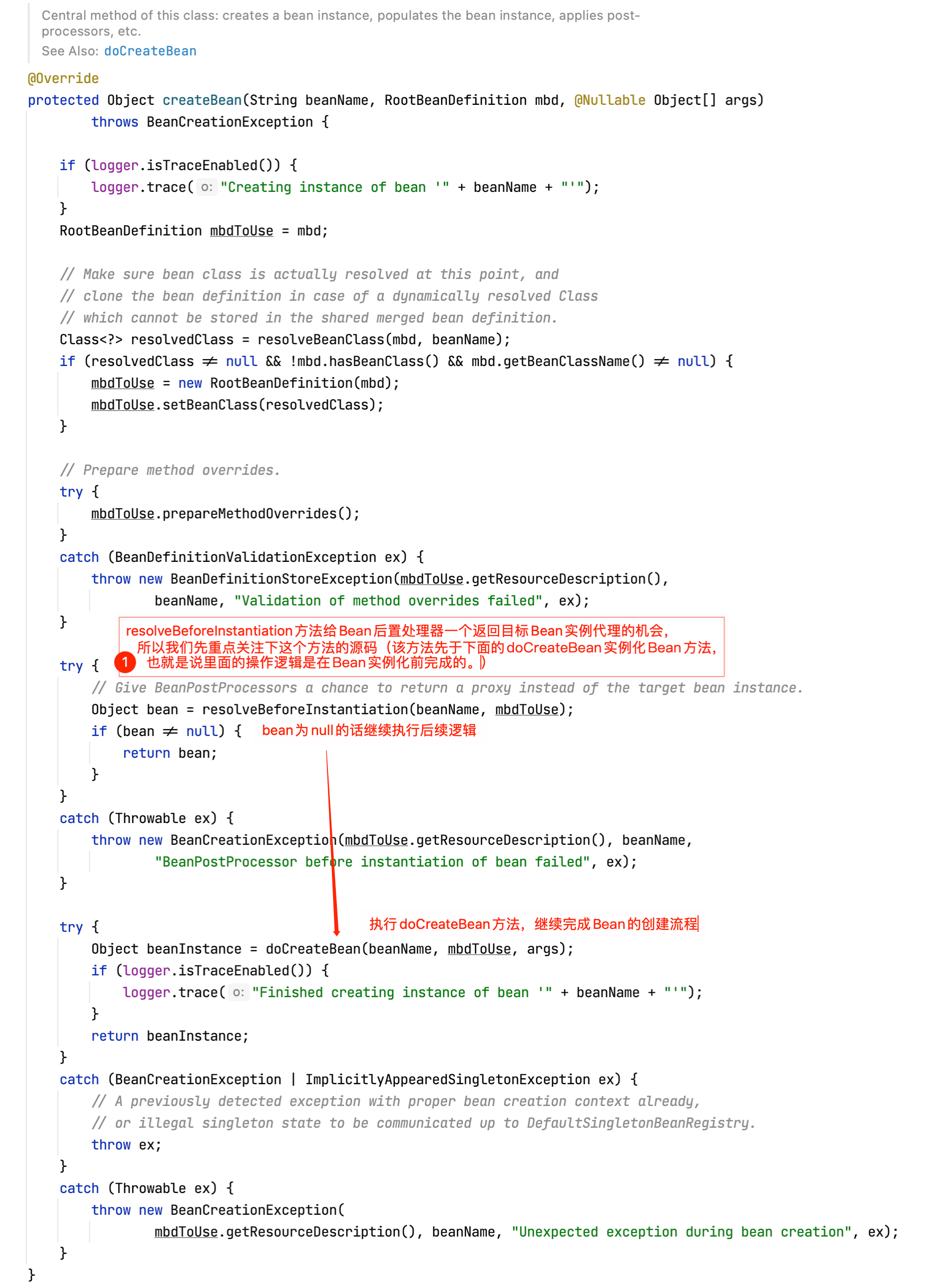
查看doCreateBean方法源码:

其他部分和本节讨论内容关系不大(Bean生命周期其他部分),重点关注populateBean和initializeBean方法。查看populateBean方法源码:

接着查看initializeBean方法源码:

至此我们通过查看Bean生命周期相关源码弄清楚了BeanPostProcessor和InstantiationAwareBeanPostProcessor相关方法的执行时机以及原理。
上面源码的追踪其实不仅涉及到了BeanPostProcessor和InstantiationAwareBeanPostProcessor相关方法的执行时机以及原理,更是整个Bean生命周期创建过程,结合Spring-Bean生命周期这篇文章的流程再走一遍源码,你会对Bean的生命周期有更深的理解。
下面通过一张流程图总结本文:
我们项目大多数都是基于Spring架构,Spring自身包含了许多实用的工具类,学习这些工具类的使用不仅能让我们达到事半功倍的效果,而且还能减少不必要的额外的工具类的引入。查看这些工具类的源码时发现它们都是abstract类型的,这是因为工具类的方法一般都是static静态方法,静态方法和类绑定,类加载后就能使用了,无需实例化(刚好abstract类不能直接实例化,并且可以定义非抽象方法),所以工具类定义为abstract类型再合适不过。
1 | private static void print(Object value) { |
org.springframework.util.classUtils包含一些和java.lang.Class相关的实用方法。
ClassLoader getDefaultClassLoader()获取当前线程上下文的类加载器:
1 | print(ClassUtils.getDefaultClassLoader()); |
1 | sun.misc.Launcher$AppClassLoader@18b4aac2 |
ClassLoader overrideThreadContextClassLoader(@Nullable ClassLoader classLoaderToUse)用特定的类加载器覆盖当前线程上下文的类加载器:
1 | print(ClassUtils.getDefaultClassLoader()); |
1 | sun.misc.Launcher$AppClassLoader@18b4aac2 |
forName(String name, @Nullable ClassLoader classLoader)通过类名返回类实例,类似于Class.forName(),但功能更强,可以用于原始类型,内部类等:
1 | ClassLoader classLoader = ClassUtils.getDefaultClassLoader(); |
1 | int |
boolean isPresent(String className, @Nullable ClassLoader classLoader)判断当前classLoader是否包含目标类型(包括它的所有父类和接口):
1 | ClassLoader classLoader = ClassUtils.getDefaultClassLoader(); |
1 | true |
Class<?> resolvePrimitiveClassName(@Nullable String name)通过给定类名获取原始类:
1 | print(ClassUtils.resolvePrimitiveClassName("int")); |
1 | int |
boolean isPrimitiveWrapper(Class<?> clazz)判断给定类是否为包装类,如Boolean, Byte, Character, Short, Integer, Long, Float, Double 或者 Void:
1 | print(ClassUtils.isPrimitiveWrapper(Integer.class)); |
1 | true |
类似的方法还有isPrimitiveOrWrapper判断是否为原始类或者包装类、isPrimitiveWrapperArray判断是否为包装类数组、isPrimitiveArray判断是否为原始类数组。
Class<?> resolvePrimitiveIfNecessary(Class<?> clazz)如果给定类是原始类,则返回对应包装类,否则直接返回给定类:
1 | print(ClassUtils.resolvePrimitiveIfNecessary(int.class)); |
1 | class java.lang.Integer |
boolean isAssignable(Class<?> lhsType, Class<?> rhsType)通过反射检查,是否可以将rhsType赋值给lhsType(注意,包装类型可以赋值给相应的原始类型,自动拆装箱机制):
1 | print(ClassUtils.isAssignable(Integer.class, int.class)); |
1 | true |
boolean isAssignableValue(Class<?> type, @Nullable Object value)判断给定的值是否符合给定的类型:
1 | print(ClassUtils.isAssignableValue(Integer.class, 1)); |
1 | true |
String convertResourcePathToClassName(String resourcePath)将类路径转换为全限定类名:
1 | print(ClassUtils.convertResourcePathToClassName("java/lang/String")); |
1 | java.lang.String |
实际上就是将/替换为.。convertClassNameToResourcePath方法功能相反。
String classNamesToString(Class<?>... classes)直接看演示不解释:
1 | print(ClassUtils.classNamesToString(String.class, Integer.class, BeanPostProcessor.class)); |
1 | [java.lang.String, java.lang.Integer, org.springframework.beans.factory.config.BeanPostProcessor] |
Class<?>[] getAllInterfaces(Object instance)返回给定实例对象所实现接口类型集合:
1 | AutowiredAnnotationBeanPostProcessor processor = new AutowiredAnnotationBeanPostProcessor(); |
1 | interface org.springframework.beans.factory.config.SmartInstantiationAwareBeanPostProcessor |
类似的方法还有getAllInterfacesForClass、getAllInterfacesAsSet、getAllInterfacesForClassAsSet
Class<?> determineCommonAncestor(@Nullable Class<?> clazz1, @Nullable Class<?> clazz2)寻找给定类型的共同祖先(所谓共同祖先指的是给定类型调用class.getSuperclass获得的共同类型,如果给定类型是Object.class,接口,原始类型或者Void,直接返回null):
1 | // 它两都是接口 |
1 | null |
boolean isInnerClass(Class<?> clazz)判断给定类型是否为内部类(非静态):
1 | class A { |
1 | static class A { |
1 | static class A { |
boolean isCglibProxy(Object object)是否为Cglib代理对象:
1 |
|
1 | true |
配置类不由Cglib代理的话,返回为false:
1 |
|
1 | false |
不过这个方法废弃了,建议使用org.springframework.aop.support.AopUtils.isCglibProxy(Object)方法。
Class<?> getUserClass(Object instance)返回给定实例对应的类型,如果实例是Cglib代理后的对象,则返回代理的目标对象类型:
1 | print(ClassUtils.getUserClass("Hello")); // class java.lang.String |
Cglib代理例子:
1 |
|
1 | class cc.mrbird.aop.AopApplication$MyConfigure$$EnhancerBySpringCGLIB$$e51ce45 |
boolean matchesTypeName(Class<?> clazz, @Nullable String typeName)判断给定class和类型名称是否匹配:
1 | print(ClassUtils.matchesTypeName(String.class, "java.lang.String")); // true |
String getShortName(Class<?> clazz)返回类名:
1 | print(ClassUtils.getShortName(String.class)); // String |
String getShortNameAsProperty(Class<?> clazz)返回首字母小写的类名,如果是内部类的话,则去掉外部类名:
1 | print(ClassUtils.getShortNameAsProperty(String.class)); // string |
1 | class A { |
String getClassFileName(Class<?> clazz)返回类名+.class:
1 | print(ClassUtils.getShortNameAsProperty(String.class)); // String.class |
String getPackageName(Class<?> clazz)返回包名:
1 | print(ClassUtils.getShortNameAsProperty(String.class)); // java.lang |
String getQualifiedName(Class<?> clazz)返回全限定类名,如果是数组类型则末尾加[]:
1 | print(ClassUtils.getQualifiedName(String.class)); |
1 | java.lang.String |
String getQualifiedMethodName(Method method)获取方法的全限定名:
1 | print(ClassUtils.getQualifiedMethodName( |
1 | org.springframework.util.ClassUtils.getQualifiedMethodName |
boolean hasConstructor(Class<?> clazz, Class<?>... paramTypes)判断给定类型是否有给定类型参数构造器:
1 | print(ClassUtils.hasConstructor(String.class, String.class)); |
1 | true |
<T> Constructor<T> getConstructorIfAvailable(Class<T> clazz, Class<?>... paramTypes)返回给定类型的给定参数类型构造器,没有的话返回null:
1 | Constructor<String> constructorIfAvailable = ClassUtils.getConstructorIfAvailable(String.class, String.class); |
1 | true |
boolean hasMethod(Class<?> clazz, Method method)判断给定类型是否有指定的方法:
1 | Method hasMethod = ClassUtils.class.getDeclaredMethod("hasMethod", Class.class, Method.class); |
重载方法boolean hasMethod(Class<?> clazz, String methodName, Class<?>... paramTypes)。
Method getMethod(Class<?> clazz, String methodName, @Nullable Class<?>... paramTypes)从指定类型中找指定方法,没找到抛IllegalStateException异常:
1 | ClassUtils.getMethod(ClassUtils.class,"hello", String.class); |
1 | java.lang.IllegalStateException: Expected method not found: java.lang.NoSuchMethodException: org.springframework.util.ClassUtils.hello(java.lang.String) |
如果希望没找到返回null,而非抛异常,可以用getMethodIfAvailable方法。
int getMethodCountForName(Class<?> clazz, String methodName)从指定类型中通过方法名称查找该方法个数(重写、重载、非public的都算):
1 | print(ClassUtils.getMethodCountForName(ClassUtils.class,"hasMethod")); // 2 |
类似的方法还有hasAtLeastOneMethodWithName,至少得有一个。
Method getStaticMethod(Class<?> clazz, String methodName, Class<?>... args)获取给定类型的静态方法,如果该方法不是静态的或者没有这个方法,则返回null:
1 | Method method = ClassUtils.getStaticMethod(ClassUtils.class, "getDefaultClassLoader"); |
1 | true |
文件系统实用工具类
boolean deleteRecursively(@Nullable File root)递归删除指定文件或目录,删除成功返回true,失败返回false,不会抛出异常。
新建一个多层级目录:

实用File的delete目录尝试删除a目录:
1 | File file = new File("a"); |
因为a目录包含子目录(文件),所以应该使用递归删除:
1 | File file = new File("a"); |
重载方法boolean deleteRecursively(@Nullable Path root)和该方法功能相似,但该方法可能会抛出IO异常。
void copyRecursively(File src, File dest)递归复制src文件到dest(目标路径不存在则自动创建):
新建一个多层级目录:
1 | File src = new File("a"); |

重载方法void copyRecursively(Path src, Path dest)。
包含一些文件流的实用方法默认的缓冲区大小为4096bytes。
]]>未完待续,慢慢记录😴
数字签名算法可以看成是带秘钥的消息摘要算法,用于验证数据完整性、认证数据来源,并起到抗否认的作用。遵循私钥加签,公钥验签的规则,数字签名算法是非对称加密算法和消息摘要算法的结合体。数字签名算法主要包括RSA和DSA。这节记录下这两种算法在JDK8下的实现。
数字签名加签验签流程分为以下几步:
RSA数字签名算法主要分为MD系列和SHA系列两大类。MD系列主要包括MD2withRSA和MD5withRSA共2种数字签名算法;SHA系列主要包括SHA1withRSA、SHA224withRSA、SHA256withRSA、SHA384withRSA和SHA512withRSA共5种数字签名算法。
代码示例:
1 | import org.junit.Test; |
秘钥对生成过程和上篇RSA介绍的无异,主要关注加签和验签操作即可,程序输出如下:
1 | RSA公钥: MFwwDQYJKoZIhvcNAQEBBQADSwAwSAJBAKTTlw+zyhGzmTmhT5w9vEP1ejOcVfM2rHbz8jUae7InAh42R9ZaYUk1c3q0uqmTv8xKOnszU/vrdV52zoFM+OMCAwEAAQ== |
需要注意的是不同签名算法需要的秘钥长度最小值不同,大伙可以自己试试。
DSA算法与RSA算法都是数字证书中不可或缺的两种算法。两者不同的是,DSA算法仅包含数字签名算法,使用DSA算法的数字证书无法进行加密通信,而RSA算法既包含加密/解密算法,同时兼有数字签名算法。
JDK8支持SHA1withDSA、SHA224withDSA、SHA256withDSA、SHA384withDSA和SHA512withDSA这五种DSA数字签名算法。
代码示例(只需将上面的例子算法替换下就好,并且注意秘钥的长度范围):
1 | import org.junit.Test; |
运行结果如下:
1 | DSA公钥: MIIBtzCCASwGByqGSM44BAEwggEfAoGBAP1/U4EddRIpUt9KnC7s5Of2EbdSPO9EAMMeP4C2USZpRV1AIlH7WT2NWPq/xfW6MPbLm1Vs14E7gB00b/JmYLdrmVClpJ+f6AR7ECLCT7up1/63xhv4O1fnxqimFQ8E+4P208UewwI1VBNaFpEy9nXzrith1yrv8iIDGZ3RSAHHAhUAl2BQjxUjC8yykrmCouuEC/BYHPUCgYEA9+GghdabPd7LvKtcNrhXuXmUr7v6OuqC+VdMCz0HgmdRWVeOutRZT+ZxBxCBgLRJFnEj6EwoFhO3zwkyjMim4TwWeotUfI0o4KOuHiuzpnWRbqN/C/ohNWLx+2J6ASQ7zKTxvqhRkImog9/hWuWfBpKLZl6Ae1UlZAFMO/7PSSoDgYQAAoGAcW0aiebAWi5M18Lu6QS/1OoHbtw2I7kyivwExbNAZpWR9I9sNIwE1T0a491t1oqRV1cdBHyd9jiJqFwfLG6k5QidasXTgGYSsSZqFBebP5nrF5q3RtkosoHeHVKDnShQf5b36NK53CpCRfLayk2e5inu7CCCo+a58piAMiF3c+k= |
非对称加密和对称加密算法相比,多了一把秘钥,为双秘钥模式,一个公开称为公钥,一个保密称为私钥。遵循公钥加密私钥解密,或者私钥加密公钥解密。非对称加密算法源于DH算法,后又有基于椭圆曲线加密算法的密钥交换算法ECDH,不过目前最为流行的非对称加密算法是RSA,本文简单记录下RSA的使用。
RSA算法是最为典型的非对称加密算法,该算法由美国麻省理工学院(MIT)的Ron Rivest、Adi Shamir和Leonard Adleman三位学者提出,并以这三位学者的姓氏开头字母命名,称为RSA算法。
RSA算法的数据交换过程分为如下几步:
JDK8支持RSA算法:
| 算法 | 秘钥长度 | 加密模式 | 填充模式 |
|---|---|---|---|
| RSA | 512~16384位,64倍数 | ECB | NoPadding PKCS1Padding OAEPWithMD5AndMGF1Padding OAEPWithSHA1AndMGF1Padding OAEPWithSHA-1AndMGF1Padding OAEPWithSHA-224AndMGF1Padding OAEPWithSHA-256AndMGF1Padding OAEPWithSHA-384AndMGF1Padding OAEPWithSHA-512AndMGF1Padding OAEPWithSHA-512/224AndMGF1Padding OAEPWithSHA-512/2256ndMGF1Padding |
代码例子:
1 | import org.junit.Test; |
程序输出如下:
1 | RSA公钥: MFwwDQYJKoZIhvcNAQEBBQADSwAwSAJBAKBvz9cma+hXNiv2yXg6e1PyZhHVZm3bJXDvTJP2LyXo4vs9grH36Q9kNgr6quHtuU6fEoUxUu2zbEB8dkEWB9UCAwEAAQ== |
可以看到,公钥加密私钥解密和私钥加密公钥解密的模式都可行。
假如现在有RSA公钥:
1 | MFwwDQYJKoZIhvcNAQEBBQADSwAwSAJBAKBvz9cma+hXNiv2yXg6e1PyZhHVZm3bJXDvTJP2LyXo4vs9grH36Q9kNgr6quHtuU6fEoUxUu2zbEB8dkEWB9UCAwEAAQ== |
RSA私钥:
1 | MIIBVAIBADANBgkqhkiG9w0BAQEFAASCAT4wggE6AgEAAkEAoG/P1yZr6Fc2K/bJeDp7U/JmEdVmbdslcO9Mk/YvJeji+z2CsffpD2Q2Cvqq4e25Tp8ShTFS7bNsQHx2QRYH1QIDAQABAkEAjemZXORdesz52/WVzEVepai6ZHfw/Kdl/PmPMSoIFmz7mk55rprl2Akn2V0odSiHSnMWvDmOUIAvHaHF4Re4wQIhAN5GxVeF7ndyoWasxqIOVb6baNkUrapBM0nacPS4WA8JAiEAuMcvNM2Z1rW74JagoGlSIfRkNUqa+3LTCN/fK7VR2W0CICs/+gYduVjkpSMlW0ENKQH9m1kh/Oiz5xbnujLj676BAiBVGif7wdXgtcLaJYXFW7ygNtcQVFQdCz13EOTQVKpl4QIgY2YyH3vUYI2J68qCGtYjj5iNHUEwwze+Za1R7y0V43k= |
需要将它们还原为PublicKey和PrivateKey对象,可以参考如下代码:
1 | import org.junit.Test; |
程序输出如下:
1 | RSA公钥加密数据: PdSr+WRUWIxbA7stmZ03GCwDBnE3CyFL43bTskJmBilY+9lL63Jt0KxN0S2A4ombxvngbiB8PVZiqj1oSkgWpA== |
RSA加解密中必须考虑到的密钥长度、明文长度和密文长度问题。明文长度需要小于密钥长度,而密文长度则等于密钥长度。因此当加密内容长度大于密钥长度时,有效的RSA加解密就需要对内容进行分段。
这是因为,RSA算法本身要求加密内容也就是明文长度m必须满足0<m<密钥长度n。如果小于这个长度就需要进行padding,因为如果没有padding,就无法确定解密后内容的真实长度,字符串之类的内容问题还不大,以0作为结束符,但对二进制数据就很难,因为不确定后面的0是内容还是内容结束符。而只要用到padding,那么就要占用实际的明文长度,于是实际明文长度需要减去padding字节长度。我们一般使用的padding标准有NoPPadding、OAEPPadding、PKCS1Padding等,其中PKCS#1建议的padding就占用了11个字节。
以秘钥长度为1024bits为例:
1 | import org.junit.Test; |
程序会抛出如下异常:
1 | 待加密内容长度: 120 |
对于1024长度的密钥。128字节(1024bits/8)减去PKCS#1建议的padding就占用了11个字节正好是117字节。所以加密的明文长度120字节大于117字节,程序抛出了异常。
要解决这个问题,可以采用分段加密的手段。编写一个分段加解密的工具类:
1 | import javax.crypto.Cipher; |
测试:
1 | import org.junit.Test; |
程序输出如下:
1 | 待加密内容长度: 120 |
公钥是通过A发送给B的,其在传递过程中很有可能被截获,也就是说窃听者很有可能获得公钥。如果窃听者获得了公钥,向A发送数据,A是无法辨别消息的真伪的。因此,虽然可以使用公钥对数据加密,但这种方式还是会有存在一定的安全隐患。如果要建立更安全的加密消息传递模型,就需要AB双方构建两套非对称加密算法密钥,仅遵循“私钥加密,公钥解密”的方式进行加密消息传递;
RSA不适合加密过长的数据,虽然可以通过分段加密手段解决,但过长的数据加解密耗时较长,在响应速度要求较高的情况下慎用。一般推荐使用非对称加密算法传输对称加密秘钥,双方数据加密用对称加密算法加解密。
