Kafka是一个分布式的、可分区的、可复制的消息系统,下面是Kafka的几个基本术语:
Kafka将消息以topic为单位进行归纳;
将向Kafka topic发布消息的程序成为producers;
将预订topics并消费消息的程序成为consumer;
Kafka以集群的方式运行,可以由一个或多个服务组成,每个服务叫做一个broker。
producers通过网络将消息发送到Kafka集群,集群向消费者提供消息,如下图所示:
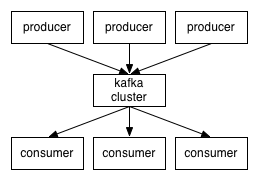
创建一个topic时,可以指定partitions(分区)数目,partitions数越多,其吞吐量也越大,但是需要的资源也越多,同时也会导致更高的不可用性,kafka在接收到producers发送的消息之后,会根据均衡策略将消息存储到不同的partitions中:
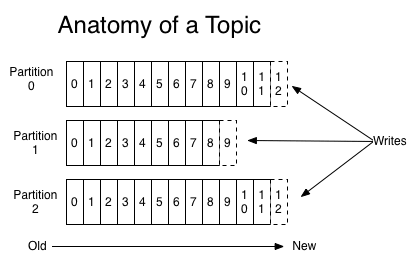
在每个partitions中,消息以顺序存储,最晚接收的的消息会最后被消费。
producers在向kafka集群发送消息的时候,可以通过指定partitions来发送到指定的partitions中。也可以通过指定均衡策略来将消息发送到不同的partitions中。如果不指定,就会采用默认的随机均衡策略,将消息随机的存储到不同的partitions中。
在consumer消费消息时,kafka使用offset来记录当前消费的位置:
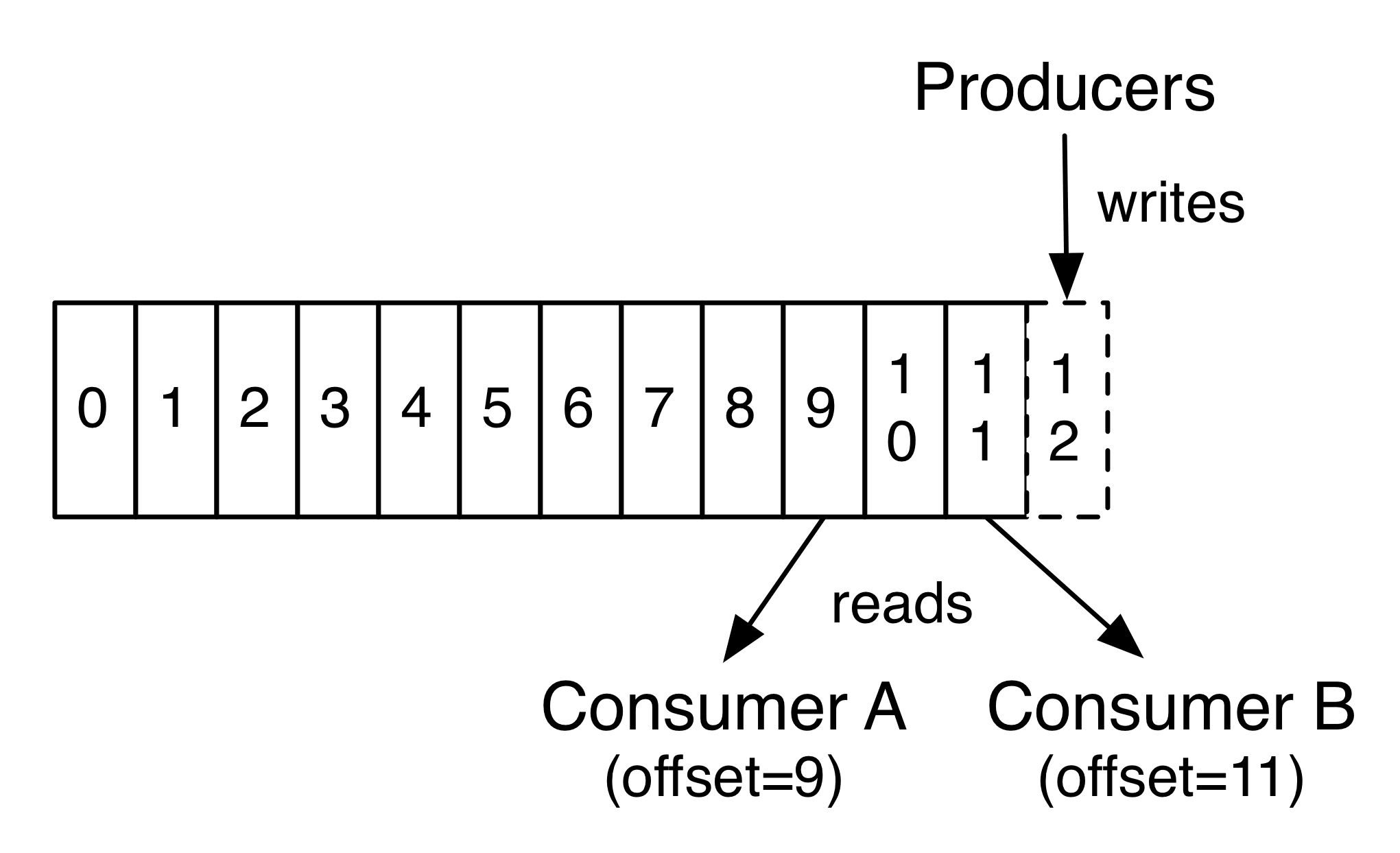
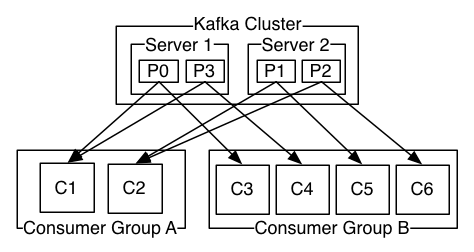
在kafka的设计中,可以有多个不同的group来同时消费同一个topic下的消息,如图,我们有两个不同的group同时消费,他们的的消费的记录位置offset各不项目,不互相干扰。
对于一个group而言,consumer的数量不应该多于partitions的数量,因为在一个group中,每个partitions至多只能绑定到一个consumer上,即一个consumer可以消费多个partitions,一个partitions只能给一个consumer消费。因此,若一个group中的consumer数量大于partitions数量的话,多余的consumer将不会收到任何消息。
Kafka安装使用
这里演示在Windows下Kafka安装与使用。Kafka下载地址:http://kafka.apache.org/downloads,选择二进制文件下载(Binary downloads),然后解压即可。
Kafka的配置文件位于config目录下,因为Kafka集成了Zookeeper(Kafka存储消息的地方),所以config目录下除了有Kafka的配置文件server.properties外,还可以看到一个Zookeeper配置文件zookeeper.properties:
打开server.properties,将broker.id的值修改为1,每个broker的id都必须设置为Integer类型,且不能重复。Zookeeper的配置保持默认即可。
接下来开始使用Kafka。
启动Zookeeper
在Windows下执行下面这些命令可能会出现找不到或无法加载主类的问题,解决方案可参考:https://blog.csdn.net/cx2932350/article/details/78870135。
在Kafka根目录下使用cmd执行下面这条命令,启动ZK:
1 | bin\windows\zookeeper-server-start.bat config\zookeeper.properties |
在Linux下,可以使用后台进程的方式启动ZK:
1 | bin/zookeeper-server-start.sh -daemon config/zookeeper.properties |
启动Kafka
执行下面这条命令启动Kafka:
1 | bin\windows\kafka-server-start.bat config\server.properties |
Linux对应命令:
1 | bin/kafka-server-start.sh config/server.properties |
当看到命令行打印如下信息,说明启动完毕:

创建Topic
执行下面这条命令创建一个Topic
1 | bin\windows\kafka-topics.bat --create --zookeeper localhost:2181 --replication-factor 1 --partitions 1 --topic test |
这条命令的意思是,创建一个Topic到ZK(指定ZK的地址),副本个数为1,分区数为1,Topic的名称为test。
Linux对应的命令为:
1 | bin/kafka-topics.sh --create --zookeeper localhost:2181 --replication-factor 1 --partitions 1 --topic test |
创建好后我们可以查看Kafka里的Topic列表:
1 | bin\windows\kafka-topics.bat --list --zookeeper localhost:2181 |

可看到目前只包含一个我们刚创建的test Topic。
Linux对应的命令为:
1 | bin/kafka-topics.sh --list --zookeeper localhost:2181 |
查看test Topic的具体信息:
1 | bin\windows\kafka-topics.bat --describe --zookeeper localhost:2181 --topic test |

Linux对应的命令为:
1 | bin/kafka-topics.sh --describe --zookeeper localhost:2181 --topic test |
生产消息和消费消息
启动Producers
1 | bin\windows\kafka-console-producer.bat --broker-list localhost:9092 --topic test |
9092为生产者的默认端口号。这里启动了生产者,准备往test Topic里发送数据。
Linux下对应的命令为:
1 | bin/kafka-console-producer.sh --broker-list localhost:9092 --topic test |
启动Consumers
接着启动一个消费者用于消费生产者生产的数据,新建一个cmd窗口,输入下面这条命令:
1 | bin\windows\kafka-console-consumer.bat --bootstrap-server localhost:9092 --topic test --from-beginning |
from-beginning表示从头开始读取数据。
Linux下对应的命令为:
1 | bin/kafka-console-consumer.sh --bootstrap-server localhost:9092 --topic test --from-beginning |
启动好生产者和消费者后我们在生产者里生产几条数据:

消费者成功接收到数据:

Spring Boot整合Kafaka
上面简单介绍了Kafka的使用,下面我们开始在Spring Boot里使用Kafka。
新建一个Spring Boot项目,版本为2.1.3.RELEASE,并引入如下依赖:
1 | <dependency> |
生产者配置
新建一个Java配置类KafkaProducerConfig,用于配置生产者:
1 |
|
首先我们配置了一个producerFactory,方法里配置了Kafka Producer实例的策略。bootstrapServers为Kafka生产者的地址,我们在配置文件application.yml里配置它:
1 | spring: |
ProducerConfig.KEY_SERIALIZER_CLASS_CONFIG和ProducerConfig.VALUE_SERIALIZER_CLASS_CONFIG指定了key,value序列化策略,这里指定为Kafka提供的StringSerializer,因为我们暂时只发送简单的String类型的消息。
接着我们使用producerFactory配置了kafkaTemplate,其包含了发送消息的便捷方法,后面我们就用这个对象来发送消息。
发布消息
配置好生产者,我们就可以开始发布消息了。
新建一个SendMessageController:
1 |
|
我们注入了kafkaTemplate对象,key-value都为String类型,并通过它的send方法来发送消息。其中test为Topic的名称,上面我们已经使用命令创建过这个Topic了。
send方法是一个异步方法,我们可以通过回调的方式来确定消息是否发送成功,我们改造SendMessageController:
1 |
|
消息发送成功后,会回调onSuccess方法,发送失败后回调onFailure方法。
消费者配置
接着我们来配置消费者,新建一个Java配置类KafkaConsumerConfig:
1 |
|
consumerGroupId和autoOffsetReset需要在application.yml里配置:
1 | spring: |
其中group-id将消费者进行分组(你也可以不进行分组),组名为test-consumer,并指定了消息读取策略,包含四个可选值:

earliest:当各分区下有已提交的offset时,从提交的offset开始消费;无提交的offset时,从头开始消费
latest:当各分区下有已提交的offset时,从提交的offset开始消费;无提交的offset时,消费新产生的该分区下的数据
none:topic各分区都存在已提交的offset时,从offset后开始消费;只要有一个分区不存在已提交的offset,则抛出异常
exception:直接抛出异常
在KafkaConsumerConfig中我们配置了ConsumerFactory和KafkaListenerContainerFactory。当这两个Bean成功注册到Spring IOC容器中后,我们便可以使用@KafkaListener注解来监听消息了。
配置类上需要@EnableKafka注释才能在Spring托管Bean上检测@KafkaListener注解。
消息消费
配置好消费者,我们就可以开始消费消息了,新建KafkaMessageListener:
1 |
|
我们通过@KafkaListener注解来监听名称为test的Topic,消费者分组的组名为test-consumer。
演示
启动Spring Boot项目,启动过程中,控制台会输出Kafka的配置,启动好后,访问http://localhost:8080/send/hello,mrbird,控制台输出如下:

@KafkaListener详解
@KafkaListener除了可以指定Topic名称和分组id外,我们还可以同时监听来自多个Topic的消息:
1 | (topics = "topic1, topic2") |
我们还可以通过@Header注解来获取当前消息来自哪个分区(partitions):
1 | (topics = "test", groupId = "test-consumer") |
重启项目,再次访问http://localhost:8080/send/hello,mrbird,控制台输出如下:

因为我们没有进行分区,所以test Topic只有一个区,下标为0。
我们可以通过@KafkaListener来指定只接收来自特定分区的消息:
1 | (groupId = "test-consumer", |
如果不需要指定initialOffset,上面代码可以简化为:
1 | (groupId = "test-consumer", |
消息过滤器
我们可以为消息监听添加过滤器来过滤一些特定的信息。我们在消费者配置类KafkaConsumerConfig的kafkaListenerContainerFactory方法里配置过滤规则:
1 |
|
setRecordFilterStrategy接收RecordFilterStrategy<K, V>,他是一个函数式接口:
1 | public interface RecordFilterStrategy<K, V> { |
所以我们用lambda表达式指定了上面这条规则,即如果消息内容包含fuck这个粗鄙之语的时候,则不接受消息。
配置好后我们重启项目,分别发送下面这两条请求:
观察控制台:

可以看到,fuck,mrbird这条消息没有被接收。
发送复杂的消息
截至目前位置我们只发送了简单的字符串类型的消息,我们可以自定义消息转换器来发送复杂的消息。
定义消息实体
创建一个Message类:
1 | public class Message implements Serializable { |
改造消息生产者配置
1 |
|
我们将value序列化策略指定为了Kafka提供的JsonSerializer,并且kafkaTemplate返回类型为KafkaTemplate<String, Message>。
发送新的消息
在SendMessageController里发送复杂的消息:
1 |
|
修改消费者配置
修改消费者配置KafkaConsumerConfig:
1 |
|
修改消息监听
修改KafkaMessageListener:
1 | (topics = "test", groupId = "test-consumer") |
重启项目,访问http://localhost:8080/send/hello,控制台输出如下:

更多配置
1 | spring.kafka.admin.client-id= # ID to pass to the server when making requests. Used for server-side logging. |
源码链接:https://github.com/wuyouzhuguli/SpringAll/tree/master/54.Spring-Boot-Kafka

