Kafka中消息是以topic进行分类的,生产者生产消息,消费者消费消息,都是面向topic。topic是逻辑上的概念,而partition是物理上的概念,每个partition对应于一个log文件,该log文件中存储的就是producer生产的数据。Producer生产的数据会被不断追加到该log文件末端,且每条数据都有自己的offset。消费者组中的每个消费者,都会实时记录自己消费到了哪个offset,以便出错恢复时,从上次的位置继续消费。
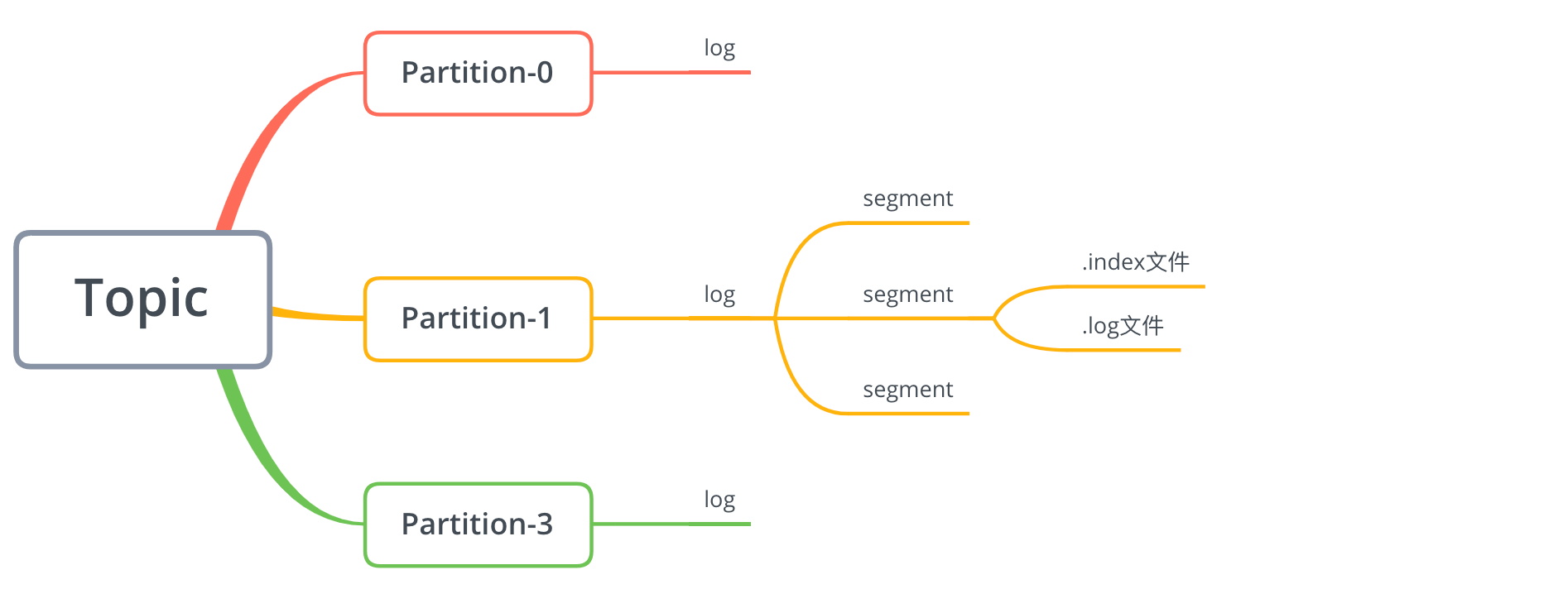
topic构成
在Kafka中,一个topic可以分为多个partition,一个partition分为多个segment,每个segment对应两个文件:.index和.log文件:
消息存储原理
由于生产者生产的消息会不断追加到log文件末尾,为防止log文件过大导致数据定位效率低下,Kafka采取了分片和索引机制,将每个partition分为多个segment。如前面所说,每个segment对应.index文件和.log文件。这些文件位于一个以特定规则命名的文件夹下,该文件夹的命名 规则为:topic 名称 + 分区序号。
例如,我们在上一节创建了一个名称为test的topic,该topic只有一个分区,所以在Kafka日会志目录下会有个名为test-0的文件夹:

这些文件的含义如下:
| 类别 | 作用 |
|---|---|
| .index | 偏移量索引文件,存储数据对应的偏移量 |
| .timestamp | 时间戳索引文件 |
| .log | 日志文件,存储生产者生产的数据 |
| .snaphot | 快照文件 |
| Leader-epoch-checkpoint | 保存了每一任leader开始写入消息时的offset,会定时更新。 follower被选为leader时会根据这个确定哪些消息可用 |
index和log文件以当前segment的第一条消息的偏移量offset命名。偏移量offset是一个64位的长整形数,固定是20位数字,长度未达到,用0进行填补,索引文件和日志文件都由该作为文件名命名规则。所以从上图可以看出,我们的偏移量是从0开始的,.index和.log文件名称都为00000000000000000000。
上节中,我们通过生产者发送了hello和world两个数据,所以我们可以查看下.log文件下是否有这两条数据:
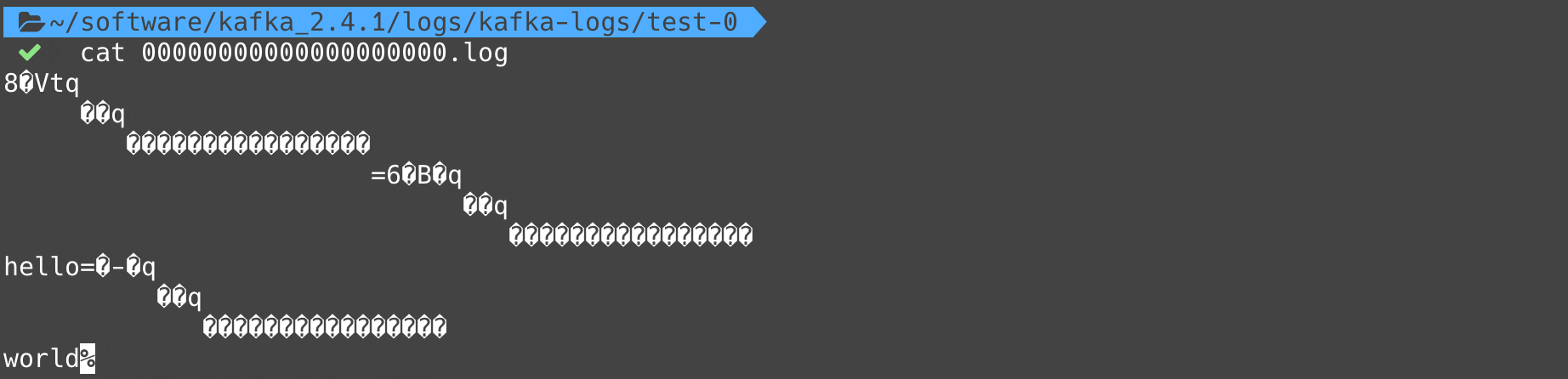
内容存在一些”乱码“,因为数据是经过序列化压缩的。
那么数据文件.log大小有限制吗,能保存多久时间?这些我们都可以通过Kafka目录下conf/server.properties配置文件修改:
1 | # log文件存储时间,单位为小时,这里设置为1周 |
比如,当生产者生产数据量较多,一个segment存储不下触发分片时,在日志topic目录下你会看到类似如下所示的文件:
1 | 00000000000000000000.index |
下图展示了Kafka查找数据的过程:
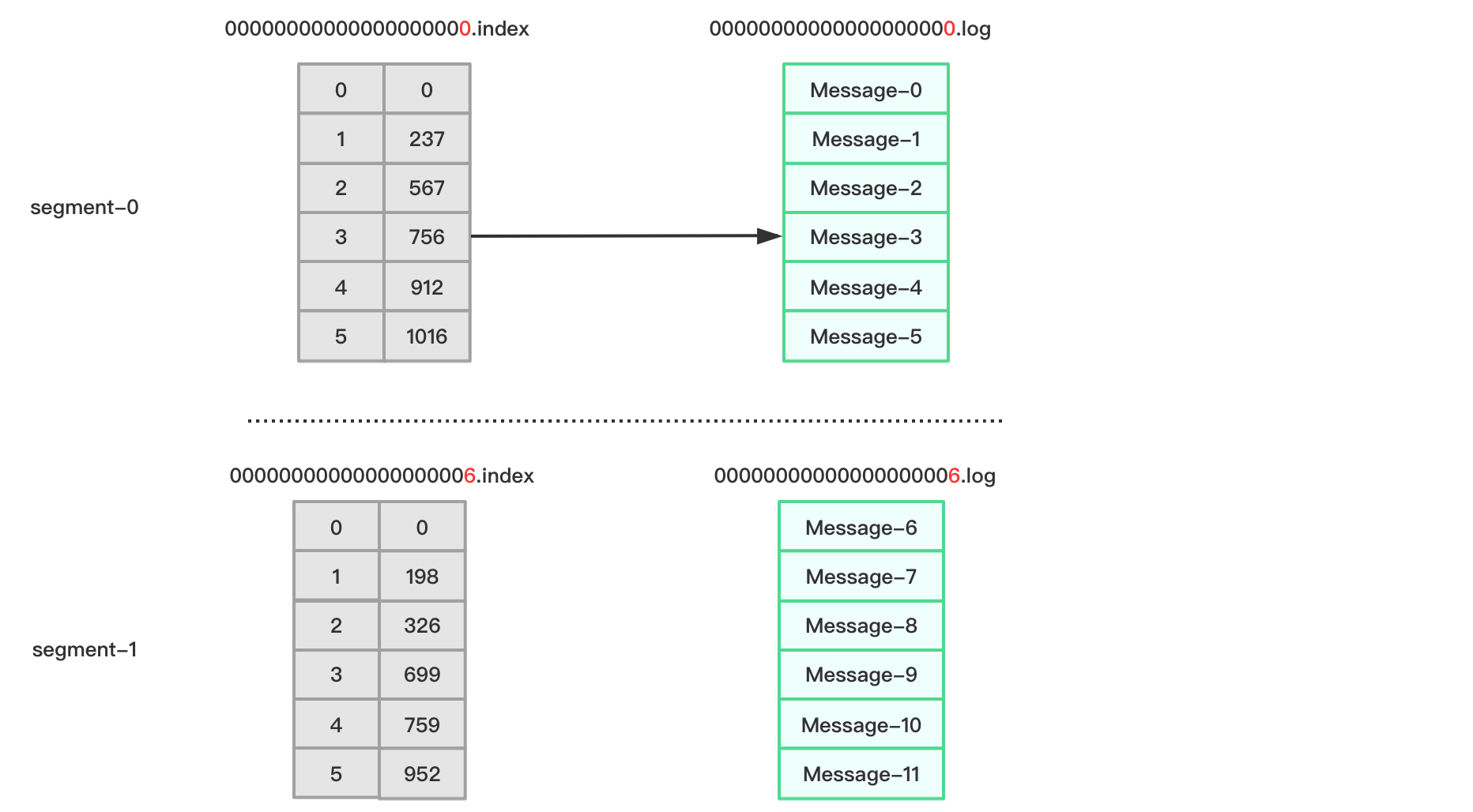
比如现在要查找偏移量offset为3的消息,根据.index文件命名我们可以知道,offset为3的索引应该从00000000000000000000.index里查找。根据上图所示,其对应的索引地址为756~911,所以Kafka将读取00000000000000000000.log 756~911区间的数据。
「尚硅谷大数据技术之 Kafka」 学习笔记

