创建型模式
简单工厂模式
简单工厂模式严格意义上来说,并不属于设计模式中的一种,不过这里还是简单记录下。
定义:由一个工厂对象决定创建出哪一种类型实例。客户端只需传入工厂类的参数,无心关心创建过程。
优点:具体产品从客户端代码中抽离出来,解耦。
缺点:工厂类职责过重,增加新的类型时,得修改工程类得代码,违背开闭原则。
举例:新建Fruit水果抽象类,包含eat抽象方法:
1 | public abstract class Fruit { |
其实现类Apple:
1 | public class Apple extends Fruit{ |
新建创建Fruit的工厂类:
1 | public class FruitFactory { |
新建个客户端测试一下:
1 | public class Application { |
运行main方法,输出:
1 | 吃🍎 |
可以看到,客户端Application并未依赖具体的水果类型,只关心FruitFactory的入参,这就是客户端和具体产品解耦的体现,UML图如下:
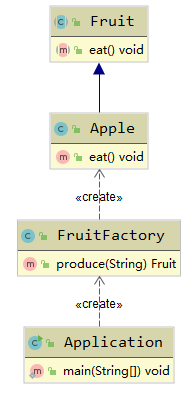
工厂方法模式
为了解决简单工厂模式的缺点,诞生了工厂方法模式(Factory method pattern)。
定义:定义创建对象的接口,让实现这个接口的类来决定实例化哪个类,工厂方法让类的实例化推迟到了子类进行。
优点:
具体产品从客户端代码中抽离出来,解耦。
加入新的类型时,只需添加新的工厂方法(无需修改旧的工厂方法代码),符合开闭原则。
缺点:类的个数容易过多,增加复杂度。
举例:新建Fruit抽象类,包含eat抽象方法:
1 | public abstract class Fruit { |
新建FruitFactory抽象工厂,定义produceFruit抽象方法:
1 | public abstract class FruitFactory { |
新建Fruit的实现类,Apple:
1 | public class Apple extends Fruit { |
新建FruitFactory的实现类AppleFruitFactory,用于生产具体类型的水果 —— 苹果:
1 | public class AppleFruitFactory extends FruitFactory{ |
新建客户端Application测试一波:
1 | public class Application { |
运行main方法,输出如下:
1 | 吃🍎 |
现在要新增Banana类型的水果,只需要新增Banana类型的工厂类即可,无需修改现有的AppleFruitFactory代码,符合开闭原则。但是这种模式的缺点也显而易见,就是类的个数容易过多,增加复杂度。
上面例子UML图如下所示:
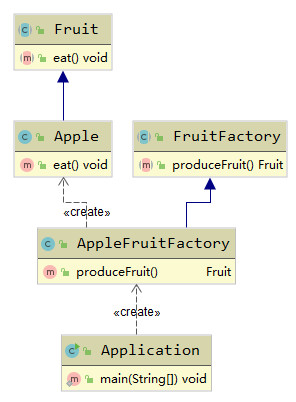
抽象工厂模式
抽象工厂模式(Abstract factory pattern)提供了一系列相关或者相互依赖的对象的接口,关键字是“一系列”。
优点:
具体产品从客户端代码中抽离出来,解耦。
将一个系列的产品族统一到一起创建。
缺点:拓展新的功能困难,需要修改抽象工厂的接口;
综上所述,抽象工厂模式适合那些功能相对固定的产品族的创建。
举例:新建水果抽象类Fruit,包含buy抽象方法:
1 | public abstract class Fruit { |
新建价格抽象类Price,包含pay抽象方法:
1 | public abstract class Price { |
新建水果创建工厂接口FruitFactory,包含获取水果和价格抽象方法(产品族的体现是,一组产品包含水果和对应的价格):
1 | public interface FruitFactory { |
接下来开始创建🍎这个“产品族”。新建Fruit实现类AppleFruit:
1 | public class AppleFruit extends Fruit{ |
新建对应的苹果价格实现ApplePrice:
1 | public class ApplePrice extends Price{ |
创建客户端Application,测试一波:
1 | public class Application { |
输出如下:
1 | 购买🍎 |
客户端只需要通过创建AppleFruitFactory就可以获得苹果这个产品族的所有内容,包括苹果对象,苹果价格。要新建🍌的产品族,只需要实现FruitFactory、Price和Fruit接口即可。这种模式的缺点和工厂方法差不多,就是类的个数容易过多,增加复杂度。
上面例子UML图如下所示:
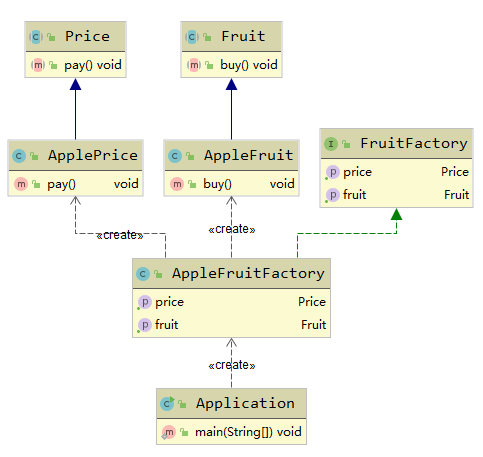
建造者模式
建造者模式也称为生成器模式(Builder Pattern),将复杂对象的建造过程抽象出来(抽象类别),使这个抽象过程的不同实现方法可以构造出不同表现(属性)的对象。简单来说就是,相同的过程可以创建不同的产品。
将复杂对象的建造过程抽象出来(抽象类别),使这个抽象过程的不同实现方法可以构造出不同表现(属性)的对象。
简单来说就是,相同的过程可以创建不同的产品。
适用于:
- 一个对象有非常复杂的内部结构(很多属性)
- 想将复杂对象的创建和使用分离。
优点:
- 封装性好,创建和使用分离
- 拓展性好,建造类之间独立,一定程度上解耦。
缺点:
- 产生多余的Builder对象;
- 产品内部发生变化,建造者需要更改,成本较大。
举个例子:
新增商铺类Shop,包含名称,地点和类型属性:
1 | public class Shop { |
接着创建Shop抽象生成器ShopBuilder:
1 | public abstract class ShopBuilder { |
包含和Shop相同的属性及对应的抽象构建方法。
继续创建ShopBuilder的实现,水果店构造器FruitShopBuilder:
1 | public class FruitShopBuilder extends ShopBuilder{ |
创建个经销商类Dealer,用于通过ShopBuilder构建具体的商店:
1 | public class Dealer { |
创建个客户端Application测试一波:
1 | public class Application { |
输出如下:
1 | Shop{name='XX水果店', location='福州市XX区XX街XX号', type='水果经营'} |
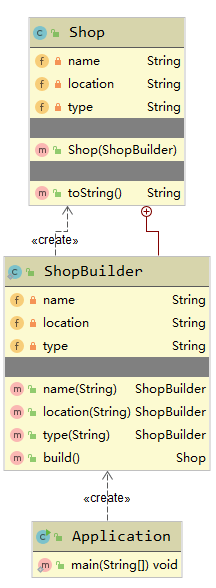
这个例子是典型的建造者模式,UML图如下所示:
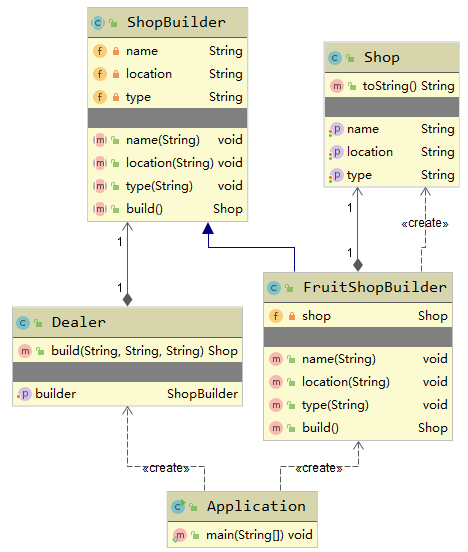
其实建造者模式更为常用的例子是下面这个:
创建一个店铺类Shop,Shop里包含构造该Shop的内部类:
1 | public class Shop { |
在客户端构建Shop只需:
1 | public class Application { |
这种用法和Lombok的@Builder注解效果是一样的。
这个例子的UML图:
单例模式
单例模式目的是为了一个类只有一个实例。
优点:
- 内存中只有一个实例,减少了内存开销;
- 可以避免对资源的多重占用;
- 设置全局访问点,严格控制访问。
缺点:
- 没有接口,拓展困难。
懒汉模式
懒汉模式下的单例写法是最简单的,但它是线程不安全的:
1 | public class LazySingleton { |
可加同步锁解决线程安全问题:
1 | public class LazySingleton { |
但是同步锁锁的是整个类,比较消耗资源,并且即使运行内存中已经存在LazySingleton,调用其getInstance还是会上锁,所以这种写法也不是很好。
双重同步锁单例模式
1 | public class LazyDoubleCheckSingleton { |
上面例子虽然加了同步锁,但它还是线程不安全的。虽然上面的例子不会出现多次初始化LazyDoubleCheckSingleton实例的情况,但是由于指令重排的原因,某些线程可能会获取到空对象,后续对该对象的操作将触发空指针异常。
要修复这个问题,只需要阻止指令重排即可,所以可以给instance属性加上volatile关键字:
1 | public class LazyDoubleCheckSingleton { |
相关博文:深入理解volatile关键字。
上面这种写法是不但确保了线程安全,并且当LazyDoubleCheckSingleton实例创建好后,后续再调用其getInstance方法不会上锁。
静态内部类单例模式
看例子:
1 | public class StaticInnerClassSingleton { |
为什么这个例子是可行的呢?主要有两个原因:
- JVM在类的初始化阶段会加Class对象初始化同步锁,同步多个线程对该类的初始化操作;
- 静态内部类InnerClass的静态成员变量instance在方法区中只会有一个实例。
在Java规范中,当以下这些情况首次发生时,A类将会立刻被初始化:
- A类型实例被创建;
- A类中声明的静态方法被调用;
- A类中的静态成员变量被赋值;
- A类中的静态成员被使用(非常量);
饿汉单例模式
“饿汉”意指在类加载的时候就初始化:
1 | public class HungrySingleton { |
这种模式在类加载的时候就完成了初始化,所以并不存在线程安全性问题;但由于不是懒加载,饿汉模式不管需不需要用到实例都要去创建实例,如果创建了不使用,则会造成内存浪费。
序列化破坏单例模式
前面的单例例子在实现序列化接口后都能被序列化的方式破坏,比如HungrySingleton,让其实现序列化接口:
1 | public class HungrySingleton implements Serializable { |
然后创建Application测试一下如何破坏:
1 | public class Application { |
输出如下所示:
1 | cc.mrbird.design.pattern.creational.singleton.HungrySingleton@7f31245a |
可以看到,虽然是单例模式,但却成功创建出了两个不一样的实例,单例遭到了破坏。
要让反序列化后的对象和序列化前的对象是同一个对象的话,可以在HungrySingleton里加上readResolve方法:
1 | public class HungrySingleton implements Serializable { |
再次运行Application的main方法后:
1 | cc.mrbird.design.pattern.creational.singleton.HungrySingleton@7f31245a |
可以看到,这种方式最终反序列化出来的对象和序列化对象是同一个对象。但这种方式反序列化过程内部还是会重新创建HungrySingleton实例,只不过因为HungrySingleton类定义了readResolve方法(方法内部返回instance引用),反序列化过程会判断目标类是否定义了readResolve该方法,是的话则通过反射调用该方法。
反射破坏单例模式
除了序列化能破坏单例外,反射也可以,举个反射破坏HungrySingleton的例子:
1 | public class Application { |
输出如下所示:
1 | cc.mrbird.design.pattern.creational.singleton.HungrySingleton@1b6d3586 |
可以看到,我们通过反射破坏了私有构造器权限,成功创建了新的实例。
对于这种情况,饿汉模式下的例子可以在构造器中添加判断逻辑来防御(懒汉模式的就没有办法了),比如修改HungrySingleton的代码如下所示:
1 | public class HungrySingleton { |
再次运行Application的main方法:
1 | Exception in thread "main" java.lang.reflect.InvocationTargetException |
枚举单例模式
枚举单例模式是推荐的单例模式,它不仅可以防御序列化攻击,也可以防御反射攻击。举个枚举单例模式的代码:
1 | public enum EnumSingleton { |
验证下是否是单例的:
1 | public class Application { |
输出如下所示:
1 | INSTANCE |
测试下序列化攻击:
1 | public class Application { |
输出如下所示:
1 | INSTANCE |
可以看到序列化和反序列化后的对象是同一个。
原理:跟踪ObjectInputStream#readObject源码,其中当反编译对象为枚举类型时,将调用readEnum方法:

name为枚举类里的枚举常量,对于线程来说它是唯一的,存在方法区,所以通过Enum.valueOf((Class)cl, name)方法得到的枚举对象都是同一个。
再测试一下反射攻击:
1 | public class Application { |
运行输出如下:
1 | Exception in thread "main" java.lang.IllegalArgumentException: Cannot reflectively create enum objects |
可以看到抛异常了,查看Constructor类的417行代码可以发现原因: 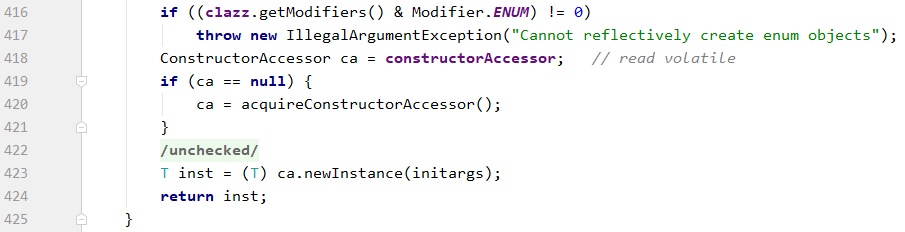
Java禁止通过反射创建枚举对象。
正是因为枚举类型拥有这些天然的优势,所以用它创建单例是不错的选择,这也是Effective Java推荐的方式。
原型模式
原型实例指定创建对象的种类,通过拷贝这些原型创建新的对象。
适用于:
- 类初始化消耗较多资源;
- 循环体中生产大量对象的时候。
优点:
- 原型模式性能比直接new一个对象性能好;
- 简化创建对象过程。
缺点:
- 对象必须重写Object克隆方法;
- 复杂对象的克隆方法写起来较麻烦(深克隆、浅克隆)
举例:新建一个学生类Student,实现克隆接口,并重写Object的克隆方法(因为都是简单属性,所以浅克隆即可):
1 | public class Student implements Cloneable { |
在Application中测试一波:
1 | public class Application { |
输出如下所示:
1 | [Student{name='学生0', age=20}, Student{name='学生1', age=21}, Student{name='学生2', age=22}] |
这种方式会比直接在循环中创建Student性能好。
当对象包含引用类型属性时,需要使用深克隆,比如Student包含Date属性时:
1 | public class Student implements Cloneable { |
值得注意的是,克隆会破坏实现了Cloneable接口的单例对象。
结构型模式
外观模式
外观模式又叫门面模式,提供了统一得接口,用来访问子系统中的一群接口。
适用于:
- 子系统越来越复杂,增加外观模式提供简单接口调用;
- 构建多层系统结构,利用外观对象作为每层的入口,简化层间调用。
优点:
- 简化了调用过程,无需了解深入子系统;
- 减低耦合度;
- 更好的层次划分;
- 符合迪米特法则。
缺点:
- 增加子系统,拓展子系统行为容易引入风险;
- 不符合开闭原则。
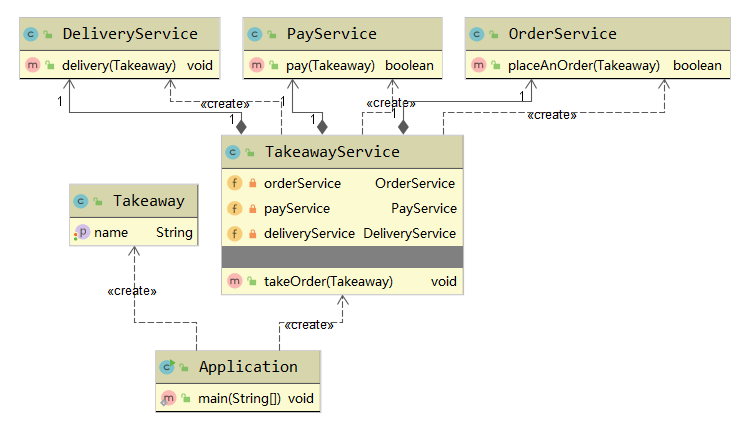
举个订外卖的例子。
创建一个外卖实体类Takeaway:
1 | public class Takeaway { |
订外卖过程一般分为三个步骤:下单、支付和配送,所以我们创建三个Service对应这三个过程。新建下单服务OrderService:
1 | public class OrderService { |
新建支付服务PayService:
1 | public class PayService { |
新建配送服务DeliveryService:
1 | public class DeliveryService { |
基于外观模式法则,我们需要创建一个Service来聚合这三个服务,客户端只需要和这个Service交互即可。新建外卖服务TakeawayService:
1 | public class TakeawayService { |
新建个客户端测试一波:
1 | public class Application { |
可以看到,客户端只需要调用TakeawayService即可,无需关系内部具体经历了多少个步骤,运行main方法输出如下:
1 | 泡椒🐸下单成功 |
该例子的UML图如下所示:
装饰者模式
在不改变原有对象的基础之上,将功能附加到对象上,提供了比继承更有弹性的替代方案。
适用于:
- 拓展一个类的功能;
- 动态给对象添加功能,并且动态撤销。
优点:
- 继承的有力补充,不改变原有对象的情况下给对象拓展功能;
- 通过使用不同的装饰类、不同的组合方式,实现不同的效果。
- 符合开闭原则。
缺点:
- 增加程序复杂性;
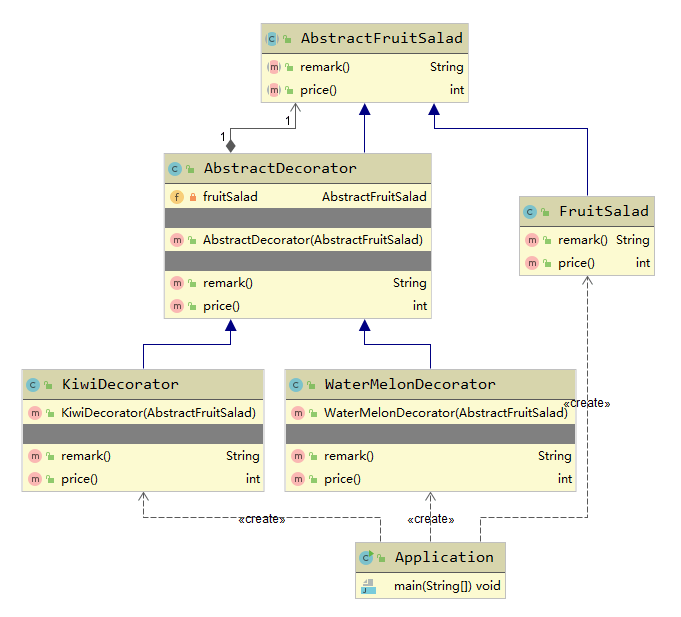
举个水果沙拉的例子。
比如在点水果沙拉外卖时,可以往水果沙拉里加各种水果,价格也会相应的调整,要让程序支持不同水果自由组合,并计算相应的价格,则可以使用装饰者模式来完成。
定义一个抽象的水果沙拉类AbstractFruitSalad:
1 | public abstract class AbstractFruitSalad { |
包含备注和价格抽象方法。
接着创建一个抽象的装饰器AbstractDecorator(关键点,继承抽象水果沙拉类):
1 | public class AbstractDecorator extends AbstractFruitSalad{ |
创建具体的水果沙拉类FruitSalad:
1 | public class FruitSalad extends AbstractFruitSalad{ |
该沙拉是标准的水果沙拉,价格是9元。
如果我们的水果沙拉还允许客户添加猕猴桃和西瓜,那么我们可以添加两个新的装饰器。添加猕猴桃装饰器KiwiDecorator:
1 | public class KiwiDecorator extends AbstractDecorator { |
可以看到,加一份猕猴桃需要在原有基础上加2元。
接着继续创建西瓜装饰器WaterMelonDecorator:
1 | public class WaterMelonDecorator extends AbstractDecorator { |
最后创建客户端Application测试一下:
1 | public class Application { |
上面的写法也可以改为:
1 | public class Application { |
程序输出如下:
1 | 水果🥗(标准) |
通过不同的装饰器自由组合,我们可以灵活的组装出各式各样的水果沙拉,这正是装饰者模式的优点,但明显可以看出代码变复杂了。
这个例子的UML图如下所示:
适配器模式
将一个类的接口转换为期望的另一个接口,使原本不兼容的类可以一起工作。
适用于:
- 已存在的类,它的方法和需求不匹配时(方法结果相同或者相似)
优点:
- 提高类的透明性和复用,现有的类复用但不需改变;
- 目标类和适配器类解耦,提高程序拓展性;
- 符合开闭原则。
缺点:
- 适配器编写过程需要全面考虑,可能会增加系统的复杂性;
- 降低代码可读性。
分为:类适配器模式和对象适配器模式。
先举个类适配器模式的例子:
假如项目里原有一条水果的产品线,比如包含一个树莓类Raspberry:
1 | public class Raspberry { |
随着项目的拓展,现在新增了水果派产品线,新建Pie接口:
1 | public interface Pie { |
要将Raspberry加入到Pie产品线,又不想修改Raspberry类的代码,则可以创建一个适配器RaspberryPieAdaptor:
1 | public class RaspberryPieAdaptor extends Raspberry implements Pie{ |
适配器继承被适配的类,实现新的产品线接口。
在Application里测试一波:
1 | public class Application { |
输出:
1 | 制作一个派🥧 |
成功通过适配器制造了树莓派。类适配器模式的UML图很简单:
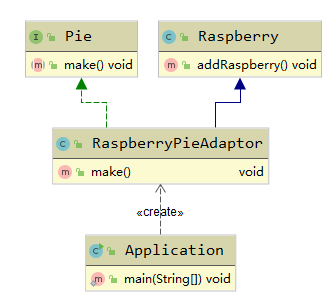
对象适配器模式只需要将RaspberryPieAdaptor修改为:
1 | public class RaspberryPieAdaptor implements Pie{ |
这种模式不直接继承被适配者,而是在适配器里创建被适配者。这种模式的UML图:
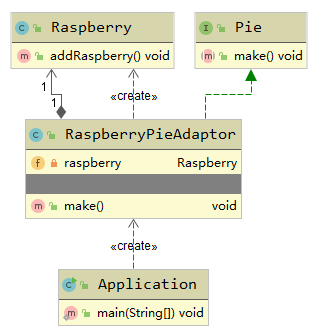
享元模式
提供了减少对象数量从而改善应用所需的对象结构的方式,运用共享技术有效地支持大量细粒度的对象。
适用于:
- 底层系统开发,解决性能问题;
- 系统拥有大量相似对象,需要缓冲池的场景。
优点:
- 减少对象的创建,降低内存占用;
缺点:
- 关注内/外部状态,关注线程安全问题;
- 程序的逻辑复杂化。
内部状态:简单理解为享元对象的属性状态,不会因为外部的改变而改变; 外部状态:简单理解为方法参数。
举个例子,新建派🥧接口Pie:
1 | public interface Pie { |
其实现类水果派FruitPie:
1 | public class FruitPie implements Pie { |
包含名称和生产日期属性,并且有个make方法。
接着创建生产FruitPie的工厂FruitPieFactory:
1 | public class FruitPieFactory { |
代码关键是通过HashMap存储对象。
编写个测试类:
1 | public class Application { |
输出如下所示:
1 | 没有🍓派制作方法,学习制作... |
从结果看,在10次循环中,只生产了4个对象,这很好的描述了系统有大量相似对象,需要缓冲池的场景。
JDK中的字符串常量池,数据库连接池等都是用的享元模式。
组合模式
将对象组合成树形结构以表示“部分-整体”的层次结构,使客户端对单个对象和组合对象保持一致的方式处理。
适用于:
- 客户端可以忽略组合对象与单个对象的差异;
- 处理树形结构数据。
优点:
- 层次清晰;
- 客户端不必关系层次差异,方便控制;
- 符合开闭原则。
缺点:
- 树形处理较为复杂。
举个菜单按钮组成的树形例子。
新建菜单按钮的组合抽象类AbstractMenuButton:
1 | public abstract class AbstractMenuButton { |
组合了菜单按钮操作的基本方法。
新增按钮类Button:
1 | public class Button extends AbstractMenuButton { |
按钮拥有名称属性,并且支持名称获取,类型获取和打印方法,所以重写了这三个父类方法。
接着新建菜单类Menu:
1 | public class Menu extends AbstractMenuButton { |
菜单包含名称、图标和层级属性,并且菜单可以包含下级(比如下级菜单,下级按钮),所以它包含一个List
此外,菜单包含添加下级、名称获取、类型获取、图标获取和打印方法。
新建一个客户端,测试菜单按钮的层级结构:
1 | public class Application { |
打印输出如下所示:
1 | 🔨系统管理【菜单】 |
UML图如下所示:
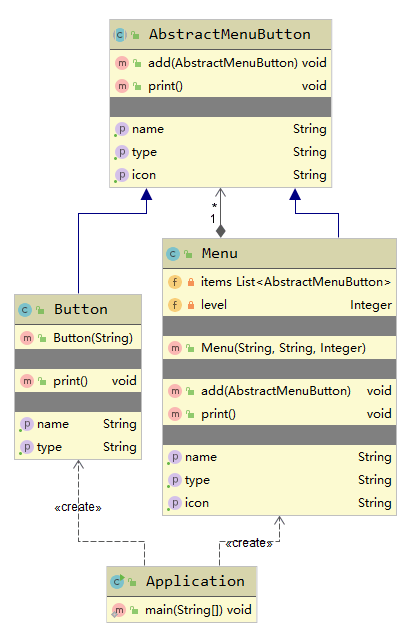
桥接模式
将抽象部分和具体实现部分分离,使它们都可以独立变化。通过组合的方式建立两个类之间的关系,而不是通过继承。
适用于:
- 抽象和实体实现之间增加更多的灵活性;
- 一个类存在多个独立变化的维度,并且需要独立拓展;
- 不希望使用继承。
优点:
- 分离抽象部分和具体实现部分;
- 提高了系统可拓展性;
- 符合开闭原则和合成复用原则。
缺点:
- 增加了系统的理解和设计难度;
举个例子:
现有派的接口类Pie:
1 | public interface Pie { |
包含制作派和获取派类型抽象方法。
接着创建两个Pie的实现类,苹果派AppliePie:
1 | public class ApplePie implements Pie { |
胡萝卜派CarrotPie:
1 | public class CarrotPie implements Pie{ |
接着创建一个店铺抽象类Store,通过属性的方式和Pie相关联,目的是可以在不同的店铺实现类中灵活地制作各种派:
1 | public abstract class Store { |
Store子类之一,山姆大叔的小店SamStore:
1 | public class SamStore extends Store{ |
Store子类之二,杰克的小店JackStore:
1 | public class JackStore extends Store { |
新建一个客户端,测试Pie的实现类和Store的继承类之间的自由组合:
1 | public class Application { |
输出如下:
1 | 山姆大叔的小店💒制作苹果派🍎🥧 |
这个例子很好地体现了桥接模式的特点,UML图如下:
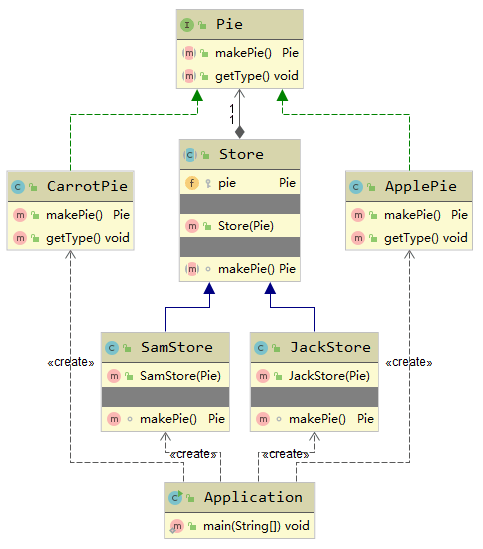
代理模式
为其他对象提供一种代理,以控制对这个对象的访问,代理对象在客户端和目标对象之间起到了中介的作用。
适用于:
- 保护目标对象;
- 增强目标对象。
优点:
- 将代理对象和真实被调用的目标对象分离;
- 降低耦合,拓展性好;
- 保护目标对象,增强目标对象。
缺点:
- 造成类的数目增加,增加复杂度;
- 客户端和目标对象增加代理对象,会造成处理速度变慢。
静态代理
通过在代码中显式地定义了一个代理类,在代理类中通过同名的方法对目标对象的方法进行包装,客户端通过调用代理类的方法来调用目标对象的方法。
举个静态代理的例子:
新建一个派的制作接口PieService:
1 | public interface PieServcie { |
创建其实现类PieServiceImpl:
1 | public class PieServiceImpl implements PieServcie{ |
要对PieServiceImpl的makePie方法增强,我们需要创建一个代理对象PieServiceProxy:
1 | public class PieServiceProxy { |
在PieServiceProxy中我们创建了一个和PieServcie一致的同名方法makePie,方法内部调用了PieServiceImpl的makePie方法,并且在方法调用前调用了代理类的beforeMethod方法,方法调用后调用了代理类的afterMethod方法。
创建客户端Application,测试:
1 | public class Application { |
输出:
1 | 准备材料 |
这个例子的UML图如下:

动态代理
JDK的动态代理只能代理接口,通过接口的方法名在动态生成的代理类中调用业务实现类的同名方法。
静态代理的缺点就是每需要代理一个类,就需要手写对应的代理类。这个问题可以用动态代理来解决。举个动态代理的例子:
新建冰淇淋制作接口IceCreamService:
1 | public interface IceCreamService { |
实现类IceCreamServiceImpl:
1 | public class IceCreamServiceImpl implements IceCreamService { |
现在需要对IceCreamServiceImpl进行代理增强,如果使用静态代理,我们需要编写一个IceCreamServiceImplProxy类,使用动态代理的话,我们可以动态生成对应的代理类。
创建DynamicProxy:
1 | public class DynamicProxy implements InvocationHandler { |
动态代理类通过实现InvocationHandler的invoke方法实现,proxy用于生成代理对象。剩下的步骤和静态代理类似,完善DynamicProxy:
1 | public class DynamicProxy implements InvocationHandler { |
创建客户端Application测试:
1 | public class Application { |
结果:
1 | 准备派的材料 |
可以看到,通过动态代理我们实现了目标方法增强,并且不需要手写目标类的代理对象。
CGLib代理
通过继承来实现,生成的代理类就是目标对象类的子类,通过重写业务方法来实现代理。
Spring对代理模式的拓展
- 当Bean有实现接口时,使用JDK动态代理;
- 当Bean没有实现接口时,使用CGLib代理。
可以通过以下配置强制使用CGLib代理:
1 | spring: |
行为型模式
模板方法模式
模板方法模式定义了一个流程的骨架,由多个方法组成。并允许子类为一个或多个步骤提供实现。简而言之就是公共的不变的部分由父类统一实现,变化的部分由子类来个性化实现。
优点:
- 提高复用性;
- 提高拓展性;
- 符合开闭原则。
缺点:
- 类的数目增加;
- 增加了系统实现的复杂度;
- 父类添加新的抽象方法,所有子类都要改一遍。
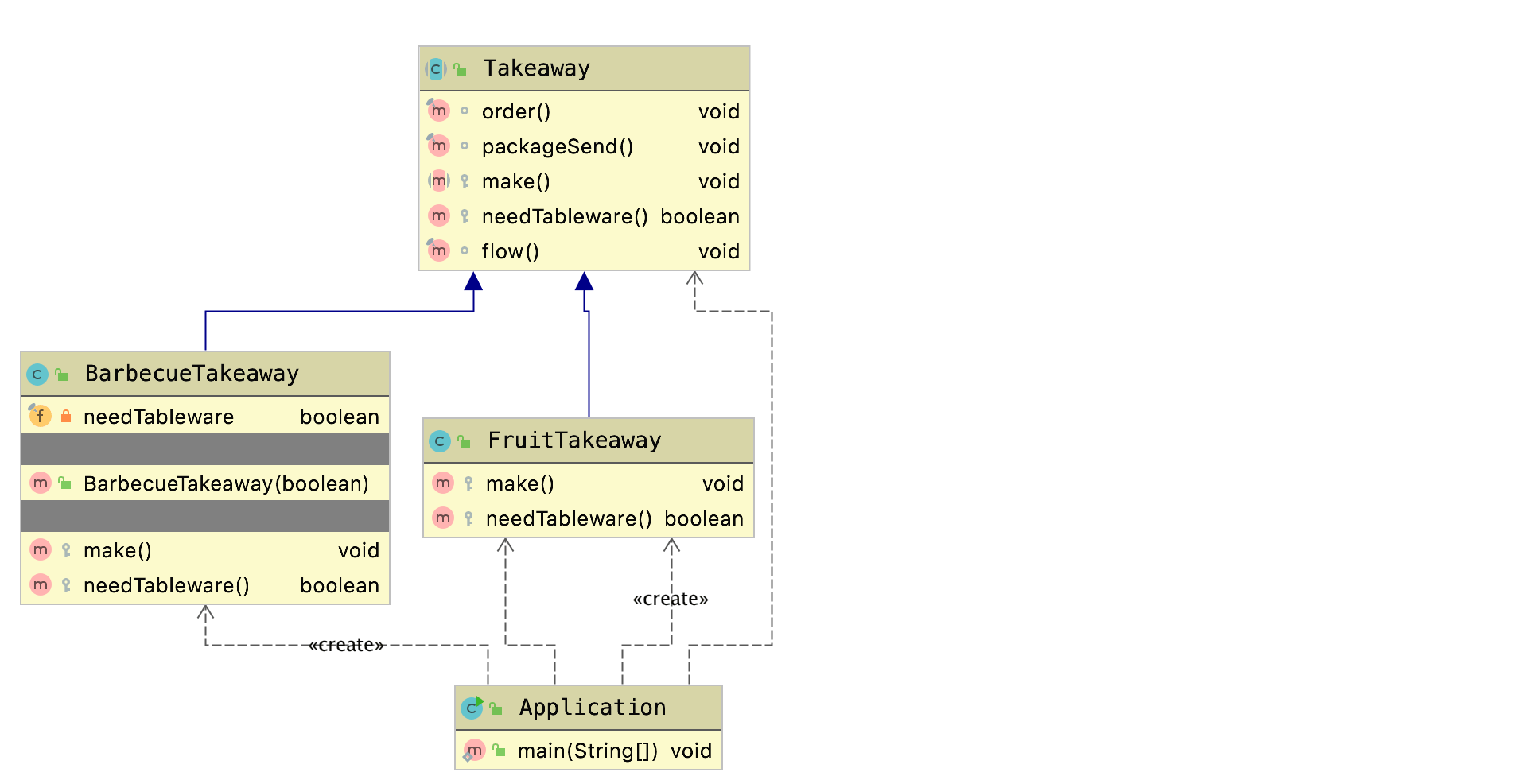
举个模板方法模式的例子。定义一个外卖的接口,包含下单、制作和打包配送三个步骤:
1 | public abstract class Takeaway { |
其中下单和打包配送行为是固定的,不同的是制作过程,所以order和packageSend方法提供了默认实现,并且由final修饰,子类不可重写。此外,我们还可以通过needTableware这个钩子方法来控制某些子类的定制化需求。
新增BarbecueTakeaway继承Takeaway:
1 | public class BarbecueTakeaway extends Takeaway { |
新增FruitTakeaway继承Takeaway:
1 | public class FruitTakeaway extends Takeaway { |
新增个客户端Application测试:
1 | public class Application { |
1 | 下单 |
UML:
迭代器模式
ignore
策略模式
策略模式定义了算法家族,分别封装起来,让它们之间可以互相替换。此模式让算法的变化不会影响到使用算法的用户。策略模式常用于消除大量的if else代码。
适用场景:
- 系统有很多类,它们的区别仅仅在于行为不同;
- 一个系统需要动态地在几种算法中选择一种;
举个策略模式的例子(促销活动),定义一个促销策略接口:
1 | public interface PromotionStrategy { |
实现类之一(策略之一),满减促销策略:
1 | public class FullReductionPromotionStrategy implements PromotionStrategy { |
实现类之一(策略之一),打折促销策略:
1 | public class DiscountPromotionStrategy implements PromotionStrategy { |
创建一个客户端测试:
1 | public class Application { |
输出结果:
1 | 满1000立减1 |
策略模式常结合工厂模式来消除大量的if else代码,我们新建一个促销策略的创建工厂:
1 | public class PromotionStrategyFactory { |
上面代码中,我们通过Map来装载促销策略,这样可以减少对象的重复创建。如果不希望在static块中一次性初始化所有促销策略,我们可以结合享元模式来推迟对象创建过程。
通过这个工厂方法,上面客户端代码可以简写为:
1 | public class Application { |
解释器模式
用的较少,暂不记录。
观察者模式
观察者模式定义了对象之间的一对多依赖,让多个观察者同时监听某个主题对象,当主体对象发生变化时,它的所有观察者都会收到响应的通知。
优点:
- 观察者和被观察者之间建立一个抽象的耦合;
- 观察者模式支持广播通信。
缺点:
- 观察者之间有过多的细节依赖,提高时间消耗及程序复杂度;
- 应避免循环调用。
JDK对观察者模式提供了支持。下面举个观察者模式的例子。
创建一个博客类:
1 | /** |
Comment类代码:
1 | public class Comment { |
Blog类是被观察者对象,被观察者对象需要继承JDK的Observable类,继承后,被观察者对象包含如下属性和方法:

这些方法都是线程安全方法(加了synchronized同步锁)。
Blog的comment方法中,当博客收到评论时,首先调用父类的setChanged()方法,设置标识位 changed = true,表示被观察者发生了改变;然后调用父类的notifyObservers(Object)方法通知所有观察者。
被观察者对象创建好后,我们接着创建观察者。新建一个Author类:
1 | public class Author implements Observer { |
观察者对象需要实现JDK的Observer类,重写update方法。当被观察者对象调用了notifyObservers方法后,相应的观察者的update方法会被调用。
新建一个客户端测试一下:
1 | public class Application { |
程序输出如下:
1 | Scott评论了<Java从入门到放弃> ,评论内容:感谢楼主的文章,让我及时放弃Java,回家继承了千万家产。 |
值得注意的是,观察者的update方法里的逻辑最好进行异步化,这样在并发环境下可以提升程序性能。
备忘录模式
参考:https://www.cnblogs.com/jimoer/p/9537997.html。
命令模式
暂不记录。
中介者模式
暂不记录。
职责链模式
职责链模式为请求创建一个接收此次请求对象的链。
适用于:
- 一个请求的处理需要多个对象当中的一个或几个协作处理;
优点:
- 请求的发送者和接受者(请求的处理)解耦;
- 职责链可以动态的组合。
缺点:
- 职责链太长或者处理时间过长,影响性能;
- 职责链可能过多。
举个字符串校验的例子。新建一个字符串校验抽象类:
1 | public abstract class StringValidator { |
StringValidator类包含了一个自身类型的成员变量,这也是该模式的设计核心,以此形成链条。
创建一个校验字符串长度的类StringLengthValidator:
1 | public class StringLengthValidator extends StringValidator { |
上面代码中,在字符串长度校验合法后,我们判断父类的validator属性是否为空,不为空则调用其check方法继续下一步校验。
接着再新建一个校验字符串内容的类StringValueValidator:
1 | public class StringValueValidator extends StringValidator { |
套路和StringLengthValidator一样。接着创建一个客户端类,演示下如何让校验类形成一个链条:
1 | public class Application { |
上面代码中,通过StringValidator的setNextValidator方法,我们可以指定下一个校验类,以此形成链条,程序输出如下:
1 | 字符串长度合法 |
访问者模式
暂不记录🌚
状态模式
暂不记录🌚
参考连接:https://zh.wikipedia.org/wiki/%E8%AE%BE%E8%AE%A1%E6%A8%A1%E5%BC%8F_(%E8%AE%A1%E7%AE%97%E6%9C%BA)

